Una proteína a lo largo de la página UniProt
| Autores/as |
|
| Traducción |
|
| Revisores/as |
|
Descripción GeneralPreguntas:
Objetivos:
¿Cómo se pueden buscar proteínas utilizando texto, nombres de genes o nombres de proteínas?
¿Cómo se interpreta la información en la parte superior de la página de entrada de UniProt?
¿Qué tipo de información se puede esperar de los distintos formatos de descarga, como FASTA y JSON?
¿Cómo se describe la función de una proteína como las opsinas en la sección “Function”?
¿Qué información estructurada se encuentra en las secciones “Names and Taxonomy”, “Subcellular location”, “Disease & Variants”, “PTM/Processing”?
¿Cómo informarse sobre la expresión, interacciones, estructura, familia, secuencia y proteínas similares?
¿Cómo ayudan las pestañas “Variant viewer” y “Feature viewer” a mapear la información de la proteína a lo largo de su secuencia?
¿Qué muestra la pestaña “Publications” y cómo se pueden filtrar las publicaciones?
¿Cuál es la importancia de hacer un seguimiento de los cambios en la anotación de la entrada a lo largo del tiempo?
Requisitos:
Explorando las entradas de proteínas en UniProtKB, interpreta la función de la proteína, su taxonomía, estructura, interacciones, variantes y más.
Utiliza identificadores únicos para conectar bases de datos, descargar datos de genes y proteínas, visualizar y comparar características de secuencias.
- slides Slides: Learning about one gene across biological resources and formats
- tutorial Hands-on: Learning about one gene across biological resources and formats
Duración estimada: 1 horaNivel: Introductorio IntroductoryMateriales de apoyo:Published: Mar 30, 2026Última modificación: Mar 30, 2026Licencia: El contenido de este tutorial tiene la licencia Creative Commons Attribution 4.0 International License. GTN Framework tiene licencia del MIT MITversion Revision: 1
Al realizar un análisis de datos biológicos, es posible que nos encontremos con algunas proteínas interesantes, que necesitemos explorar estos genes. ¿Pero cómo podemos hacerlo? ¿Cuáles son los recursos disponibles para ello? ¿Y cómo navegar por ellos?
El objetivo de este tutorial es familiarizarnos con ello, utilizando como ejemplo las opsinas humanas.
ComentarioEste tutorial es un poco atípico: no trabajaremos en Galaxy sino principalmente fuera de ella, en las páginas de la base de datos UniProt.
ComentarioEste tutorial está diseñado para ser la continuación del tutorial “Un gen a través de formatos de archivo”, pero también puede ser consultado como un módulo independiente.
Las opsinas se encuentran en las células de la retina. Captan la luz e inician la secuencia de señales que dan lugar a la visión, y esa es la razón por la que, cuando se ven comprometidas, se asocian al daltonismo y a otras deficiencias visuales.
Comentario: Fuentes de información de este tutorialEl tutorial que usted está consultando fue desarrollado principalmente consultando los recursos de UniProtKB, en particular el tutorial Explore UniProtKB entry. Algunas frases se reportan desde allí sin modificaciones.
Además, el tema se eligió basándose en el [Tutorial de Bioinformática] de Gale Rhodes (https://spdbv.unil.ch/TheMolecularLevel/Matics/index.html). Aunque el tutorial ya no se puede seguir paso a paso debido a cómo los recursos mencionados cambiaron con el tiempo, podría proporcionar ideas adicionales sobre las opsinas y, en particular, sobre cómo se pueden construir modelos estructurales de proteínas basados en información evolutiva.
AgendaEn este tutorial trataremos:
La página de entrada de UniProtKB
El portal que hay que visitar para obtener toda la información sobre una proteína es UniProtKB. Podemos buscar en él utilizando una búsqueda de texto, o el nombre del gen o de la proteína. Probemos primero con un conjunto de palabras clave genéricas, como Human opsin.
Práctica: Buscar opsina humana en UniProtKB
- Abrir el UniProtKB
- Escriba
Human opsinen la barra de búsqueda- Lanza la búsqueda
Preguntas¿Cuántos resultados obtuvimos?
