Regulations/standards for AI using DOME
| Author(s) |
|
| Editor(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How should data provenance be documented to ensure transparency in AI research?
What strategies can be employed to manage redundancy between training and test datasets in biological research?
Why is it important to make datasets and model configurations publicly available, and how can this be achieved?
What are the key considerations in selecting and documenting optimization algorithms and parameters for AI models?
How can the interpretability of AI models be enhanced, and why is this crucial in fields like drug design and diagnostics?
Explain the importance of data provenance and dataset splits in ensuring the integrity and reproducibility of AI research.
Develop a comprehensive plan for documenting and sharing AI model configurations, datasets, and evaluation results to enhance transparency and reproducibility in their research.
Time estimation: 3 hoursLevel: Intermediate IntermediateSupporting Materials:Published: Mar 11, 2025Last modification: May 19, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00518version Revision: 3
With the significant drop in the cost of many high-throughput technologies, vast amounts of biological data are being generated and made available to researchers. Machine learning (ML) has emerged as a powerful tool for analyzing data related to cellular processes, genomics, proteomics, post-translational modifications, metabolism, and drug discovery, offering the potential for transformative medical advancements.
This trend is evident in the growing number of ML publications:
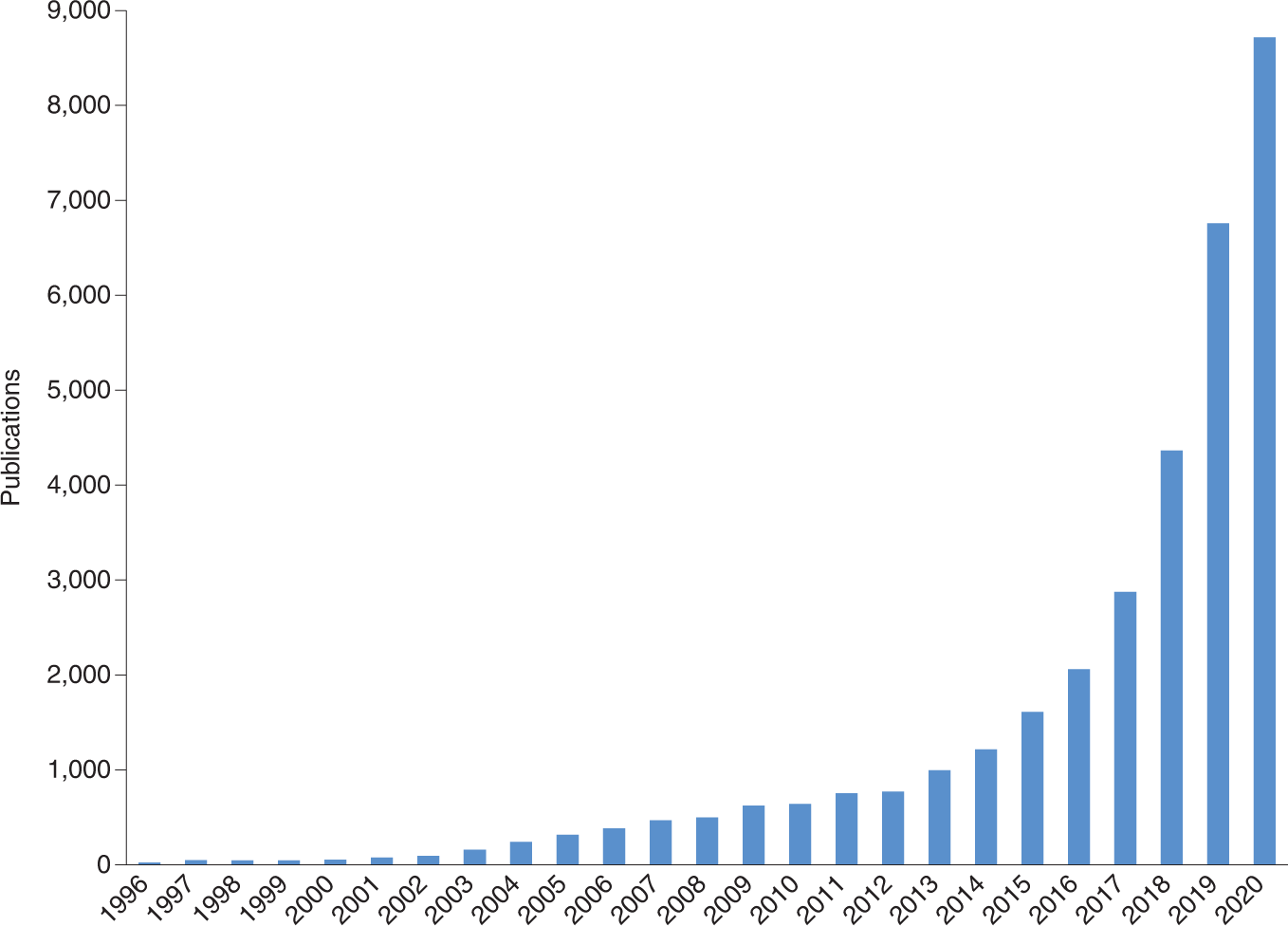 Open image in new tab
Open image in new tabHowever, although ML methods should ideally be experimentally validated, this occurs in only a small portion of the studies. The time is right for the ML community to establish standards for reporting ML-based analyses to facilitate critical evaluation and enhance reproducibility (Walsh et al. 2021).
