Imparare a conoscere un gene attraverso risorse e formati di dato biologici
Under Development!
This tutorial is not in its final state. The content may change a lot in the next months. Because of this status, it is also not listed in the topic pages.
| Autore/i |
|
| Traduzione |
|
| Revisore/i |
|
PanoramicaDomande:
Obiettivi:
Come utilizzare le risorse bioinformatiche per studiare una specifica famiglia di proteine (opsine)?
Come navigare nel Genome Data Viewer per trovare le opsine nel genoma umano?
Come identificare i geni associati alle opsine e analizzarne la posizione cromosomica?
Come esplorare la letteratura e i contesti clinici per il gene OPN1LW?
Come utilizzare i file di sequenze proteiche per eseguire ricerche di similarità utilizzando BLAST?
Partendo da una ricerca testuale, esplora più risorse web per esaminare molteplici tipi di informazioni su un gene, trasmesse attraverso più formati di file.
Stima del tempo: 1 oraLivello: Introduttivo IntroductoryMateriali di supporto:Pubblicato: Mar 30, 2026Ultima modifica: Mar 30, 2026Licenza: Il contenuto del tutorial è concesso in licenza Creative Commons Attribution 4.0 International License. Il framework GTN è concesso in licenza MITversion Revisione: 1
Quando facciamo un’analisi bioinformatica, per esempio RNA-seq, potremmo ritrovarci con un elenco di nomi di geni. Dobbiamo quindi esplorare questi geni. Ma come possiamo farlo? Quali sono le risorse disponibili per farlo? E come navigare al loro interno?
Lo scopo di questo tutorial è di familiarizzare con questi aspetti, utilizzando come esempio le opsine umane.
Le opsine umane si trovano nelle cellule della retina. Sono proteine che catturano la luce e iniziano la sequenza di segnali che porta alla visione. Procederemo ponendoci delle domande sulle opsine e sui geni delle opsine, utilizzando poi diversi database e risorse bioinformatiche per rispondere ad esse.
CommentoQuesto tutorial è un po’ atipico: non lavoreremo in Galaxy ma per lo più al di fuori di esso, navigando tra i database e gli strumenti attraverso le loro interfacce web. Lo scopo di questa esercitazione è quello di illustrare diverse fonti di dati biologici in diversi formati di file e che rappresentano diverse informazioni.
AgendaIn questo tutorial ci occuperemo di:
Ricerca di Opsine umane
Per cercare le Opsine umane, inizieremo controllando il NCBI Genome Data Viewer. L’NCBI Genome Data Viewer (GDV) (Rangwala et al. 2021) è un browser del genoma che supporta l’esplorazione e l’analisi degli assemblaggi di genomi eucariotici annotati. Il browser GDV visualizza le informazioni biologiche mappate su un genoma, tra cui l’annotazione dei geni, i dati sulle variazioni, gli allineamenti BLAST e i dati degli studi sperimentali dai database GEO e dbGaP dell’NCBI. Le note di rilascio di GDV descrivono le nuove funzionalità di questo browser.
Pratica: Aprire il visualizzatore di dati del genoma NCBI
- Aprire il visualizzatore di dati del genoma dell’NCBI all’indirizzo www.ncbi.nlm.nih.gov/genome/gdv
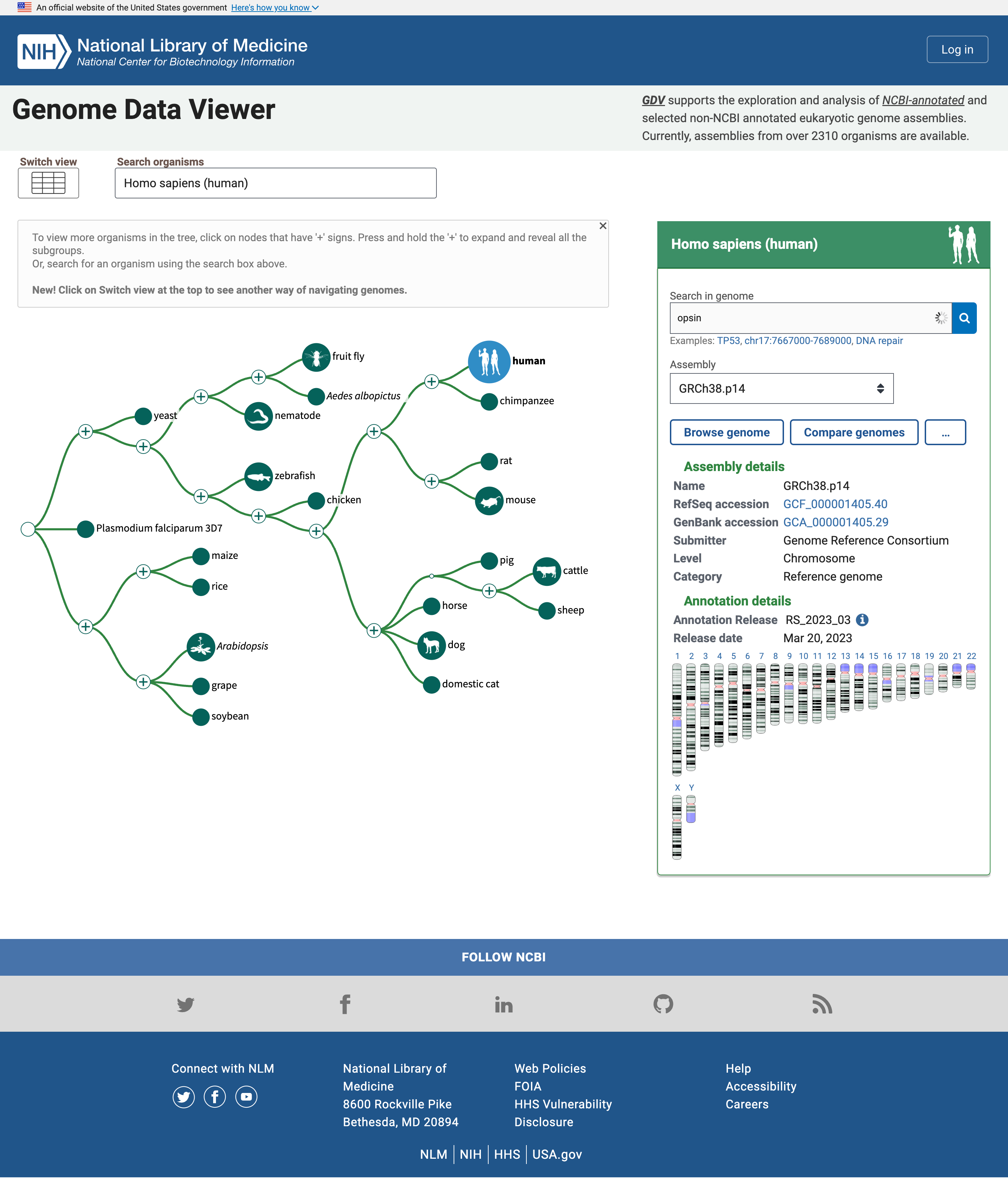
La homepage include un semplice “albero della vita” in cui il nodo umano è evidenziato perché è l’organismo predefinito per la ricerca. Possiamo cambiarlo nel riquadro Ricerca organismi, ma per ora lasciamo perdere perché siamo interessati alle Opsine umane.