410 resultados (en el momento de la preparación de este tutorial)
Estos 410 resultados nos dan la sensación de que tenemos que ser más específicos (aunque - spoiler - nuestro objetivo real está entre los primeros resultados).
Para ser suficientemente específicos, sugerimos utilizar un identificador único. Del tutorial anterior conocemos el nombre del gen de la proteína que estamos buscando, OPN1LW.
Práctica: Buscar OPN1LW en UniProtKB
- Escriba
OPN1LWen la barra de búsqueda superior- Lanza la búsqueda
Preguntas
- ¿Cuántos resultados obtuvimos?
- ¿Qué debemos hacer para reducir este número?
- 200+ resultados (en el momento de la preparación de este tutorial)
- Necesitamos aclarar lo que estamos buscando: OPN1LW humano
Necesitamos añadir Human para aclarar lo que estamos buscando.
Práctica: Búsqueda de OPN1LW humano en UniProtKB
- Escriba
Human OPN1LWen la barra de búsqueda superior- Lanza la búsqueda
Preguntas
- ¿Cuántos resultados obtuvimos?
- ¿Tenemos un resultado que incluya OPN1LW como nombre de gen?
- 7 resultados (en el momento de la preparación de este tutorial)
- El primer resultado está etiquetado con
Gene: OPN1LW (RCP)
El primer resultado, etiquetado con Gene: OPN1LW (RCP), es nuestro objetivo, P04000 · OPSR_HUMAN. Antes de abrir la página, hay que tener en cuenta dos cosas:
- El nombre de la proteína
OPSR_HUMANes diferente del nombre del gen, así como sus IDs son. - Esta entrada tiene una estrella dorada, lo que significa que fue anotada y curada manualmente.
Inspeccionar una entrada UniProt
Práctica: Abrir un resultado en UniProt
- Haga clic en
P04000 · OPSR_HUMAN
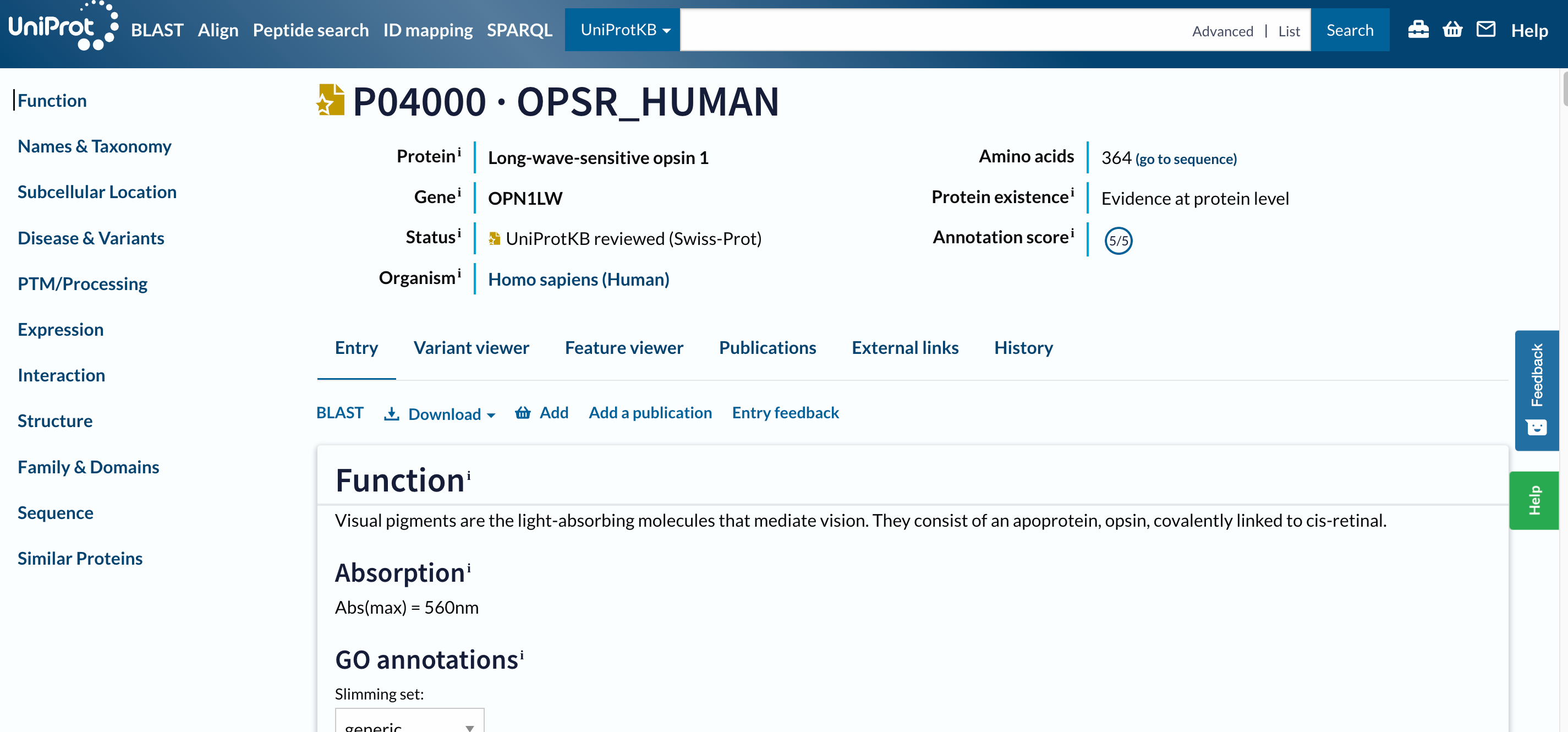 Open image in new tab
Open image in new tabPara navegar por esta larga página, el menú (barra de navegación) de la izquierda será de gran utilidad. Sólo por él, entendemos que esta base de datos contiene información sobre la entrada en:
- las funciones conocidas,
- la taxonomía,
- la ubicación,
- variantes y enfermedades asociadas,
- Modificación postraduccional (PTM),
- la expresión,
- las interacciones,
- la estructura,
- los dominios y su clasificación,
- las secuencias
- proteínas similares.
La barra de navegación permanece en el mismo lugar de la pantalla a medida que se avanza y retrocede en una entrada, de modo que se puede navegar rápidamente a las secciones de interés. Consultaremos todas las secciones mencionadas por separado, pero centrémonos primero en las cabeceras de la izquierda.