Guidelines or recommendations on the proper construction of machine learning (ML) algorithms can help ensure accurate results and predictions. In biomedical research, various communities have established standard guidelines and best practices for managing scientific data (Wilkinson et al. 2016) and ensuring the reproducibility of computational tools (Sandve et al. 2013, Grüning et al. 2018). Similarly, within the ML community, there is a growing need for a unified set of recommendations that address data handling, optimization techniques, model development, and evaluation protocols comprehensively.
A recent commentary (Jones 2019) emphasized the need for standards in ML, suggesting that introducing submission checklists (Walsh et al. 2016) could be a first step toward improving publication practices. In response, a community-driven consensus list of minimal requirements was proposed, framed as questions for ML implementers (Walsh et al. 2021). By adhering to these guidelines, the quality and reliability of reported methods can be more accurately assessed.
The focus is on Data, Optimization, Model, and Evaluation (DOME), as these four components encompass the core aspects of most ML implementations. These recommendations are primarily aimed at supervised learning in biological applications where direct experimental validation is absent, as this is the most commonly used ML approach.
Comment: ML in clinical settingsThe use of ML in clinical settings is not addressed, and it remains to be seen whether the DOME recommendations can be applied to other areas of ML, such as unsupervised, semi-supervised, or reinforcement learning.
Comment: Who is behind the DOME recommendations?The recommendations mentioned above were initially developed by the ELIXIR Machine Learning Focus Group in response to a Jones 2019 comment advocating for the establishment of standards in ML for biology. This focus group, comprising over 50 experts in the field of ML, held meetings to collaboratively develop and refine the recommendations through broad consensus.
In this tutorial, we will go through the DOME recommendations by addressing a series of key questions that authors should consider when describing supervised machine learning (ML) approaches in their manuscripts. Our goal is to ensure that ML analyses are conducted and reported at a high standard, promoting transparency and reproducibility in research.
To illustrate these recommendations, we will use MobiDB-lite (Necci et al. 2020) as an example. MobiDB-lite is a specialized tool designed for the rapid and precise prediction of intrinsically disordered regions within proteins. It operates by integrating multiple disorder prediction methods, which allows it to achieve high specificity and minimize false positives, particularly for long disordered regions. This tool is seamlessly integrated into the broader MobiDB database, enhancing the annotation of protein disorder and supporting large-scale studies in structural bioinformatics.
By following the DOME recommendations and using MobiDB-lite as a case study, we aim to provide clear guidelines on how to effectively report ML methodologies, ensuring that our research is both robust and accessible to the scientific community.
AgendaIn this tutorial, we will cover:
Data
ML models analyze experimental biological data by identifying patterns, which can then be used to generate biological insights from similar, previously unseen data. The ability of a model to maintain its performance on new data is referred to as its generalization power. Achieving strong generalization is a key challenge in developing ML models; without it, trained models cannot be effectively reused. Properly preprocessing data and using it in an informed way are essential steps to ensure good generalization.