 Open image in new tab
Open image in new tabIl pannello a destra riporta assemblaggi multipli del genoma di interesse e una mappa dei cromosomi in quel genoma. Possiamo cercare le Opsine.
Pratica: Ricerca di Opsine: Apri il visualizzatore di dati del genoma NCBI
- Digitare
opsinnella casella Ricerca nel genoma- Fare clic sull’icona della lente di ingrandimento o premere Invio
Sotto il riquadro viene ora visualizzata una tabella con i geni correlati all’opsina insieme ai loro nomi e alla loro posizione, cioè il numero del cromosoma, nonché la posizione iniziale e finale
Nell’elenco dei geni correlati al termine di ricerca opsina, ci sono il gene della rodopsina (RHO) e tre pigmenti del cono, le opsine sensibili a breve, media e lunga lunghezza d’onda (per il rilevamento della luce blu, verde e rossa). Esistono altre entità, ad esempio una -LCR (Locus Control Region), geni e recettori putativi.
Molti risultati si trovano sul cromosoma X, uno dei cromosomi che determinano il sesso.
Domanda
- Quanti geni sono stati trovati nel cromosoma X?
- Quanti sono i geni codificanti per le proteine?
- I risultati in ChrX sono:
- OPSINA-LCR
- OPN1LW
- OP1MW
- OPN1MW2
- OPN1MW3
- Passando il mouse su ogni gene, si apre un riquadro e possiamo cliccare su Dettagli per saperne di più su ogni gene. Si apprende così che il primo (OPSIN-LCR) non è un gene codificante ma una regione regolatoria e gli altri sono geni codificanti per le proteine. Quindi ci sono 4 geni codificanti per proteine legate alle opsine nel cromosoma X. In particolare, il cromosoma X include un gene per il pigmento rosso (OPN1LW) e tre geni per il pigmento verde (OPN1MW, OPN1MW2 e OPN1MW3 nell’assemblaggio del genoma di riferimento).
Concentriamoci ora su una specifica opsina, il gene OPN1LW.
Pratica: Aprire il browser del genoma per il gene OPN1LW
- Fare clic sulla freccia blu che appare nella tabella dei risultati quando si passa con il mouse sulla riga OPN1LW
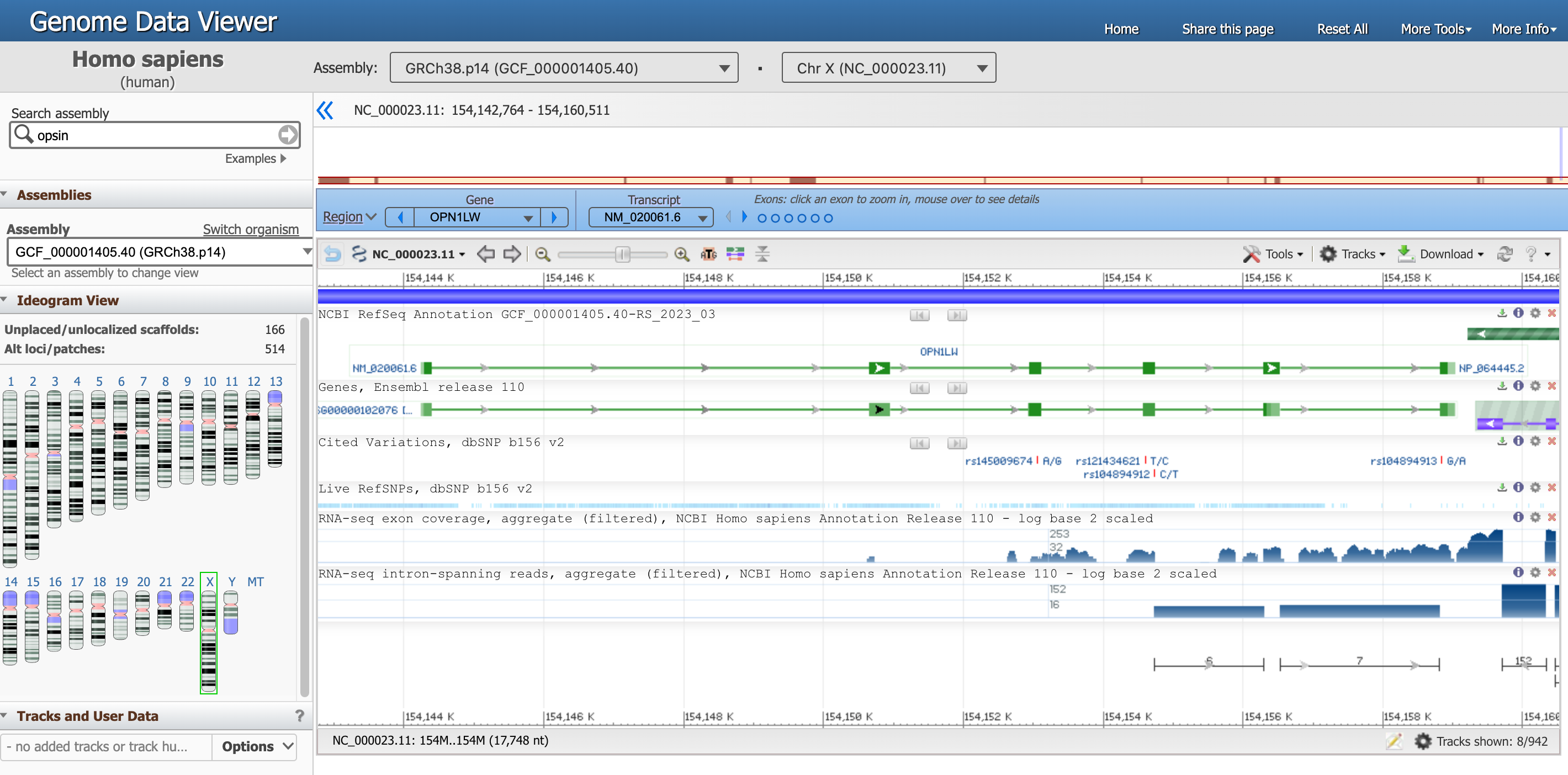
Dovreste essere arrivati a questa pagina, che è la vista del genoma del gene OPN1LW.
 Open image in new tab
Open image in new tabCi sono molte informazioni in questa pagina, concentriamoci su una sezione alla volta.
- Il visualizzatore di dati del genoma, in alto, ci dice che stiamo guardando i dati dell’organismo
Homo sapiens, dell’assemblaggioGRCh38.p14e in particolare diChr X(cromosoma X). Ciascuna di queste informazioni ha un ID univoco. - L’intero cromosoma è rappresentato direttamente qui sotto, e le posizioni lungo i bracci corti (
p) e lunghi (q) sono evidenziate. -
Di seguito, un riquadro blu evidenzia che ora ci stiamo concentrando sulla regione corrispondente al gene
OPN1LW.Ci sono diversi modi per interagire con il visualizzatore sottostante. Provate ad esempio a passare il mouse sui punti che rappresentano gli esoni nel riquadro blu.
-
Nel grafico sottostante, la sequenza genica è una linea verde con gli esoni (frammenti di codifica delle proteine) rappresentati da rettangoli verdi.
Passare il mouse sulla linea verde corrispondente a
NM_020061.6(il nostro gene di interesse) per ottenere informazioni più dettagliate.Domanda- Qual è la posizione del segmento OPN1LW?