En la parte superior de la página, puede ver la entrada UniProt y su nombre, el nombre de la proteína y del gen, el organismo, si la entrada de la proteína ha sido revisada manualmente por un curador de UniProt, su puntuación de anotación y el nivel de evidencia de su existencia.
Debajo de la cabecera principal, encontrará una serie de pestañas (Entrada, Visor de variantes, Visor de características, Publicaciones, Enlaces externos, Historia). Las pestañas permiten cambiar entre la entrada, una vista gráfica de las características de la secuencia (Visor de características), las publicaciones y los enlaces externos, pero por el momento las ignora y no se mueve de la pestaña Entrada.
Entrada
El siguiente menú ya forma parte de la pestaña Entrada. Nos permite ejecutar una búsqueda de similitud de secuencias BLAST en la entrada, alinearla con todas sus isoformas, descargar la entrada en varios formatos, o añadirla a la cesta para guardarla para más tarde.
Preguntas
- ¿Cuáles son los formatos disponibles en el menú desplegable Descargar?
- ¿Qué tipo de información descargaríamos a través de estos formatos de archivo?
- Los formatos son:
Text,FASTA (canonical),FASTA (canonical & isoform,JSON,XML,RDF/XML,GFF- Los formatos
FASTAdeberían sonar familiares (después del tutorial preliminar), e incluyen la secuencia de la proteína, eventualmente con sus isoformas (en cuyo caso será un multi-FASTA). Aparte de éstos, todos los demás formatos no son específicos de una proteína, ni siquiera de una biología. Se trata de formatos de archivo generales muy utilizados por los sitios web para incluir la información que figura en la página. Por lo tanto, descargando el ficherotext(o incluso mejor eljson), descargaríamos la misma anotación a la que accedemos en esta página, pero en un formato más fácil de parsear programáticamente.
Desplacémonos ahora por la página de entrada, sección por sección.
Función
Esta sección resume las funciones de esta proteína como sigue:
Los pigmentos visuales son las moléculas que absorben la luz y se encargan de la visión. Están formados por una apoproteína, la opsina, unida covalentemente al cis-retinal.