State-of-the-art ML models are often capable of memorizing all variations within the training data. As a result, when evaluated on data from the training set, they may give the false impression of excelling at the given task. However, their performance tends to diminish when tested on independent data (called the test or validation set), revealing a lower generalization power. To address this issue, the original dataset should be randomly split into non-overlapping parts. The simplest method involves creating separate training and test sets (with a possible third validation set). Alternatively, more robust techniques like cross-validation or bootstrapping, which repeatedly create different training/testing splits from the available data, are often preferred.
Handling overlap between training and test data can be especially challenging in biology. For instance, in predicting entire gene or protein sequences, ensuring data independence might require reducing homologs in the dataset. In modeling enhancer–promoter contacts, a different criterion may be needed, such as ensuring that no endpoint is shared between training and test sets. Similarly, modeling protein domains may require splitting multidomain sequences into their individual domains before applying homology reduction. Each biological field has its own methods for managing overlapping data, making it crucial to consult prior literature when developing an approach.
Providing details on the size of the dataset and the distribution of data types helps demonstrate whether the data is well-represented across different sets. Simple visualizations, such as plots or tables, showing the number of classes (for classification), a histogram of binned values (for regression), and the various types of biological molecules included in the data, are essential for understanding each set. Additionally, for classification tasks, methods that account for imbalanced classes should be used if the class frequencies suggest a significant imbalance.
It’s also important to note that models trained on one dataset may not perform well on closely related, but distinct, datasets—a phenomenon known as “covariance shift.” This issue has been observed in several recent studies, such as those predicting disease risk from exome sequencing data. While covariance shift remains an open problem, potential solutions have been proposed, particularly in the field of transfer learning.
Furthermore, building ML models that generalize well on small training datasets often requires specialized models and algorithms. Finally, making experimental data publicly available is crucial. Open access to datasets, including precise data splits, enhances the reproducibility of research and improves the overall quality of ML publications. If public repositories are not available, authors should be encouraged to use platforms like ELIXIR deposition databases or Zenodo to ensure long-term data accessibility.
Be on the lookout for:
- Inadequate data size & quality
- Inappropriate partitioning, dependence between train and test data
- Class imbalance
- No access to data
Consequences:
- Data not representative of domain application
- Unreliable or biased performance evaluation
- Cannot check data credibility
Recommendation(s):
- Use independent optimization (training) and evaluation (testing) sets. This is especially important for meta algorithms, where independence of multiple training sets must be shown to be independent of the evaluation (testing) sets
- Release data, preferably using appropriate long-term repositories, and include exact splits.
- Offer sufficient evidence of data size & distribution being representative of the domain.
Provenance
Provenance of data refers to the origin, history, and lineage of data—essentially, tracking where the data came from, how it has been processed, and how it has moved through various systems. It’s like a detailed record that traces the data’s life cycle from creation to its current state. Understanding data provenance helps ensure transparency, trustworthiness, and reliability in data usage.
Question
- What is the source of the data (database, publication, direct experiment)?
- If data are in classes, how many data points are available in each class—for example, total for the positive (Npos) and negative (Nneg) cases?
- If regression, how many real value points are there?
- Has the dataset been previously used by other papers and/or is it recognized by the community?
- Protein Data Bank (PDB). X-ray structures missing residues.
- Npos = 339,603 residues.
- Nneg = 6,168,717 residues.
- Previously used in Walsh et al. 2015 as an independent benchmark set.
Dataset Splits
Dataset splits refer to the process of dividing a dataset into distinct subsets for different purposes, mainly in machine learning or data science tasks. The most common splits are:
-
Training Set: This is the largest subset, used to train the machine learning model. The model “learns” from this data by adjusting its internal parameters to minimize prediction errors.
-
Validation Set: A separate subset used to fine-tune the model’s hyperparameters. The model doesn’t learn directly from this data, but it helps monitor the model’s performance and avoid overfitting, which is when a model becomes too tailored to the training data and doesn’t generalize well.
-
Test Set: This is the final subset, used to evaluate the model’s performance. The test set remains unseen by the model until after training and validation are complete, providing an unbiased estimate of how well the model generalizes to new, unseen data.
In addition to these, there are some variations in dataset splitting strategies:
-
Holdout Split: A simple division where a fixed percentage of data is reserved for testing (e.g., 80% training, 20% test).
-
Cross-validation: In this technique, the dataset is split multiple times into training and validation sets, ensuring each data point is used for validation at least once (e.g., 5-fold cross-validation). This provides a more robust evaluation of the model’s performance.