- Qual è la lunghezza del segmento OPN1LW?
- Cosa sono gli introni e gli esoni?
- Quanti esoni e introni ci sono nel gene OPN1LW?
- Qual è la lunghezza totale della regione codificante?
- Qual è la distribuzione tra regioni codificanti e non codificanti? Che cosa significa in termini di biologia?
- Qual è la lunghezza della proteina in numero di aminoacidi?
- Da 154.144.243 a 154.159.032
- 1.4790 nucleotidi, trovato a Span su 14790 nt, nucleotidi)
- I geni eucariotici sono spesso interrotti da regioni non codificanti chiamate sequenze intercalari o introni. Le regioni codificanti sono chiamate esoni.
- Da questo diagramma si può vedere che il gene OPN1LW è composto da 6 esoni e 5 introni e che gli introni sono molto più grandi degli esoni.
- La lunghezza della CDS è di 1.095 nucleotidi.
- Dei 14790 nt del gene, solo 1095 nt codificano per le proteine, il che significa che meno dell’8% delle coppie di basi contiene il codice. Quando questo gene viene espresso nelle cellule della retina umana, viene sintetizzata una copia di RNA dell’intero gene. Poi le regioni introniche vengono tagliate e le regioni esoniche unite per produrre l’mRNA maturo (un processo chiamato splicing), che verrà tradotto dai ribosomi per produrre la proteina opsina rossa. In questo caso, il 92% della trascrizione iniziale dell’RNA viene eliminato, lasciando il codice proteico puro.
- La lunghezza della proteina risultante è di 364 aa, aminoacidi.
Ma qual è la sequenza di questo gene? Esistono diversi modi per recuperare questa informazione, noi ci occuperemo di quello che riteniamo essere uno dei più intuitivi.
Pratica: Aprire il browser del genoma per il gene OPN1LW
- fate clic sulla sezione tool Strumenti in alto a destra del riquadro che mostra il gene
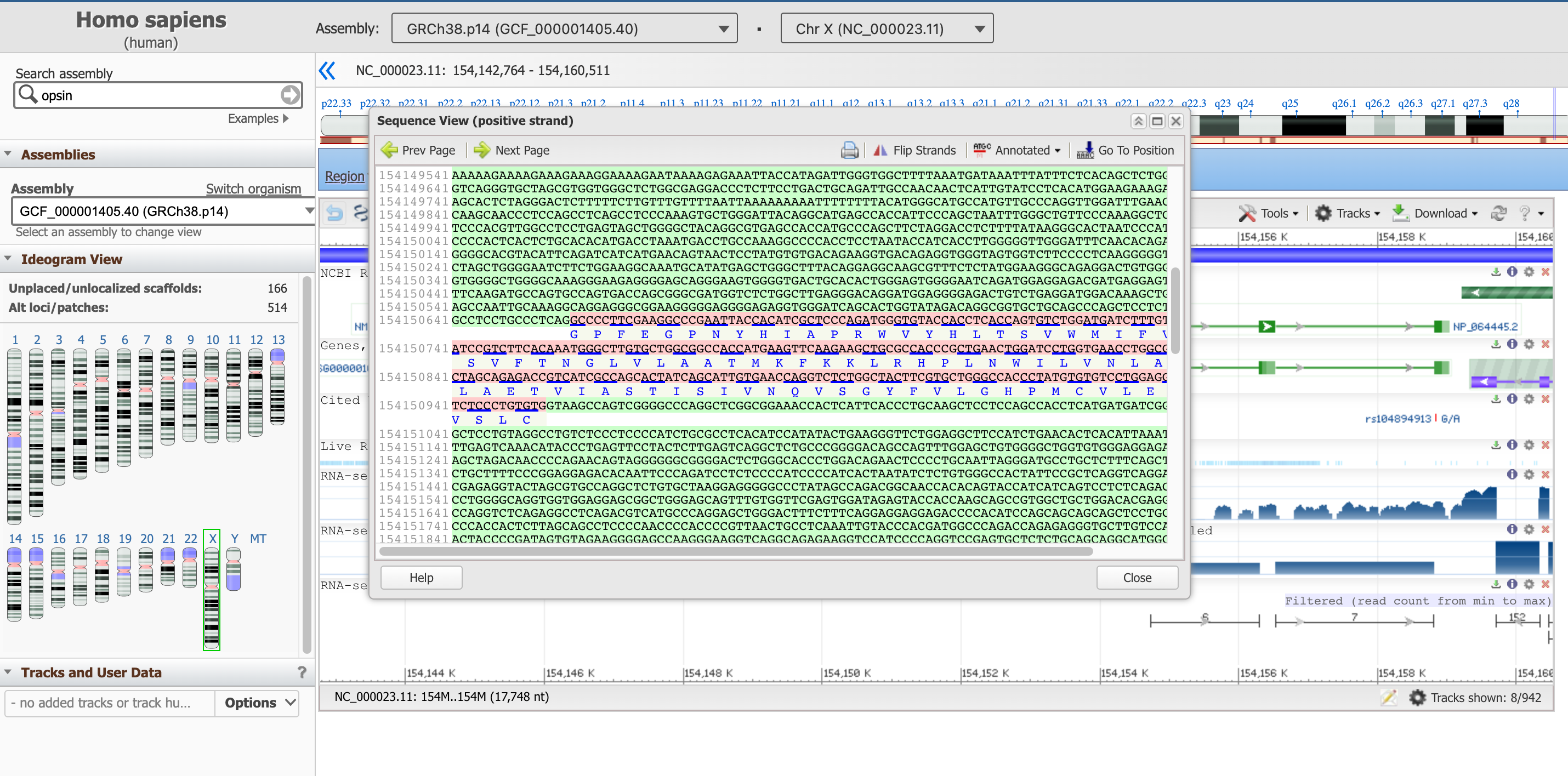
- Fare clic su Visualizzazione del testo della sequenza
Questo pannello riporta la sequenza del DNA degli introni (in verde) e quella degli esoni (in rosa, compresa la sequenza della proteina tradotta in basso).
 Open image in new tab
Open image in new tabQuesto riquadro di sequenza non mostra al momento l’intero gene, ma una sua sottosequenza. È possibile spostarsi a monte e a valle del codice genetico con le frecce Prev Page e Next Page, oppure partire da una posizione specifica con il pulsante Go To Position. Suggeriamo di partire dall’inizio della parte codificante del gene, che, come abbiamo appreso in precedenza, si trova alla posizione 154.144.243.
Pratica: Vai a una posizione specifica nella vista Sequenza
- Fare clic su Vai alla posizione
Digitare su
154144243Dobbiamo rimuovere le virgole per convalidare il valore
La sequenza evidenziata in viola segnala una regione regolatoria.
Domanda
- Qual è il primo amminoacido del prodotto proteico risultante?
- Qual è l’ultimo?
- Puoi annotare i primi tre e gli ultimi tre AA di questa proteina?
- La proteina corrispondente inizia con la metionina, M (lo fanno tutte).
- L’ultimo AA dell’ultimo esone (trovato nella seconda pagina) è l’alanina (A). Dopo di esso si trova il codone di stop TGA, che non viene tradotto in AA.
- I primi tre AA sono: M,A,Q; gli ultimi tre: S,P,A.