Independientemente del nivel de detalle que entiendas (dependiendo de tu formación), esto es impresionantemente corto y específico teniendo en cuenta la enorme cantidad de literatura y estudios que existen más allá de la determinación de la función de una proteína. De todos modos, alguien hizo el trabajo por nosotros, y esta proteína ya está completamente clasificada en la Ontología Genética (GO), que describe la función molecular, el proceso biológico y el componente celular de cualquier proteína clasificada.
GO es un ejemplo perfecto de base de datos / recurso que parte de un universo de conocimientos muy complejo y lo traduce a un gráfico más simple, a riesgo de perder detalles. Esto tiene la gran ventaja de organizar la información, hacerla contable y analizable y accesible mediante programación, lo que en última instancia nos permite disponer de estas largas páginas de resumen y Bases de Conocimiento.
Preguntas
- ¿A qué funciones moleculares está anotada esta proteína?
- ¿A qué componentes celulares está anotada esta proteína?
- ¿A qué procesos biológicos está anotada esta proteína?
- Proteína fotorreceptora, receptor acoplado a proteína G
- Membrana del disco fotorreceptor
- Transducción sensorial, Visión
Nombres y taxonomía
Otros ejemplos de información estructurada están disponibles en la siguiente sección, por ejemplo, en la taxonomía. Esta sección también informa de otros identificadores únicos que se refieren a la misma entidad biológica o a entidades vinculadas (por ejemplo, enfermedades asociadas en el menú MIM).
Preguntas
- ¿Cuál es el identificador taxonómico asociado a esta proteína?
- ¿Cuál es el identificador del proteoma asociado a esta proteína?
- 9606, es decir, Homo sapiens
- UP000005640, componente del cromosoma Xs
Localización subcelular
Ya sabemos dónde está nuestra proteína en el cuerpo humano (en la retina, como se especifica en el resumen de la función), pero ¿dónde está en la célula?
Preguntas
- ¿Dónde se encuentra nuestra proteína en la célula?
- ¿Es coherente con la anotación GO observada anteriormente?
- La sección explica que se trata de una “proteína de membrana multipasos”, lo que significa que es una proteína que se inserta en la membrana celular y la atraviesa varias veces.
- La anotación GO de la parte superior menciona que nos referimos a la membrana (celular) del fotorreceptor en particular.
La sección Localización subcelular incluye un área de Características que detalla qué secciones, a lo largo de la secuencia de la proteína, están insertadas en la membrana (Transmembrana) y cuáles no (Dominio topológico).
Preguntas¿Cuántos dominios transmembrana y dominios topológicos existen?
8 dominios transmembrana y 7 topológicos
Enfermedad & Variantes
Como sabemos por el tutorial anterior, este gen/proteína está asociado a múltiples enfermedades. Esta sección detalla esta asociación y enumera las variantes específicas que se han detectado como relacionadas con la enfermedad.
Preguntas¿Qué tipos de estudios científicos permiten evaluar la asociación de una variante genética a enfermedades?
Tres métodos comúnmente utilizados para evaluar la asociación de una variante genética con una enfermedad son:
Estudios de asociación del genoma completo (GWAS)
Los GWAS se utilizan ampliamente para identificar variantes genéticas comunes asociadas a enfermedades. Consisten en escanear el genoma completo de un gran número de individuos para identificar variaciones vinculadas a una enfermedad o rasgo concreto.
Estudios Caso-Control
Los estudios de casos y controles se emplean con frecuencia para comparar individuos con una enfermedad con aquellos que no la padecen, centrándose en la presencia o frecuencia de variantes genéticas específicas en ambos grupos.
Estudios Familiares
Los estudios basados en familias implican el análisis de variantes genéticas dentro de familias en las que varios miembros están afectados por una enfermedad. Mediante el estudio de los patrones de herencia de las variantes genéticas y su asociación con la enfermedad dentro de las familias, los investigadores pueden identificar posibles genes asociados a la enfermedad.
Este tipo de estudios implicaría un uso extensivo de los tipos de archivos para gestionar datos genómicos, tales como: SAM (Sequence Alignment Map), BAM (Binary Alignment Map), VCF (Variant Calling Format) etc.