Question
- How many data points are in the training and test sets?
- Was a separate validation set used, and if yes, how large was it?
- Are the distributions of data types (Npos and Nneg) in the training and test sets different? Are the distributions of data types in both training and test sets plotted?
From Example Publication
- Training set: N/A. Npos,test = 339,603 residues. Nneg,test = 6,168,717 residues
- No validation set.
- 5.22% positives on the test set.
Redundancy between data splits
Redundancy between data splits occurs when the same data points are present in more than one of the training, validation, or test sets. This is undesirable because it can distort model evaluation and lead to overoptimistic performance metrics (e.g. eliminating data points more similar than X%). This may impact the model by introducing the risk of overfitting and poor generalization rendering the performance metrics as unreliable.
Question
- How were the sets split?
- Are the training and test sets independent?
- How was this enforced (for example, redundancy reduction to less than X% pairwise identity)?
- How does the distribution compare to previously published ML datasets?
Not applicable.
Availability of data
Availability of data refers to the accessibility and readiness of data for use in various applications, such as analysis, machine learning, decision-making, or reporting. It ensures that data can be retrieved and utilized when needed by users or systems.
Question
- re the data, including the data splits used, released in a public forum?
- If yes, where (for example, supporting material, URL) and how (license)?
- Yes
- URL http://protein.bio.unipd.it/mobidblite/. Free use license.
Optimization
Optimization, or model training, refers to the process of adjusting the values that make up the model (including both parameters and hyperparameters) to enhance the model’s performance in solving a given problem. In this section, we will focus on challenges that arise from selecting suboptimal optimization strategies.
Be on the lookout for:
- Overfitting, underfitting, and illegal parameter tuning
- Imprecise parameters and protocols given
Consequences:
- Reported performance is too optimistic or too pessimistic
- The model models noise or misses relevant relationships
- Results are not reproducible
Recommendation(s):
- Clarify that evaluation sets were not used for feature selection.
- Report indicators on training and testing data that can aid in assessing the possibility of under- or overfitting for example, train vs. test error.
- Release definitions of all algorithmic hyperparameters, regularization protocols, parameters and optimization protocol.
- For neural networks, release definitions of training and learning curves
- Include explicit model validation techniques like N-fold cross-validation.
Optimization, or training, involves adjusting the values that define a model (such as parameters and hyperparameters), as well as preprocessing steps, to enhance the model’s ability to solve a given problem. Choosing an inappropriate optimization strategy can lead to issues like overfitting or underfitting. Overfitting occurs when a model performs exceptionally well on training data but fails on unseen data, making it ineffective in real-world scenarios. Underfitting, on the other hand, happens when overly simplistic models, capable of capturing only basic relationships between features, are applied to more complex data.
Feature selection algorithms can help reduce the risk of overfitting, but they come with their own set of guidelines. A key recommendation is to avoid using non-training data for feature selection and preprocessing. This is especially problematic for meta-predictors, as it can lead to an overestimation of the model’s performance. Finally, making files that detail the exact optimization protocol, including parameters and hyperparameters, publicly available is crucial. A lack of proper documentation and limited access to these records can hinder the understanding and evaluation of the model’s overall performance.
Algorithm
Since algorithms take input data and produce output, typically solving a particular problem or achieving a specific objective, it is essential to know which one is implemented in a study. In this way we can have better insights for the results of learning patterns, relationships, or rules that can then be applied to new, unseen data.
There are three major categories of ML classes:
- Supervised (i.e. Linear Regression, Logistic Regression, Decision Trees, Support Vector Machines (SVM) and others),
- Unsupervised Learning (i.e. K-Means Clustering, Principal Component Analysis (PCA) and Hierarchical Clustering and others),
- Reinforcement Learning (i.e. Q-Learning, Deep Q-Networks (DQN) and others).
Question
- What is the ML algorithm class used?
- Is the ML algorithm new?
- If yes, why was it chosen over better known alternatives?
- Majority-based consensus classification based on 8 primary ML methods and post-processing.
Meta-predictions
Meta-predictions refer to predictions made by models that aggregate or utilize the outputs (predictions) of other models. Essentially, meta-prediction systems combine predictions from multiple models to produce a more robust or accurate final prediction. Meta-predictions are often used in ensemble learning techniques, where the goal is to leverage the strengths of several models to enhance overall performance.