Possiamo ora chiudere la visualizzazione della sequenza.
Da questa risorsa si possono ottenere anche file, in formato diverso, che descrivono il gene. Sono disponibili nella sezione Download.
- Scaricare FASTA ci permetterà di scaricare il formato di file più semplice per rappresentare la sequenza nucleotidica di tutto l’intervallo visibile del genoma (più lungo del solo gene).
- Download GenBank flat file ci permetterà di accedere alle annotazioni disponibili su questa pagina (e oltre) in un formato di testo semplice.
- Scarica i dati delle tracce ci permette di ispezionare due dei formati di file presentati nelle diapositive: i formati GFF (GFF3) e BED. Se si cambiano le tracce, ognuna di esse può essere disponibile o meno.
Trovare ulteriori informazioni sul nostro gene
Facciamo ora una panoramica delle informazioni che abbiamo (in letteratura) sul nostro gene, utilizzando le risorse NCBI
Pratica: Vai a una posizione specifica nella vista Sequenza
- Aprire la ricerca NCBI su www.ncbi.nlm.nih.gov/search
- Digitare
OPN1LWnella casella di ricerca Cerca NCBI
 Open image in new tab
Open image in new tab.
Letteratura
Cominciamo con la letteratura e in particolare con i risultati di PubMed o PubMed Central
PubMed è un database di letteratura biomedica che contiene gli abstract delle pubblicazioni presenti nel database.
PubMed Central è un archivio di testo completo, che contiene il testo completo delle pubblicazioni presenti nel database.
Anche se il numero esatto di risultati può variare nel tempo rispetto alla schermata precedente, qualsiasi nome di gene dovrebbe avere più risultati in PubMed Central (ricerca nei testi completi delle pubblicazioni) che in PubMed (ricerca solo negli abstract).
Pratica: Aprire PubMed
- Fare clic su PubMed nel riquadro Letteratura
Avete inserito in PubMed, un database gratuito di letteratura scientifica, i risultati di una ricerca completa di articoli direttamente associati a questo locus genico.
Facendo clic sul titolo di ogni articolo, si possono vedere gli abstract dell’articolo. Se vi trovate in un campus universitario dove è disponibile l’accesso online a riviste specifiche, potreste anche vedere i link agli articoli completi. PubMed è il punto di accesso a un’ampia gamma di letteratura scientifica nel campo delle scienze della vita. Sul lato sinistro di ogni pagina di PubMed si trovano i collegamenti a una descrizione del database, alla guida e alle esercitazioni sulla ricerca.
Domanda
- Riesci a indovinare quali tipi di condizioni sono associate a questo gene?
- Risponderemo a questa domanda più tardi
Pratica: Torna alla pagina di ricerca NCBI
- Torna alla pagina di ricerca NCBI
Clinica
Concentriamoci ora sul riquadro Clinica e in particolare su OMIM. L’OMIM, l’Online Mendeliam Inheritance in Man (and woman!), è un catalogo di geni umani e disturbi genetici.
Pratica: Aprire OMIM
- Fare clic su OMIM nel riquadro Clinica
Ogni voce OMIM è un disturbo genetico (qui soprattutto tipi di daltonismo) associato a mutazioni in questo gene.
Pratica: Leggi tutto quello che il tuo interesse ti impone
- Seguire i link per ottenere maggiori informazioni su ogni voce
Commento: Leggi tutto ciò che ti interessaPer ulteriori informazioni su OMIM, fare clic sul logo OMIM in cima alla pagina. Attraverso OMIM, sono disponibili numerose informazioni su innumerevoli geni del genoma umano e tutte le informazioni sono supportate da riferimenti agli articoli di ricerca più recenti.
Come le variazioni nel gene influenzano il prodotto proteico e le sue funzioni? Torniamo alla pagina del NIH e cerchiamo di accedere all’elenco dei polimorfismi a singolo nucleotide (SNP) individuati dagli studi di genetica nel gene.
Pratica: Aprire dbSNP
- Torna alla pagina di ricerca NCBI
- Fare clic su dbSNP nel riquadro Clinica
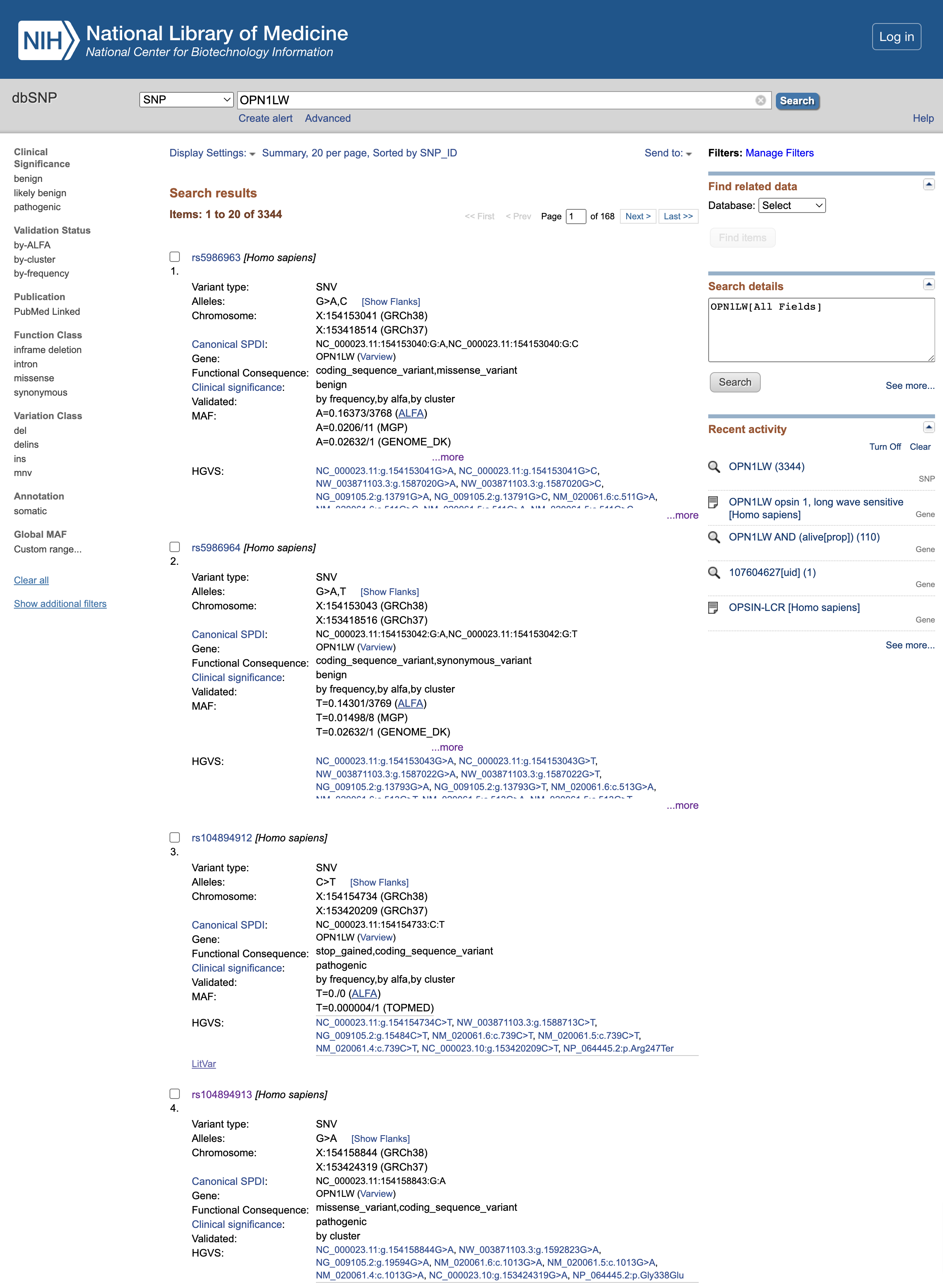 Open image in new tab
Open image in new tabDomanda
- Qual è il significato clinico delle varianti rs5986963 e rs5986964 (le prime due varianti elencate al momento della creazione di questo tutorial)?
- Qual è la conseguenza funzionale di rs104894912?
- Qual è la conseguenza funzionale di rs104894913?
- Il significato clinico è
benign, quindi sembra che non abbiano alcun effetto sul prodotto proteico finale- la mutazione rs104894912 porta a una variante
stop_gained, che tronca la proteina risultante troppo presto ed è quindipathogenic- la mutazione rs104894913 porta a un
missense_variant, anchepathogenic.
Indaghiamo ancora sulla variante rs104894913
Pratica: Per saperne di più su una variante dbSNP
- Clicca su
rs104894913per aprire la sua pagina dedicataClicca su Significato clinico
DomandaQuale tipo di condizione è associata alla variante rs104894913?
Il nome della malattia associata è “difetto di Protan”. Una rapida ricerca su Internet con il vostro motore di ricerca chiarirà che si tratta di un tipo di daltonismo.
Fare clic su Dettagli della variante
Domanda
- Quale sostituzione è associata a questa variante?
- Qual è l’impatto di questa sottotitolazione in termini di codoni e amminoacidi?
- In quale posizione della proteina si trova questa sostituzione?
- La sostituzione
NC_000023.10:g.153424319G>Acorrisponde al passaggio da una guanina (G) a un’adenina (A)- Questa sostituzione cambia il codone
GGG, una glicina, inGAG, un glutationep.Gly338Glusignifica che la sostituzione avviene nella posizione 338 della proteina.
Cosa significa questa sostituzione della proteina? Diamo un’occhiata più approfondita a questa proteina.
Proteine
Pratica: Aprire la proteina
- Torna alla pagina di ricerca NCBI
- Fare clic su Proteina nel riquadro Proteine
- Fare clic su
OPN1LW – opsin 1, long wave sensitivenella casella in alto
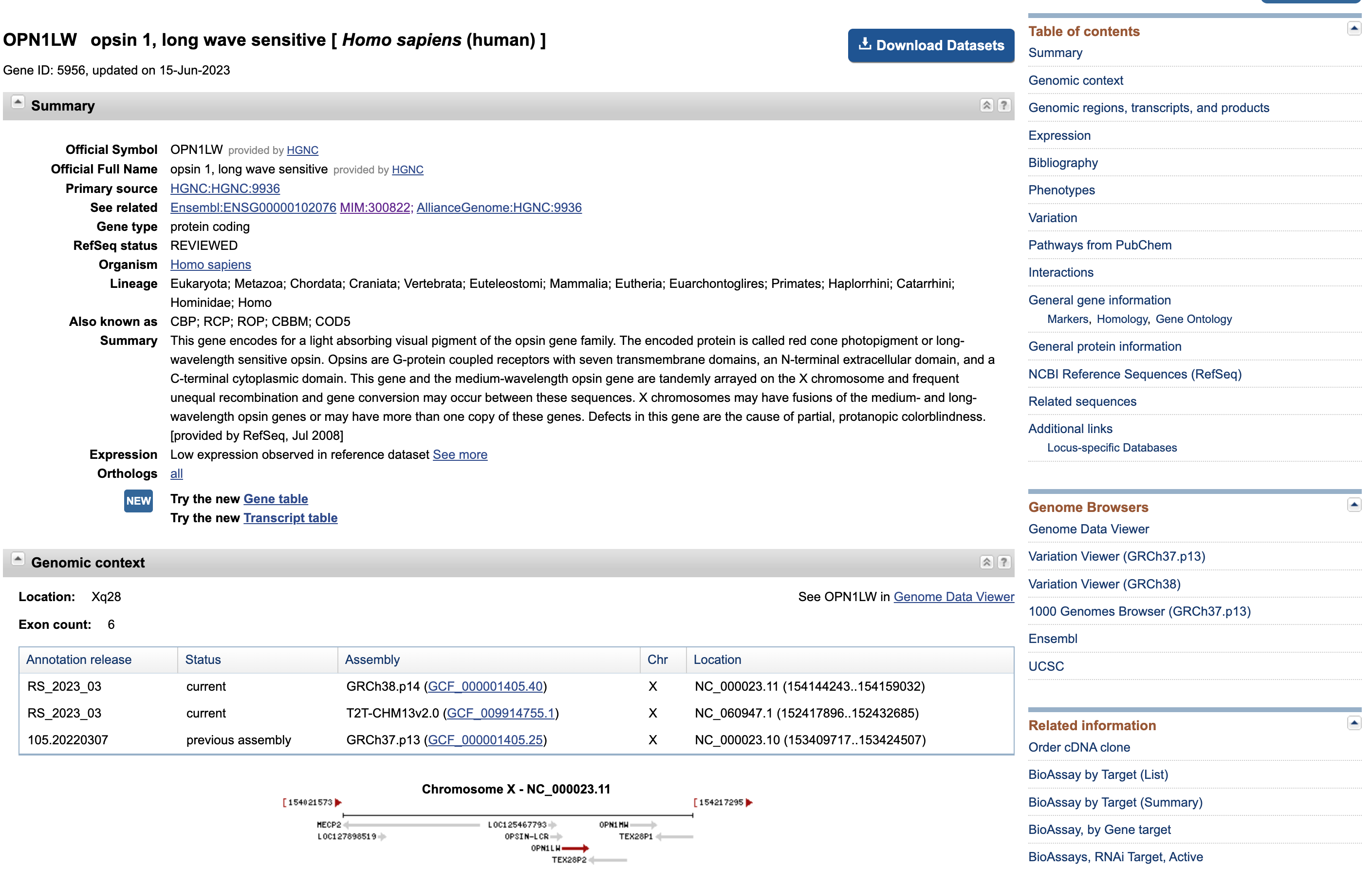 Open image in new tab
Open image in new tabQuesta pagina presenta ancora una volta alcuni dati che ci sono familiari (ad esempio la distribuzione degli esoni lungo la sequenza genica).
Pratica: Scaricare le sequenze di proteine
- Cliccare su Scaricare i dataset
- Seleziona
Gene Sequences (FASTA)Transcript sequences (FASTA)Protein sequences (FASTA)- Fare clic sul pulsante Scarica
- Aprire il file ZIP scaricato
Domanda
- Cosa contiene la cartella?
- Pensi che abbiano implementato buone pratiche per i dati?
- La cartella comprende
- una cartella
ncbi_datasetscon diverse sottocartelle al suo interno che contengono alcuni file di dati (formati multipli),- un
README.md(un file Markdown), progettato per “viaggiare” insieme ai dati e spiegare come sono stati recuperati i dati, qual è la struttura della sottocartella contenente i dati e dove trovare la documentazione completa.- È sicuramente una buona pratica di gestione dei dati quella di guidare gli utenti (non solo i vostri collaboratori, ma anche voi stessi in un futuro non troppo lontano, quando dimenticherete da dove proviene quel file nella vostra cartella Download) alla fonte e alla struttura dei dati.
Ricerca per sequenza
Cosa potremmo fare con queste sequenze appena scaricate? Supponiamo di aver appena sequenziato i trascritti che abbiamo isolato attraverso un esperimento - quindi conosciamo la sequenza della nostra entità di interesse, ma non sappiamo cosa sia. In questo caso, dobbiamo cercare nell’intero database delle sequenze conosciute dalla scienza e abbinare la nostra entità sconosciuta a una voce che abbia qualche annotazione. Procediamo in questo modo.
Pratica: Ricerca la sequenza proteica rispetto a tutte le sequenze proteiche
- Aprite (con il più semplice editor di testo che avete installato) il file
protein.faache avete appena scaricato.- Copia il suo contenuto
- Open BLAST blast.ncbi.nlm.nih.gov
Fare clic sul pulsante
Protein BLAST, protein > proteinUtilizzeremo una sequenza proteica per effettuare una ricerca in un database di proteine
- Incollare la sequenza della proteina nella casella di testo grande
- Controllare il resto dei parametri
- Fare clic sul pulsante blu
BLAST
Questa fase richiederà un po’ di tempo, dopotutto c’è un server da qualche parte che sta confrontando l’insieme delle sequenze note con il vostro obiettivo. Una volta completata la ricerca, il risultato dovrebbe essere simile a quello riportato di seguito:
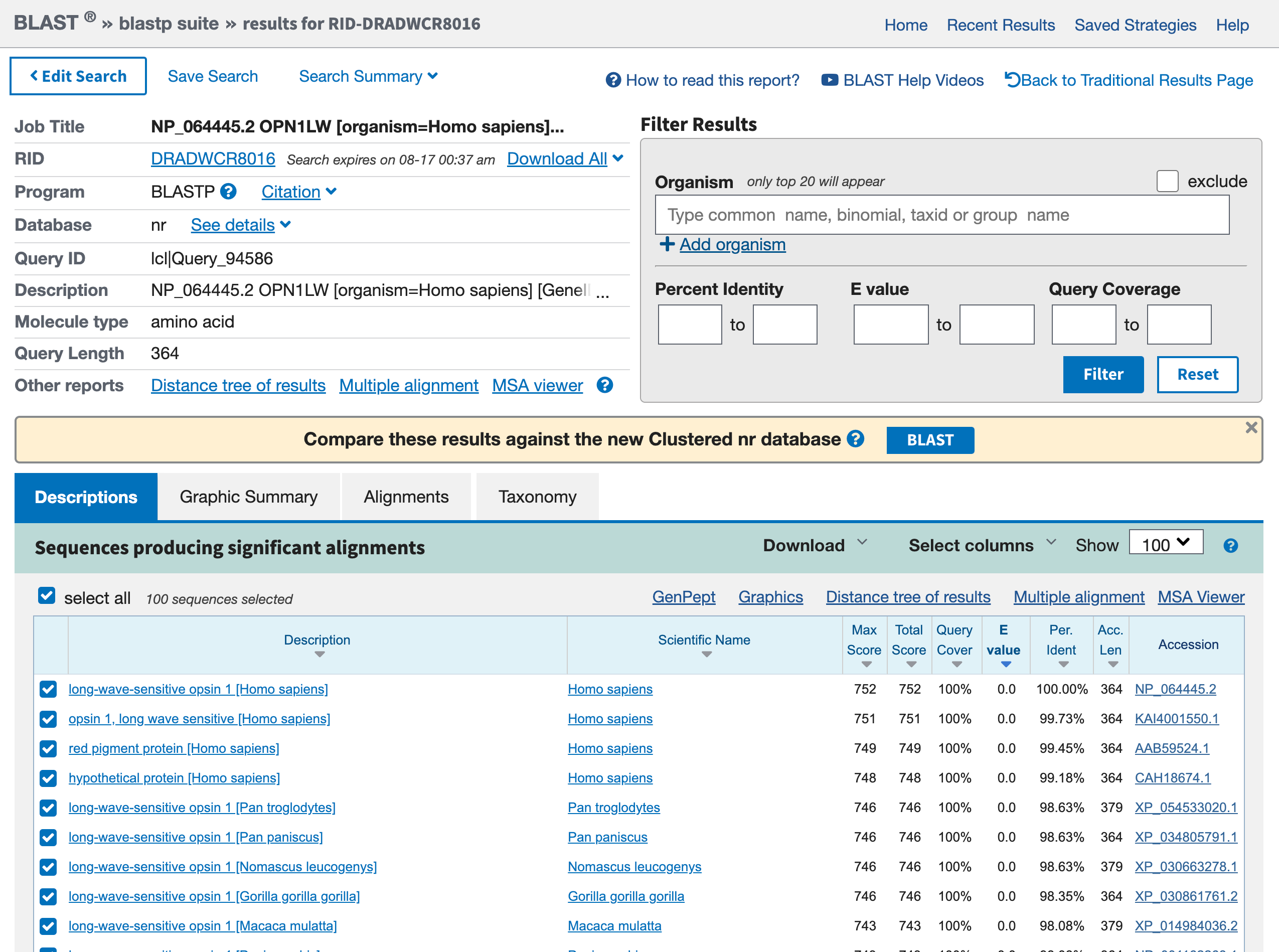 Open image in new tab
Open image in new tabPratica: Riepilogo grafico delle sequenze proteiche
- Fare clic sulla scheda Riassunto grafico
Accediamo a un riquadro contenente molte linee colorate. Ogni linea rappresenta un risultato della ricerca blast. Se si fa clic su una linea rossa, il riquadro stretto appena sopra il riquadro fornisce una breve descrizione dell’hit.
Pratica: Descrizioni delle sequenze proteiche
- Fare clic sulla scheda Descrizioni
Domanda
- Qual è il primo risultato? È previsto?
- Quali sono gli altri risultati? Per quali organismi?
- Il primo risultato è la nostra opsina rossa. Questo è incoraggiante, perché la migliore corrispondenza dovrebbe essere con la sequenza di query stessa, e si è ottenuta questa sequenza dalla voce del gene.
- Altri risultati sono altre opsine. Comprendono voci di altri primati (ad esempio
Pan troglogytes).
I risultati riguardano la nostra opsina rossa nell’uomo, ma anche altre opsine in altri primati. Potremmo volerlo, per esempio se volessimo usare questi dati per costruire un albero filogenetico. Se invece siamo abbastanza sicuri che la nostra sequenza di interesse sia umana, potremmo anche filtrare la ricerca solo nelle sequenze umane.
Pratica: Filtrare una ricerca BLAST
- Cliccare su Modifica ricerca
- Digitare
Homo sapiensnel campo *Organismo- Fare clic sul pulsante blu
BLAST
Con questa nuova ricerca, troviamo le altre opsine (verde, blu, pigmento della cellula roditrice) nell’elenco. Gli altri risultati hanno un numero inferiore di residui corrispondenti. Se si fa clic su una delle linee colorate nel Riepilogo grafico, si apriranno ulteriori informazioni su quel risultato e si potrà vedere quanta somiglianza c’è tra ciascuno di essi e l’opsina rossa, la nostra sequenza di query originale. Scorrendo l’elenco, ogni sequenza successiva ha meno punti in comune con l’opsina rossa. Ogni sequenza è mostrata a confronto con l’opsina rossa in quello che viene chiamato allineamento di sequenza a coppie. In seguito, si realizzeranno allineamenti di sequenze multiple da cui si potranno discernere le relazioni tra i geni.
Le visualizzazioni contengono due misure importanti della significatività dell’hit:
il punteggio di BLAST - Punteggio lableled (bit)
Il punteggio BLAST indica la qualità del miglior allineamento tra la sequenza richiesta e la sequenza trovata (hit). Più alto è il punteggio, migliore è l’allineamento. I punteggi vengono ridotti dai mismatch e dalle lacune nell’allineamento migliore. Il calcolo del punteggio è complesso e coinvolge una matrice di sostituzione, ovvero una tabella che assegna un punteggio a ogni coppia di residui allineati. La matrice più utilizzata per l’allineamento delle proteine è nota come BLOSUM62.
il valore di aspettativa (etichettato Expect o E)
Il “valore di aspettativa” E di un hit indica se l’hit è probabilmente il risultato di una somiglianza casuale tra hit e query o di un’ascendenza comune tra hit e query. ()
Commento: Filtrare una ricerca BLASTSe E è più piccolo di \(10\mathrm{e}{-100}\), a volte viene dato come 0,0.
Il valore di aspettativa è il numero di risultati che ci si aspetterebbe di ottenere per puro caso se si cercasse la propria sequenza in un genoma casuale delle dimensioni del genoma umano.
\(E = 25\) significa che ci si potrebbe aspettare di trovare 25 riscontri in un genoma di queste dimensioni, per puro caso. Quindi un riscontro con \(E = 25\) è probabilmente un riscontro casuale e non implica che la sequenza riscontrata abbia un’ascendenza comune con la sequenza ricercata.
Valori di aspettativa di circa 0,1 possono essere biologicamente significativi o meno (per decidere occorrono altri test).
Ma valori molto piccoli di E significano che l’hit è biologicamente significativo. La corrispondenza tra la vostra sequenza di ricerca e questo hit deve derivare da un’ascendenza comune tra le sequenze, perché le probabilità che la corrispondenza possa derivare dal caso sono semplicemente troppo basse. Ad esempio, \(E = 10\mathrm{e}{-18}\) per un riscontro nel genoma umano significa che ci si aspetterebbe una sola corrispondenza casuale in un miliardo di miliardi di genomi diversi della stessa dimensione del genoma umano.
La ragione per cui crediamo di provenire tutti da antenati comuni è che una massiccia somiglianza di sequenze in tutti gli organismi è semplicemente troppo improbabile per essere un evento casuale. Qualsiasi famiglia di sequenze simili in molti organismi deve essersi evoluta da una sequenza comune in un antenato remoto.
Pratica: Download
- Fare clic sulla scheda Descrizioni
- Fare clic su una qualsiasi sequenza hit
- Cliccare su Download
- Selezionare
FASTA (aligned sequences)
scaricherà un nuovo tipo di file, leggermente diverso: un FASTA allineato. Se volete, esploratelo prima della prossima sezione.
Mentre nelle sezioni precedenti di questo tutorial abbiamo usato ampiamente le interfacce web degli strumenti (visualizzatori genomici, scansione rapida della letteratura, lettura delle annotazioni, ecc.), questa ricerca BLAST è un esempio di una fase che si potrebbe automatizzare completamente con Galaxy.
Pratica: Ricerca di somiglianza con BLAST in Galaxy
Creare una nuova cronologia per questa analisi
Per creare una nuova storia è sufficiente fare clic sull’icona new-history nella parte superiore del pannello della storia:
Rinominare la storia
- Fare clic su galaxy-pencil (Modifica) accanto al nome della storia (che per impostazione predefinita è “Storia senza nome”)
- Digitare il nuovo nome
- fare clic su Salva
- Per annullare la ridenominazione, fare clic sul pulsante galaxy-undo “Annulla”
Se non si ha l’icona galaxy-pencil (Modifica) accanto al nome della cronologia (cosa che può accadere se si utilizza una versione precedente di Galaxy), procedere come segue:
- Fare clic su Cronologia senza nome (o sul nome attuale della cronologia) (Clicca per rinominare la cronologia) nella parte superiore del pannello della cronologia
- Digitare il nuovo nome
- Premere Invio
Importare la sequenza proteica tramite link da Zenodo o dalle librerie di dati condivisi Galaxy:
https://zenodo.org/record/8304465/files/protein.faa
- Copia la posizione del collegamento
- Fare clic su galaxy-upload Carica i dati nella parte superiore del pannello degli strumenti
- Selezionare galaxy-wf-edit Incollare/recuperare i dati
- Incollare il/i link nel campo di testo
- Premere Avvio
- Chiude la finestra
In alternativa al caricamento dei dati da un URL o dal proprio computer, i file possono essere resi disponibili da una libreria di dati condivisi:
- Entrare in Librerie (pannello sinistro)
- Navigare verso alla cartella corretta indicata dal vostro istruttore. Nella maggior parte dei Galaxies i dati delle esercitazioni vengono forniti in una cartella denominata GTN - Materiale –> Nome argomento -> Nome esercitazione.
- selezionare i file desiderati
- Fare clic su Aggiungi alla cronologia galaxy-dropdown vicino alla parte superiore e selezionare as Datasets dal menu a tendina
- Nella finestra pop-up, scegliere
- “Seleziona cronologia “: la cronologia in cui si desidera importare i dati (o crearne una nuova)
- Cliccare su Import
NCBI BLAST+ blastp ( Galaxy version 2.10.1+galaxy2) con i seguenti parametri:
- “Sequenza/e di query proteica/e “:
protein.faa- “Database soggetti/sequenze “:
Locally installed BLAST database“Database BLAST delle proteine “:
SwissProtPer cercare solo sequenze annotate in UniProt, dobbiamo selezionare l’ultima versione di
SwissProt- “Impostare il cutoff del valore di aspettativa “:
0.001- “Formato di output “:
Tabular (extended 25 columns)

DomandaPensate che i risultati siano esattamente gli stessi della nostra ricerca originale di
opsinin www.ncbi.nlm.nih.gov/genome/gdv? Perché?I risultati possono essere simili, ma ci sono sicuramente delle differenze. Infatti, non solo una ricerca testuale è diversa da una ricerca di sequenze in termini di metodo, ma anche in questa seconda tornata siamo partiti dalla sequenza di una specifica opsina, quindi da un ramo dell’intero albero genealogico delle proteine. Alcuni membri della famiglia sono più simili tra loro, quindi questo tipo di ricerca guarda all’intera famiglia da una prospettiva piuttosto parziale.
Maggiori informazioni sulla nostra proteina
Finora abbiamo esplorato queste informazioni sulle opsine:
- come sapere quali proteine di un certo tipo esistono in un genoma,
- come sapere dove si trovano lungo il genoma,
- come ottenere maggiori informazioni su un gene di interesse,
- come scaricare le loro sequenze in diversi formati,
- come utilizzare questi file per eseguire una ricerca di similarità.
Potreste essere curiosi di sapere come saperne di più sulle proteine che codificano. Abbiamo già raccolto alcune informazioni (ad esempio le malattie associate), ma nei prossimi passi le incroceremo con dati sulla struttura della proteina, sulla localizzazione, sugli interattori, sulle funzioni, ecc.
Il portale da visitare per ottenere tutte le informazioni su una proteina è UniProt. Possiamo effettuare la ricerca utilizzando una ricerca testuale, oppure il nome del gene o della proteina. Utilizziamo la nostra solita parola chiave OPN1LW.
Pratica: Ricerca su UniProt
- Apri UniProt
- digitare
OPN1LWnella barra di ricerca- Selezionare la visualizzazione della scheda
Il primo risultato dovrebbe essere P04000 · OPSR_HUMAN. Prima di aprire la pagina, due cose da notare:
- Il nome della proteina
OPSR_HUMANè diverso dal nome del gene, così come i loro ID sono. - Questa voce ha una stella dorata, il che significa che è stata annotata e curata manualmente.
Pratica: Aprire un risultato su UniProt
- Fare clic su
P04000 · OPSR_HUMAN
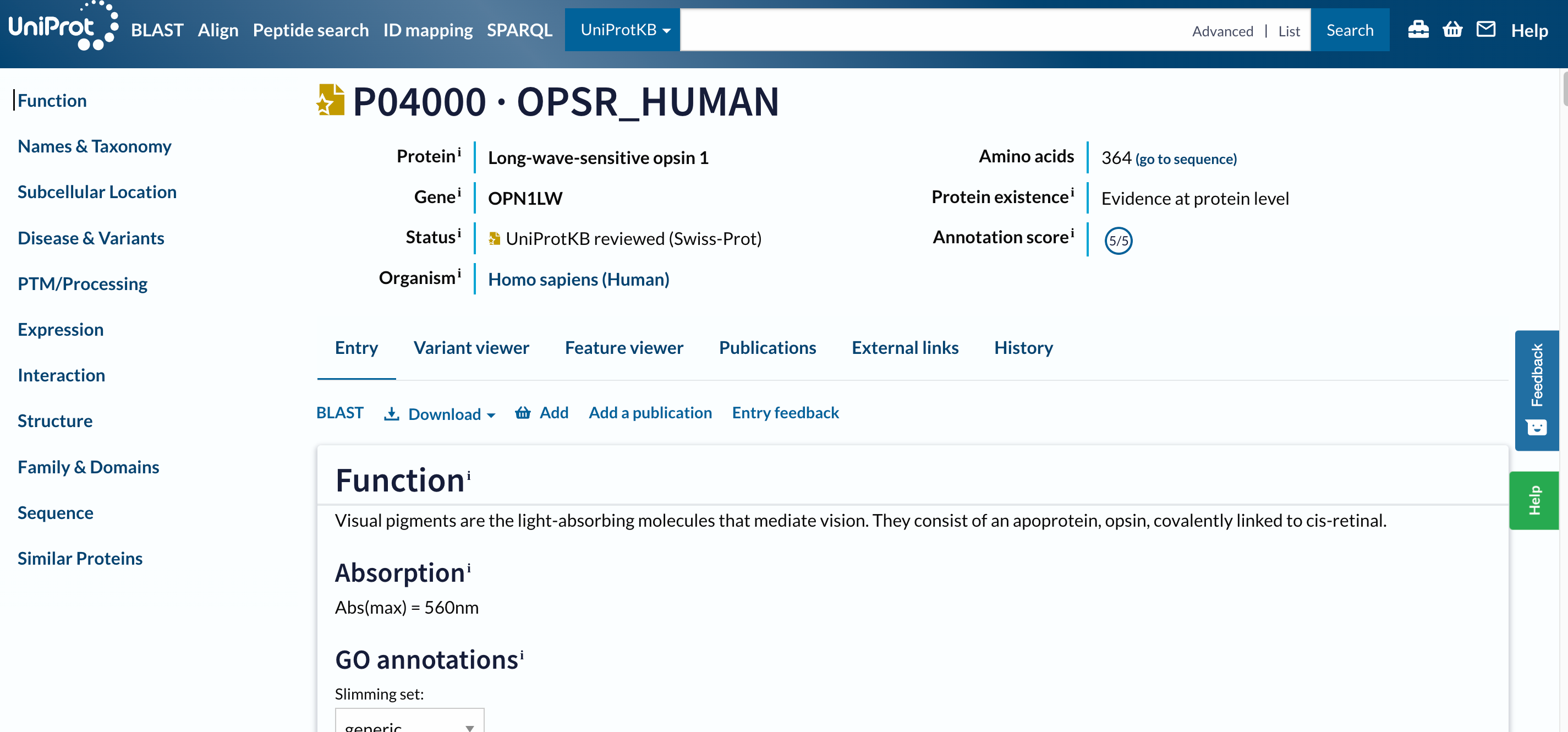 Open image in new tab
Open image in new tabQuesta è una pagina lunga con molte informazioni, per cui abbiamo progettato un intero tutorial per esaminarla.
Hai completato il tutorial
Punti chiave
È possibile cercare geni e proteine utilizzando testo specifico sul genoma NCBI.
Una volta trovato un gene o una proteina rilevante, è possibile ottenerne la sequenza e l’annotazione in vari formati da NCBI.
È inoltre possibile ottenere informazioni sulla posizione cromosomica e sulla composizione esone-introne del gene di interesse.
NCBI offre uno strumento BLAST per eseguire ricerche di similarità con le sequenze.
È possibile esplorare ulteriormente le risorse incluse in questo tutorial per saperne di più sulle condizioni associate ai geni e sulle varianti.
È possibile inserire un file FASTA contenente una sequenza di interesse per le ricerche BLAST.
Domande frequenti
Hai domande su questo tutorial? Dai un'occhiata alle FAQ disponibili e ai canali di supportoRiferimenti
- Rangwala, S. H., A. Kuznetsov, V. Ananiev, A. Asztalos, E. Borodin et al., 2021 Accessing NCBI data using the NCBI sequence viewer and genome data viewer (GDV). Genome research 31: 159–169. 10.1101/gr.266932.120
Feedback
Hai usato questo materiale come istruttore? Sentiti libero di lasciarci un feedback. Com'è andata.
Hai usato questo materiale come studente? Clicca sul modulo qui sotto per lasciare un feedback.

Citare questo tutorial
- Lisanna Paladin, Bérénice Batut, Teresa Müller, Imparare a conoscere un gene attraverso risorse e formati di dato biologici (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-gene/tutorial_IT.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{data-science-online-resources-gene, author = "Lisanna Paladin and Bérénice Batut and Teresa Müller", title = "Imparare a conoscere un gene attraverso risorse e formati di dato biologici (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/data-science/tutorials/online-resources-gene/tutorial_IT.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Riferimenti
Queste persone o organizzazioni hanno fornito supporto finanziario per lo sviluppo di questa risorsa
Congratulazioni per aver completato con successo questo tutorial!You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/data-science/tutorials/online-resources-gene/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: ncbi_blast_plus owner: devteam revisions: 0e3cf9594bb7 tool_panel_section_label: NCBI Blast tool_shed_url: https://toolshed.g2.bx.psu.edu/