Esta sección también incluye un área Features, donde se mapean las variantes naturales a lo largo de la secuencia. Abajo, también se destaca que una vista más detallada de las características a lo largo de la secuencia se proporciona en la pestaña Enfermedad & Variantes, pero no la abramos por ahora.
PTM/Procesamiento
Una modificación post-traduccional (PTM) es un evento de procesamiento covalente resultante de una escisión proteolítica o de la adición de un grupo modificador a un aminoácido.
Preguntas¿Cuáles son las modificaciones postraduccionales de nuestra proteína?
Cadena, glicosilación, enlace disulfuro, residuo modificado
Expresión
Ya sabemos dónde se encuentra la proteína en la célula, pero en el caso de las proteínas humanas a menudo disponemos de información sobre dónde se encuentra en el cuerpo humano, es decir, en qué tejidos. Esta información puede proceder del Human ExpressionAtlas o de otros recursos similares.
Preguntas¿En qué tejido se encuentra la proteína?
Los tres pigmentos colorantes se encuentran en las células fotorreceptoras de los conos.
Interacción
Las proteínas desempeñan su función a través de su interacción con el entorno, en particular con otras proteínas. Esta sección informa de los interactores de nuestra proteína de interés, en una tabla que también podemos filtrar por localización subcelular, enfermedades y tipo de interacción.
La fuente de esta información son bases de datos como STRING, y la página de entrada de nuestra proteína está directamente enlazada desde esta sección.
Práctica: Búsqueda de OPN1LW humano en UniProtKB
- Haga clic en el enlace STRING en una pestaña diferente
Preguntas
- ¿Cuántos formatos de archivo diferentes se pueden descargar desde allí?
- ¿Qué tipo de información se transmitirá en cada fichero?
STRING proporciona datos en formatos de archivo descargables para apoyar análisis posteriores. El principal formato de archivo utilizado por STRING es el formato “TSV” (Tab-Separated Values), que presenta los datos de interacción de proteínas en un formato tabular estructurado. Este formato es idóneo para integrarlo fácilmente en diversas herramientas y programas de análisis de datos. Además, STRING ofrece datos en formato XML PSI-MI (Proteomics Standards Initiative Molecular Interactions), un estándar para representar datos de interacciones proteínicas que permite la compatibilidad con otras bases de datos de interacciones y plataformas de análisis. Estos formatos de archivo permiten a los investigadores aprovechar la gran cantidad de información sobre interacciones proteicas que contiene STRING para sus propios estudios y análisis. Los investigadores también pueden descargar representaciones visuales de las redes de proteínas en formatos de imagen como PNG y SVG, adecuados para presentaciones y publicaciones. Para análisis avanzados, STRING ofrece “archivos planos” que contienen información detallada sobre las interacciones, y archivos “MFA” (Multiple Alignment Format), útiles para comparar múltiples secuencias de proteínas. Estos diversos formatos de archivo descargables permiten a los investigadores aprovechar la riqueza de la información sobre interacciones proteicas de STRING para sus propios estudios y análisis.
Estructura
¿Siente curiosidad por las intrincadas estructuras tridimensionales de las proteínas? La sección Estructura de la página de entrada de UniProtKB es su puerta de entrada para explorar el fascinante mundo de la arquitectura de las proteínas.
En esta sección encontrará información sobre estructuras de proteínas determinadas experimentalmente. Estas estructuras proporcionan información crucial sobre el funcionamiento de las proteínas y su interacción con otras moléculas. Descubrirá vistas interactivas de la estructura de la proteína que puede explorar directamente dentro de la entrada UniProtKB. Esta característica proporciona una forma atractiva de navegar por los dominios de la proteína, los sitios de unión y otras regiones funcionales. Profundizando en la sección Estructura, comprenderá mejor la base física de la función de las proteínas y descubrirá la riqueza de información que pueden revelar los datos estructurales.
Preguntas
- ¿Cuál es la variante asociada al daltonismo?
- ¿Puedes encontrar ese aminoácido específico en la estructura?
- ¿Puede formular una conjetura de por qué esta mutación es disruptiva?
- En la sección Enfermedad y Variantes, descubrimos que el cambio de Glicina (G) a Ácido Glutámico (E) en la posición 338 de la secuencia de la proteína está asociado al Daltonismo.