Question
- Does the model use data from other ML algorithms as input?
- If yes, which ones?
- Is it clear that training data of initial predictors and meta-predictor are independent of test data for the meta-predictor?
From Example Publication
- Yes
- Predictor output is a binary prediction computed from the consensus of other methods
- Independence of training sets of other methods with test set of meta-predictor was not tested since datasets from other methods were not available.
Data encoding
Data encoding is the process of transforming data from one format or structure into another, often to make it easier for ML models or computational systems to process. In ML, data often needs to be encoded to ensure that it can be effectively interpreted by algorithms, especially for algorithms that require numerical input (e.g., neural networks, SVMs).
QuestionHow were the data encoded and preprocessed for the ML algorithm?
Label-wise average of 8 binary predictions.
Parameters
Model parameters are the internal configurations or variables that a model learns from the training data. These parameters determine how the model makes predictions and how well it fits the training data. The values of these parameters are adjusted during the training process through algorithms like gradient descent or optimization procedures.
Question
- How many parameters (\(p\)) are used in the model?
- How were \(p\) selected?
From Example Publication
- \(p = 3\): Consensus score threshold, expansion-erosion window, length threshold
- No optimization.
Features
In the context of ML, features refer to the individual measurable properties or characteristics of the data being used for training a model. They play a crucial role in determining the performance of ML models, as they provide the information that the model needs to make predictions or classifications. Feature Engineering is the process of creating, modifying, or selecting the most relevant features from the raw data to improve model performance by reducing model complexity, improving training time and avoiding overfitting.
Question
- How many features (f) are used as input?
- Was feature selection performed?
- If yes, was it performed using the training set only?
Not applicable.
Fitting
Fitting refers to the process of training a ML model on a dataset by adjusting its parameters to minimize prediction error. The goal is to find a balance between underfitting and overfitting, ensuring that the model captures the underlying patterns in the data while still generalizing well to unseen data. Proper evaluation, regularization, and tuning of the model during the fitting process are crucial to achieving a good fit.
Question
- Is p much larger than the number of training points and/or is f large (for example, in classification is p » (Npos + Nneg) and/or f > 100)?
- If yes, how was overfitting ruled out?
- Conversely, if the number of training points is much larger than p and/or f is small (for example, (Npos + Nneg) » p and/or f < 5), how was underfitting ruled out?
- Single input ML methods are used with default parameters.
- Optimization is a simple majority.
Regularization
Regularization is a technique used to prevent overfitting by adding a penalty to the loss function, which discourages the model from becoming too complex. Common regularization techniques include:
- L1 Regularization (Lasso): Adds a penalty proportional to the absolute value of the coefficients. It encourages sparsity, setting some coefficients to zero.
- L2 Regularization (Ridge): Adds a penalty proportional to the square of the coefficients, discouraging large coefficients and thus reducing model complexity.
- Dropout (in neural networks): Randomly drops a percentage of neurons during training, which helps prevent overfitting by forcing the network to generalize.
Question
- Were any overfitting prevention techniques used (for example, early stopping using a validation set)?
- If yes, which ones?
- No.
Availability of configuration
Availability of configuration refers to the accessibility and transparency of the settings, parameters, and options that can be adjusted or customized in a ML model or system. These configurations control how the model is trained, how it makes predictions, and how it operates in different environments. Ensuring that the configuration is available, flexible, and easy to modify is important for reproducibility, fine-tuning, and deployment of models.
Question
- Are the hyperparameter configurations, optimization schedule, model files and optimization parameters reported?
- If yes, where (for example, URL) and how (license)?
- Not applicable.
Model
Good overall performance and the model’s ability to generalize well to unseen data are crucial factors that significantly impact the applicability of any proposed ML research. However, several other important aspects related to ML models must also be considered.
Be on the lookout for:
- Unclear if black box or interpretable model
- No access to resulting source code, trained models & data
- Execution time impractical
Consequences:
- An interpretable model shows no explainable behavior
- Cannot cross compare methods & reproducibility, or check data credibility
- Model takes too much time to produce results
Recommendation(s):
- Describe the choice of black box or interpretable model. If interpretable, show examples of interpretable output.