- En el visor de estructura, podemos mover la molécula y pasar el ratón sobre la estructura para encontrar el AA en la posición 338. Puede llevar algún tiempo seguir las múltiples disposiciones helicoidales de estas estructuras. La glicina en 338 no está en una hélice, sino en lo que parece un bucle justo antes de una zona de baja confianza en la estructura.
- Basándonos en la información que hemos recopilado hasta ahora, podríamos formular una hipótesis de por qué es disruptiva. No está en una hélice (normalmente, en las proteínas transmembrana, las hélices se insertan en la membrana), por lo tanto, está en uno de los dominios más grandes que sobresalen de la membrana, dentro o fuera de la célula. Esta mutación probablemente no interrumpe la estructura en sus segmentos intramembrana, sino en uno de los dominios funcionales. Si quieres profundizar, puedes comprobar si se trata del segmento extra o intracelular en el Visor de características.
¿De dónde procede la información del visor de estructura?
Práctica: Búsqueda de OPN1LW humano en UniProtKB
- Haga clic en el icono de descarga situado debajo de la estructura
- Comprueba el archivo que se ha descargado
Se trata de un archivo PDB (Protein Data Bank), que permite visualizar y analizar la disposición de los átomos y aminoácidos de la proteína.
Sin embargo, no hay ninguna referencia a la base de datos PDB en los enlaces entre las bases de datos de estructuras 3D. En su lugar, el primer enlace hace referencia a la AlphaFoldDB. La base de datos AlphaFold es un recurso completo que proporciona estructuras 3D predichas para una amplia gama de proteínas. Utilizando técnicas de aprendizaje profundo e información evolutiva, AlphaFold predice con precisión la disposición espacial de los átomos dentro de una proteína, contribuyendo a nuestra comprensión de la función y las interacciones de las proteínas.
Por lo tanto, se trata de una predicción de la estructura, no de una estructura validada experimentalmente. Esta es la razón por la que está coloreada por confianza: las secciones en azul son las que tienen un valor de confianza alto, por lo que son aquellas para las que la predicción es muy fiable, mientras que las que están en naranja son menos reilizables o tienen una estructura desordenada (más flexible y móvil). No obstante, esta información se representa a través de un archivo PDB, porque sigue siendo estructural.
Familia y dominios
La sección Familia y Dominios de la página de entrada de UniProtKB proporciona una visión completa de las relaciones evolutivas y los dominios funcionales dentro de una proteína. Esta sección ofrece información sobre la pertenencia de la proteína a familias de proteínas, superfamilias y dominios, arrojando luz sobre sus características estructurales y funcionales.
El área Features confirma efectivamente que al menos uno de los dos dominios que sobresalen de la membrana (el N-terminal) está desordenado. Esta área suele incluir información sobre regiones conservadas, motivos y características importantes de la secuencia que contribuyen al papel de la proteína en diversos procesos biológicos. La sección confirma una vez más que estamos ante una proteína transmembrana, y enlaza con varios recursos de datos filogenéticos, de familias de proteínas o de dominios, que nos guían en la comprensión de cómo las proteínas comparten ancestros comunes, evolucionan y adquieren funciones especializadas.
Secuencia
Toda esta información sobre la evolución de la proteína, su función, su estructura, está codificada en última instancia en su secuencia. Una vez más, en esta sección tenemos la oportunidad de descargar el archivo FASTA que la transcribe, así como de acceder a la fuente de estos datos: los experimentos de secuenciación genómica que la evaluaron. En esta sección también se informa de cuándo se han detectado isoformas.
Preguntas¿Cuántas isoformas potenciales están asignadas a esta entrada?
1: H0Y622
Proteínas similares
La última sección de la página de entrada de UniProt informa de proteínas similares (esto es básicamente el resultado de una agrupación, con umbrales de identidad del 100%, 90% y 50%).
Preguntas
- ¿Cuántas proteínas similares al 100% de identidad?
- ¿Cuántas proteínas similares al 90% de identidad?
- ¿Cuántas proteínas similares al 50% de identidad?
- 0
- 83
- 397
Como habrá adivinado al ver esta página, gran parte del procesamiento de datos biológicos sobre una proteína consiste en mapear distintos tipos de información a lo largo de la secuencia y comprender cómo se influyen mutuamente. Un mapeo visual (y una tabla con la misma información) es proporcionado por las dos pestañas alternativas para ver esta entrada, que son el Visor de Variantes y el Visor de Características.
Visor de variantes
Práctica: Visor de variantes
- Haga clic en la pestaña Visor de variantes
El Visor de Variantes mapea todas las versiones alternativas conocidas de esta secuencia. Para algunas de ellas se conoce el efecto (patógeno o benigno), para otras no.
Preguntas¿Cuántas variantes son probablemente patógenas?
Al alejar la vista de variantes, vemos que tenemos 5 puntos rojos, es decir, 5 variantes probablemente patógenas.
El elevado número de variantes que se encuentran en esta sección sugiere que las “secuencias de proteínas” (así como las secuencias de genes, las estructuras de proteínas, etc.) son en realidad entidades menos fijas de lo que podríamos pensar.
Visor de características
Práctica: Visor de características
- Haga clic en la pestaña Visor de características
El Visor de características es básicamente una versión fusionada de todas las áreas de Características que encontramos en la página Entrada, incluyendo Dominios y sitios, Procesamiento de moléculas, PTMs, Topología, Proteómica, Variantes. Si en el visor hace clic en cualquier característica, se enfocará la región correspondiente en la estructura, como la variante de interés
Práctica: Visor de variantes
- Expandir la parte *Variantes
- Zoom out
- Haga clic en nuestra variante de interés (el punto rojo en la posición 338)
Preguntas¿Cuál es la topología en este lugar?
Un dominio citoplasmático topológico
Por último, echemos un vistazo rápido a las otras pestañas.
Publicaciones
Práctica: Publicación
- Haga clic en la pestaña Publicación
En Publicaciones se enumeran las publicaciones científicas relacionadas con la proteína. Éstas se recopilan fusionando una lista completamente curada en UniProtKB/Swiss-Prot y otras importadas automáticamente. En esta pestaña, puede filtrar la lista de publicaciones por fuente y categorías que se basan en el tipo de datos que contiene una publicación sobre la proteína (como función, interacción, secuencia, etc.), o por el número de proteínas en el estudio correspondiente que describe (“pequeña escala” frente a “gran escala”).
Preguntas
- ¿Cuántas publicaciones hay asociadas a esta proteína?
- ¿Cuántas publicaciones contienen información sobre su función?
- 57
- 23