- Release documented source code + models + software containers
- Report execution time averaged across repeats. If computationally tough, compare to similar methods.
Equally important aspects of ML models include their interpretability and reproducibility. Interpretable models can identify causal relationships in the data and provide logical explanations for their predictions, which is especially valuable in fields like drug design and diagnostics. In contrast, black box models, while often accurate, may not offer understandable insights into the reasons behind their predictions. Both types of models are discussed in more detail elsewhere, and choosing between them involves weighing their respective benefits. The key recommendation is to clearly state whether the model is a black box or interpretable, and if it is interpretable, to provide clear examples of its outputs.
Reproducibility is crucial for ensuring that research outcomes can be effectively utilized and validated by the broader community. Challenges with model reproducibility go beyond merely documenting parameters, hyperparameters, and optimization protocols. Limited access to essential model components (such as source code, model files, parameter configurations, and executables) and high computational demands for running trained models on new data can severely restrict or even prevent reproducibility.
Interpretability
Model interpretability refers to the extent to which a human can understand the decisions and predictions made by a ML model. Interpretability is crucial for building trust in model outcomes, especially in high-stakes domains such as healthcare and finance, where understanding the rationale behind a model’s predictions can have significant implications. For example neural networks are often criticized for being “black boxes,” as their internal workings (like hidden layers) are less transparent, making them more difficult to trust.
There are generally two types of interpretability:
-
Global Interpretability refers to the ability to understand the overall behavior of the model across all predictions. It involves explaining how the model works as a whole and what features are important in determining predictions.
-
Local interpretability focuses on understanding individual predictions made by the model. It aims to explain why a specific input led to a particular output.
Question
- Is the model black box or interpretable?
- If the model is interpretable, can you give clear examples of this?
From Example Publication
- Transparent, in so far as meta-prediction is concerned.
- Consensus and post processing over other methods predictions (which are mostly black boxes). No attempt was made to make the meta-prediction a black box.
Output
The output of a machine learning model refers to the predictions or classifications made by the model after processing input data. Depending on the type of model and the nature of the problem, the output can vary widely.
Here’s a breakdown of some different types of outputs:
- Regression includes continuous values that estimates a quantity based on the input features
- In classification tasks the output is a category or class label that indicates which class the input belongs to.
- In multi-class classification the model predicts one class from multiple possible classes.
- Multi-label classification includes the assignment of multiple classes to a single input.
QuestionIs the model classification or regression?
Classification, i.e. residues thought to be disordered.
Execution time
Execution time in the context of ML refers to the duration it takes for a model to perform a specific task, such as training, predicting, or evaluating performance. Understanding and measuring execution time is crucial for various reasons, including optimizing model performance, resource management, and user experience.
CPU time of single representative execution on standard hardware (e.g. seconds on desktop PC).
QuestionHow much time does a single representative prediction require on a standard machine (for example, seconds on a desktop PC or high-performance computing cluster)?
Approximately 1 second per representative on a desktop PC.
Availability of software
Availability of software refers to the accessibility, reliability, and usability of various software tools and libraries that facilitate the development, training, deployment, and evaluation of ML models. This includes both open-source and proprietary software, and it is critical for researchers and practitioners to have the right tools at their disposal to effectively work on tasks.
Question
- Is the source code released?
- Is a method to run the algorithm (executable, web server, virtual machine or container instance) released?
- If yes, where (for example github, zenodo or other repository URL) and how (for example MIT license)?
- Yes
- Yes
- URL: http://protein.bio.unipd.it/mobidblite/. Bespoke license free for academic use
Evaluation
In implementing a robust and trustworthy ML method, providing a comprehensive data description, adhering to a correct optimization protocol, and ensuring that the model is clearly defined and openly accessible are critical first steps. Equally important is employing a valid assessment methodology to evaluate the final model.
Be on the lookout for:
- Performance measures inadequate
- No comparisons to baselines or other methods
- Highly variable performance
Consequences:
- Biased performance measures reported
- The method is falsely claimed as state-of-the-art
- Unpredictable performance in production
Recommendation(s):
- Compare with public methods & simple models (baselines).
- Adopt community-validated measures and benchmark datasets for evaluation.
- Compare related methods and alternatives on the same dataset
- Evaluate performance on a final independent held-out set
- Use confidence intervals/error intervals and statistical tests to gauge robustness.
In biological research, there are two main types of evaluation scenarios for ML models:
Experimental Validation: This involves validating the predictions made by the ML model through laboratory experiments. Although highly desirable, this approach is often beyond the scope of many ML studies.
Computational Assessment: This involves evaluating the model’s performance using established metrics. This section focuses on computational assessment and highlights a few potential risks.
When it comes to performance metrics, which are quantifiable indicators of a model’s ability to address a specific task, there are numerous metrics available for various ML classification and regression problems. The wide range of options, along with the domain-specific knowledge needed to choose the right metrics, can result in the selection of inappropriate performance measures. It is advisable to use metrics recommended by critical assessment communities relevant to biological ML models, such as the Critical Assessment of Protein Function Annotation (CAFA) and the Critical Assessment of Genome Interpretation (CAGI). Once appropriate performance metrics are selected, methods published in the same biological domain should be compared using suitable statistical tests (e.g., Student’s t-test) and confidence intervals. Additionally, to avoid releasing ML methods that seem advanced but do not outperform simpler algorithms, it is important to compare these methods against baseline models and demonstrate their statistical superiority (e.g., comparing shallow versus deep neural networks).
Evaluation method
Evaluation of a ML model is the process of assessing its performance and effectiveness in making predictions or classifications based on new, unseen data. Proper evaluation is crucial to ensure that the model generalizes well and performs as expected in real-world applications.
QuestionHow was the method evaluated (for example cross-validation, independent dataset, novel experiments)?
Independent dataset
Performance measures
The choice of evaluation metrics depends on the type of problem (regression or classification) and the specific goals of the analysis:
| Regression Metrics | Classification Metrics |
|---|---|
| Mean Absolute Error (MAE) | Accuracy |
| Mean Squared Error (MSE) | Precision |
| Root Mean Squared Error (RMSE) | Recall (Sensitivity) |
| R-squared (R2) | F1 Score |
Question
- Which performance metrics are reported (Accuracy, sensitivity, specificity, etc.)?
- Is this set representative (for example, compared to the literature)?
- Balanced Accuracy, Precision, Sensitivity, Specificity, F1, MCC.
Comparison
Comparison typically refers to the evaluation of different models, algorithms, or configurations to identify which one performs best for a specific task. This process is essential for selecting the most suitable approach for a given problem, optimizing performance, and understanding the strengths and weaknesses of various methods.
Question
- Was a comparison to publicly available methods performed on benchmark datasets?
- Was a comparison to simpler baselines performed?
- DisEmbl-465, DisEmbl-HL, ESpritz Disprot, ESpritz NMR, ESpritz Xray, Globplot, IUPred long, IUPred short, VSL2b. Chosen methods are the methods from which the meta prediction is obtained.
Confidence
Confidence in the context of ML refers to the measure of certainty or belief that a model’s prediction is accurate. It quantifies the model’s certainty regarding its output, which is particularly important in classification tasks, where decisions need to be made based on predicted class probabilities. This can be supported by methods such as confidence intervals and statistical significance.
Question: Key Questions
- Do the performance metrics have confidence intervals?
- Are the results statistically significant to claim that the method is superior to others and baselines?
Not calculated.
Availability of evaluation
Availability of evaluation in ML refers to the accessibility and readiness of tools, frameworks, datasets, and methodologies used to assess the performance of ML models. This encompasses various aspects, from the datasets used for evaluation to the metrics and software tools that facilitate the evaluation process.
Question: Key Questions
- Are the raw evaluation files (for example, assignments for comparison and baselines, statistical code, confusion matrices) available?
- If yes, where (for example, URL) and how (license)?
- Not.
Evaluate your model or publication
Time to practice on your work or a publication of your choice!
Hands On: Key Questions
- Select a publication
- Read the publication you have chosen.
- Locate/highlight the areas of interest according to the DOME sections. (how many are covered? which are missing?)
- Fill in this (some kind of ready table template to be given) with the information.
- Discuss your results with the rest of the group. (do you see any common trends?)
- Grab a beverage ☕ or a snack 🍩 to celebrate!
Conclusion
In this tutorial, we have explored the essential regulations and standards for AI using the DOME framework, focusing on key aspects of data management, optimization, model development, and evaluation. By adhering to these guidelines, researchers can ensure that their AI models are robust, transparent, and reproducible, thereby enhancing the credibility and impact of their work.