Enlaces externos
Práctica: Enlaces externos
- Haga clic en la pestaña Enlaces externos
La pestaña Enlaces externos reúne todas las referencias a bases de datos y recursos de información externos que encontramos en cada sección de la página de entrada. El texto de los enlaces suele informar de los identificadores únicos que representan a la misma entidad biológica en otras bases de datos. Para hacerse una idea de esta compexidad, consulte la siguiente imagen (que ya está parcialmente desfasada).
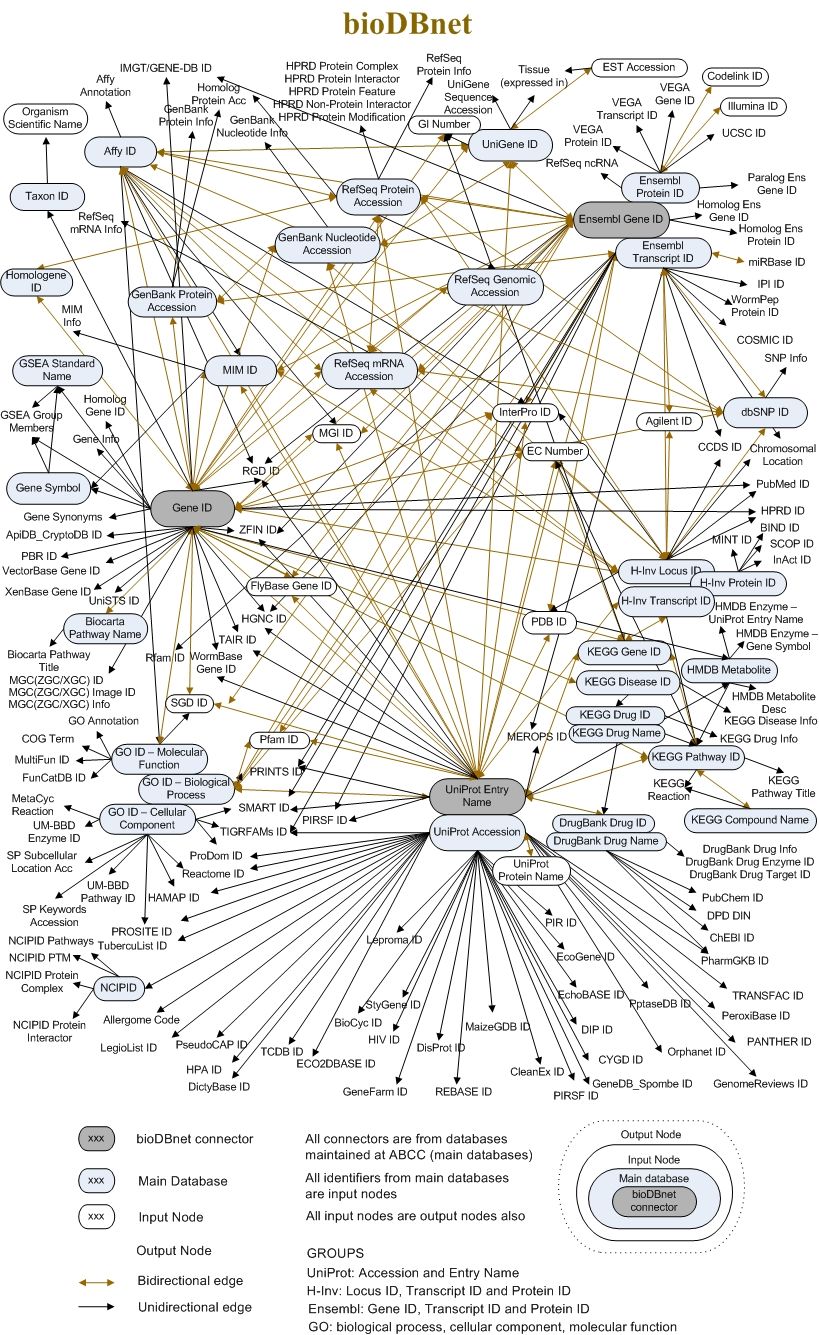 Open image in new tab
Open image in new tabHistoria
Por último, la pestaña Historia también es interesante. Informa y pone a disposición para su descarga todas las versiones anteriores de las anotaciones de esta entrada, es decir: toda la “evolución” de su anotación, que en este caso se remonta a 1988.
Preguntas¿Esta entrada no ha sido anotada manualmente?
Para responder a esta pregunta puede desplazarse hacia atrás en el tiempo por la tabla y comprobar la columna
Database. ¿Estuvo alguna vez en TrEMBL en lugar de en SwissProt? No, por lo que esta entrada fue anotada manualmente desde su inicio.
You've finished the tutorial
Puntos clave
Cómo navegar por las entradas de UniProtKB, accediendo a detalles exhaustivos sobre proteínas, como su función, taxonomía e interacciones.
El Variant y el Feature viewer son herramientas útiles para explorar visualmente variantes, dominios, modificaciones y otras características clave de la secuencia.
Amplía tu comprensión utilizando enlaces externos para cruzar referencias de datos y descubrir relaciones complejas.
Explora la pestaña Historia para acceder a versiones anteriores de las anotaciones de la entrada.
Preguntas frecuentes
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsRetroalimentación
¿Utilizaste este material como instructor? Cuéntanos tu experiencia.
¿Has usado este material como aprendiz o estudiante? Haz click en el formulario a continuación para dejarnos tu opinión

Cómo citar este tutorial
- Lisanna Paladin, Bérénice Batut, Una proteína a lo largo de la página UniProt (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-protein/tutorial_ES.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{data-science-online-resources-protein, author = "Lisanna Paladin and Bérénice Batut", title = "Una proteína a lo largo de la página UniProt (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-protein/tutorial_ES.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Referencias
These individuals or organisations provided funding support for the development of this resource
¡Felicitaciones! ¡Completaste con éxito este tutorial!