Data: We emphasized the importance of data provenance, ensuring that the origins and transformations of datasets are well-documented. Proper dataset splits and managing redundancy between these splits are crucial for maintaining the integrity of training and testing processes. Additionally, making data available to the scientific community fosters collaboration and reproducibility.
Optimization: We delved into the intricacies of algorithm selection and the challenges associated with meta-predictions. Proper data encoding, careful selection of parameters, and thoughtful feature engineering are essential for effective model training. Fitting the model while employing appropriate regularization techniques helps prevent overfitting and ensures generalization. Ensuring the availability of configuration details is vital for transparency and reproducibility.
Model: The tutorial highlighted the significance of interpretability in AI models, allowing for clearer insights into model decisions. Providing meaningful output and documenting execution time are important for practical applications. Ensuring the availability of software enables others to build upon and validate the model.
Evaluation: We discussed the importance of choosing appropriate evaluation methods and performance measures to accurately assess model effectiveness. Comparison with baseline models and ensuring confidence in the results through statistical methods are critical steps. Making the evaluation process and results available supports transparency and facilitates further advancements in the field.
By following these DOME recommendations, we can develop AI models that are not only technically sound but also ethically robust and scientifically rigorous. This framework encourages a culture of openness and collaboration, ultimately advancing the field of AI and its applications in various domains. As you implement these standards in your model or publication, you contribute to a more reliable and trustworthy AI ecosystem.
You've Finished the Tutorial
Key points
Ensuring data provenance, proper dataset splits, and managing redundancy are crucial for maintaining data integrity and enabling reproducibility in AI research.
Clear documentation of optimization strategies, including algorithm selection, parameter tuning, and regularization techniques, is essential for transparency and replicability of AI models.
Developing interpretable models and making software and configurations publicly available fosters trust and collaboration within the scientific community.
Employing rigorous evaluation methods, appropriate performance measures, and statistical comparisons ensures the reliability and validity of AI model outcomes, driving advancements in the field.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Sandve, G. K., A. Nekrutenko, J. Taylor, and E. Hovig, 2013 Ten simple rules for reproducible computational research. PLoS computational biology 9: e1003285. 10.1371/journal.pcbi.1003285
- Walsh, I., M. Giollo, T. Di Domenico, C. Ferrari, O. Zimmermann et al., 2015 Comprehensive large-scale assessment of intrinsic protein disorder. Bioinformatics 31: 201–208. 10.1093/bioinformatics/btu625
- Walsh, I., G. Pollastri, and S. C. E. Tosatto, 2016 Correct machine learning on protein sequences: a peer-reviewing perspective. Briefings in bioinformatics 17: 831–840. 10.1093/bib/bbv082
- Wilkinson, M. D., M. Dumontier, I. J. J. Aalbersberg, G. Appleton, M. Axton et al., 2016 The FAIR Guiding Principles for scientific data management and stewardship. Scientific data 3: 1–9. 10.1038/sdata.2016.18
- Grüning, B., J. Chilton, J. Köster, R. Dale, N. Soranzo et al., 2018 Practical computational reproducibility in the life sciences. Cell systems 6: 631–635. 10.1016/j.cels.2018.03.014
- Jones, D. T., 2019 Setting the standards for machine learning in biology. Nature Reviews Molecular Cell Biology 20: 659–660. 10.1038/s41580-019-0176-5
- Necci, M., D. Piovesan, D. Clementel, Z. Dosztányi, and S. C. E. Tosatto, 2020 MobiDB-lite 3.0: fast consensus annotation of intrinsic disorder flavors in proteins. Bioinformatics 36: 5533–5534. 10.1093/bioinformatics/btaa1045
- Walsh, I., D. Fishman, D. Garcia-Gasulla, T. Titma, G. Pollastri et al., 2021 DOME: recommendations for supervised machine learning validation in biology. Nature methods 18: 1122–1127. 10.1038/s41592-021-01205-4
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Fotis E. Psomopoulos, Stella Fragkouli, Regulations/standards for AI using DOME (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/statistics/tutorials/dome/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{statistics-dome, author = "Fotis E. Psomopoulos and Stella Fragkouli", title = "Regulations/standards for AI using DOME (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/statistics/tutorials/dome/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }