Phylogenetics is essential for comparing biological species and understanding biodiversity for conservation. This tutorial discusses the basic principles and methods of phylogenetic inference and what you can learn from phylogenetic estimation. It is intended to help you make informed decisions about which methods to use in your research.
Introductory Lecture: Welcome and why phylogenetics?
This content is available in multiple, equivalent formats. Choose your preferred format below.
Using real-life data and standard tools that are (mostly) available in Galaxy, the tutorial demonstrates the principles behind a variety of methods used to estimate phylogenetic trees from aligned sequence data or distance data.
This is not just a “how to” tutorial, but is instead aimed at giving you a better understanding of the principles of phylogenetics and how the methods work. Maybe you’ve even built phylogenetic trees before but want to know more about the principles behind the tools.
This tutorial does not cover workflows for taking read data to phylogeny or Bayesian methods. We’ve included recommended reading and tutorials on these topics in the resources section.
We’ve designed this tutorial with flexibility in mind and so that you can focus on the sections that are relevant to you. It includes videos that explore key concepts, written descriptions of each concept, and exercises that demonstrate the methods in action using tools (mostly) available in Galaxy. The exercises are beginner level, but you should know how molecular sequence data is produced and what it looks like. Depending on how you like to learn, you can choose to watch the videos, read the text, work through the exercises, or a combination of the three!
This tutorial is adapted from a 2019 workshop run by the Australian BioCommons and Professor Michael Charleston (University of Tasmania).
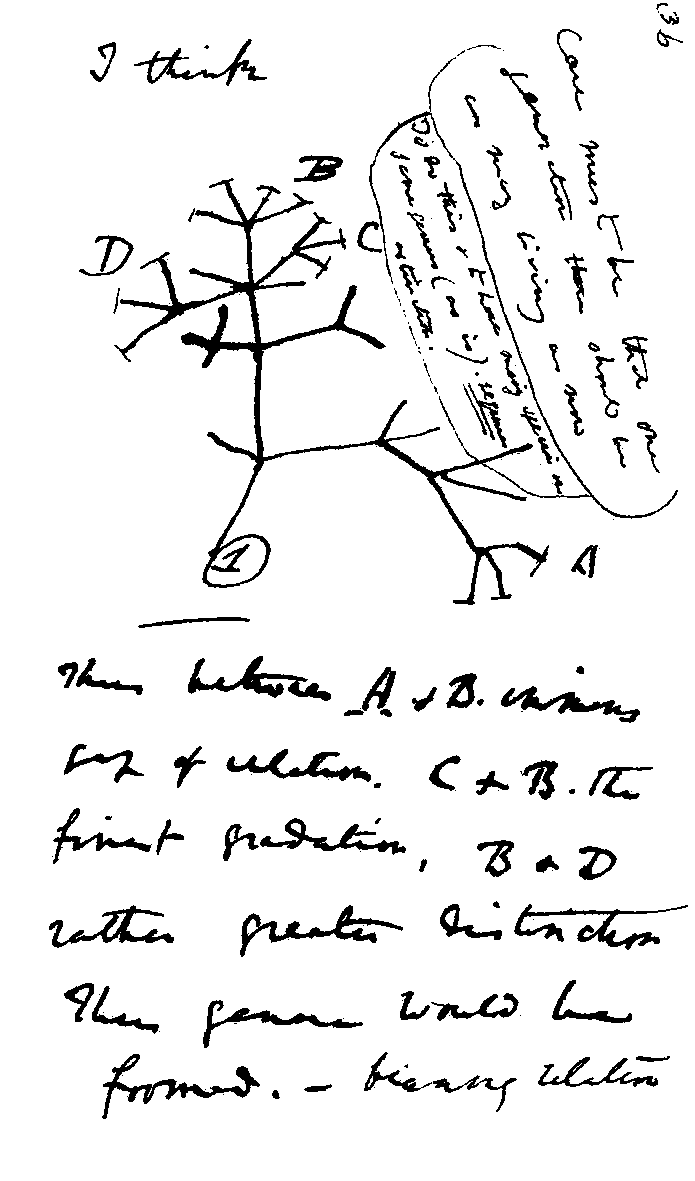
Figure 1: Charles Darwin's first sketch of an evolutionary tree. Source: Wikimedia commons
A phylogenetic tree, also called a phylogeny, is usually a tree-like structure, like Darwin’s famous sketch. The leaves or tips of the tree represent extant (living/existing) taxonomic entities like species, genera, or strains (in general called “taxa”). The lines connecting taxa describe the evolutionary relationships between them.
The intersections of lines correspond to hypothetical ancestral taxa. They represent branching events when species split into two new species, or a strain developed a phylogenetic important offshoot strain, etc.
The phylogeny of a group of taxa is the best representation of their evolutionary relationships.
It is also the main basis on which we can build statistics comparing species: without the phylogeny, comparing species (or strains, genera, etc.) is not meaningful.
As Theodosius Dobzhansky famously wrote, “Nothing in biology makes sense except in the light of evolution”Dobzhansky 1973.
Why we need phylogenetics
There are many ways in which we can use phylogenetic analyses, from the most fundamental understanding of the evolutionary relationships that exist between a set of species, as in Charles Darwin’s famous sketch, to families:
Figure 3: A modern view of the tree of life based on sequenced genomes. Hug et al. 2016 reproduced under Creative Commons Attribution 4.0 International License
Aside from gaining a fundamental understanding of biology, other reasons for inferring phylogenetic relationships include:
Designing vaccines, for example for SARS-CoV2 and influenza;
Measuring phylogenetic diversity for guiding conservation efforts;
Understanding coevolution; for example, around 70% of emergent human diseases have come from other species;
Dating major evolutionary events to study the effects of environmental change on different species.
Comment: Gene trees, species trees reconciliation problem
It’s worth noting that getting the phylogeny from a set of genes – what we often call a gene tree – might not give us the true phylogeny of the species that house those genes, even if we get everything right!
This happens because there are other processes that can influence the so-called “gene tree” such as:
lateral gene transfer events
gene duplication
gene loss and incomplete lineage sorting
recombination
The situation where gene trees and species trees differ is often called the “gene tree / species tree reconciliation problem”.
While it is a fascinating topic, it is beyond the scope of this tutorial. Today we will work under the assumption (which is reasonable for the dataset we will use) that the gene tree will reflect the species relationships.
Terminology
video From the root to the tips, watch the video to explore common features of phylogenetic trees. See how these features relate to evolutionary patterns and how outgroups can be used to find the root or common ancestor of extant species.
Lecture: Phylogenetics Terminology
This content is available in multiple, equivalent formats. Choose your preferred format below.
It’s common to call phylogenetic tree a phylogeny.
Mathematically, a tree is a kind of graph, which has objects called nodes or vertices (lavender, white, and blue boxes in the figure above), connected in pairs by things called edges (green and orange lines in the figure above).
Trees are a natural way to think about phylogenetic relationships. The nodes correspond to taxa, and the edges, also called branches, show the relationships between them, where taxa could be species, or lineages, genera, populations, or even individuals if we are considering something like a genealogy.
Nodes with only one edge attached to them are called leaves (or tips; in white above) and correspond to taxa with no descendant taxa in the tree. These taxa might be from fossils, or, be currently living, in which case they’re referred to as extant.
Internal nodes (in lavender above) correspond to hypothetical common ancestors of the extant taxa: the set of descendants that each one has determines the tree.
Many phylogenies have a special node assigned as the common ancestor of all the taxa represented by the leaves in the tree. This node is called the root (in blue above). When this is the case, a natural direction is implied from the root to the tips, going forward in time. We call such trees and phylogenies rooted; if there is no root, they are called unrooted.
The majority of phylogenetic inference methods produce unrooted trees, but rooted trees are more useful.
In a rooted phylogeny, all the leaves that are descendant from any given node form a monophyletic clade, or often just “clade” (monophyletic means “one tribe (of) origin” from the Greek).
One way to determine where the root of a tree belongs is to include an outgroup in the data, which is a set of taxa that are definitely not within the clade of interest (which is then called our ingroup) but which share a common ancestor with that clade. A good outgroup won’t be too distantly related to our ingroup, because if it’s too distant, choosing where it should connect to the ingroup will be hard, ultimately resulting in a guess.
You can see in the diagram above that the connection of the ingroup to the outgroup could be from multiple locations. Once the unrooted tree is created, using combined data from ingroup and outgroup taxa, we can confidently say that the root is on the branch connecting our ingroup to our outgroup:
We can then imagine lifting up the unrooted tree at the branch connecting our outgroup and ingroup – that is our best guess at the hypothetical ancestor of all our taxa and gives us a good indication of the branching order of our ingroup (and the outgroup):
Figure 6: 'Lifted' tree demonstrating hypothetical ancestor and branching order
Phylogeny estimation can be thought of as inferring a collection of compatible hypotheses about monophyly – that is, statements that groups of taxa descendant from a common ancestor are each others’ closest relatives in the tree.
The tree above is called a binary tree, because each internal node branches into two descendants. It is a very common assumption that trees are binary, and we make that assumption in this tutorial. In fact, it is often very hard to come to a means by which a phylogeny could be truly non-binary: in most cases, this is just due to our inability to resolve the tree completely.
Building a tree
Basic Methodology
So, how do we estimate phylogenetic trees?
We start with the leaves of the tree which can be living (extant) or older taxa:
Figure 7: The 'leaves' of a tree (extant or older taxa) are the starting point for buidling phylogenies
There are several ways to estimate a tree, such as:
Go with what we think is the case already (this is not recommended!)
Attempt to build a tree based on similarity and dissimilarity, with tools such as Neighbor-Joining (NJ) or FastME (we will do this later in the tutorial)
Use a score function, such as Parsimony or Maximum Likelihood, to build potential trees and find the best one (we will do this later too)
Something else entirely (Perhaps networks or even inferring evolution based on the parasites of your species of interest!).
Warning: Finding an optimal tree is hard!
First and foremost, phylogenetic inference is a statistic estimation process.
Different estimates of the phylogenetic tree relating a given set of species may differ, even if no errors were made.
It is generally not possible to prove that any tree inferred is correct – since we cannot go back in time and observe speciation events.
Comment: Common evolutionary assumptions used in phylogenetic estimation
We will (mostly) make these assumptions in this tutorial!
Evolution is “memoryless.” This assumption is that the future evolutionary trajectory of an organism is not affected by its past. This means we can use the powerful mathematics of Markov processes.
Phylogenetic relationships can be correctly represented by a tree! This isn’t always assumed, but it is very common. Trees are a very attractive representation of evolution, and it is part of our language: “The tree of life” is a common phrase. However evolution is not always explained by a tree-like, “branching” process as other events such as hybridisation and sharing of genetic material can influence envolutionary processes.
The molecular clock assumption is that sequences in a clade evolve at about the same rate. This is known to be wrong, but is useful. For instance, there is variation in evolutionary rate between lineages, but if this variation is not significant, we can ignore it and use simpler models, to better leverage the phylogenetic information in the data.
Lineages don’t interact – once they have speciated, they are independent of each other. This isn’t always the case and we know that biological lineages do interact with each other – but our methods are generally not able to manage such complexity. The vast majority of methods make this assumption, particularly if the evolution is also assumed to be tree-like.
Challenges
Phylogenetic Inference is Hard.
One of the things that make it hard is the sheer number of possible trees that can describe relationships among species.
The number of rooted binary trees grows as 1, 3, 15, 105, 945, 10395… in fact the formula for this number for \(n\) taxa (we use `taxa’ in general, since not all phylogenetic inference is at the species level) is \((2n-3)!! = (2n-3)(2n-5)...(3)(1),\) which grows as fast as \(2^{n}n!\).
The table below gives you an idea of the scale we are dealing with.
The Number of Unrooted Binary Trees
n
# trees
notes
3
\(3\)
trivial to check
4
\(15\)
enumerable by hand
5
\(105\)
enumerable by hand on a rainy day
6
\(945\)
enumerable by hand during lockdown
7
\(10395\)
easily searched by computer
8
\(135135\)
a bit more than the number of hairs on your head
9
\(2027025\)
population of Sydney living west of Paramatta
10
\(34459425\)
comparable with the number of possible tickets in a typical lottery
20
\(\approx 8.2\times 10^{21}\)
getting slow for computers even with branch-and-bound
48
\(\approx 3.21\times 10^{70}\)
number of particles in the universe-ish
136
\(\approx 2.11\times 10^{267}\)
number of trees to choose from in the first “Out of Africa” data set
Calculating distances
Building a tree begins with a set of distances, which record how different the taxa are from each other.
Distances have very desirable properties, that can be summarised as follows: for any objects \(x\), \(y\), \(z\), writing \(d(x,y)\) means the distance from \(x\) to \(y\) etc. These properties are:
non-negativity – distances can never be negative, and in fact we treat two things as identical if they have a distance of 0 between them.
symmetry – the distance from \(x\) to \(y\) is the same as the distance from \(y\) to \(x\); that is, \(d(x,y) = d(y,x)\).
the triangle inequality – there are no short-cuts! The distance from \(x\) to \(z\) is always at most the distance from \(x\) to \(y\) plus that from \(y\) to \(z\); that is, \(d(x,y) + d(y,z) \leq d(x,z)\).
In phylogenetics terms, we like distances to represent something like time and we can assign lengths to branches (see the Tree Anatomy diagram above).
Distances can be calculated based on a variety of data. Here is a flow-chart of the process:
The blue boxes on the left show some of the input data forms. The most commonly used kind of data in modern phylogenetics is aligned molecular sequences – typically, DNA, RNA, or Amino Acids (AA) from equivalent (homologous) genes in the species of interest. We focus on this form of molecular phylogenetics in this tutorial.
Other input data forms are distances or dissimilarity measures based on molecular-based measures like DNA-DNA hybridisation, gene presence/absence, and morphology (physical dimensions). We will not discuss this kind of data in this tutorial.
Aligned sequences can be converted into distances (green box above), using models for how the sites (i.e. specific nucleotides or amino acids) have evolved.
These distances can be expressed as a matrix D, which becomes the input for distance-based methods.
Distance-based methods (orange boxes) use algorithms to select a pair of taxa, or clades, to join together to make a new clade. Once that decision is made, the two taxa / clades that have been joined are replaced with the clade that the two of them make together as seen in the figure below.
In this tutorial we will use a set of Anolis lizard DNA sequences, from Jackman et al. 1999 to trial some phylogenetic methods.
The sequences are from the mitochondrial NADH dehydrogenase subunit 2 gene (ND2) and five transfer RNA (tRNA) genes, with an average sequence length of 1419.109 and a range of [1329,1727].
We are using a relatively small set of sequences to ensure the methods run quickly for the purposes of the tutorial.
In the real world, a phylogenetic analyses often span hundreds, or even thousands, of taxa. Phylogenetic estimation on this many sequences is computationally very intensive, and can take weeks of time even on a high-performance computer.
Get the data
Hands On: Obtain your data
Make sure you have an empty analysis history. Give it a name.
To create a new history simply click the new-history icon at the top of the history panel:
Import the file anolis-raw.fst from Zenodo or from the shared data library.
You may need to refresh your history to show the data.
If the paste/fetch link does not work for you, you can download it to your own computer and then upload it using the “Upload” button at the top of the left panel in Galaxy.
Copy the link location
Click galaxy-uploadUpload at the top of the activity panel
Select galaxy-wf-editPaste/Fetch Data
Paste the link(s) into the text field
Press Start
Close the window
You can click on the ‘eye’ icon galaxy-eye on the right to see the unaligned data (go ahead!) but the view isn’t very informative. This is the raw FASTA file, with the symbols A, C, G, T representing nucleotides. You can see that the sequences are different lengths.
FASTA or Fasta format (pronounced to rhyme with pasta) format is is commonly used as input to phylogenetic inference programs and has a very simple structure, as follows:
Each sequence has a name, which appears on its own line after a ‘>’ sign
The next line(s) contain the sequence; continuing either until the next sequence name line, or the end of the file.
The example below has four sequences in it named Taxon_1, Taxon_2, etc, each with a short set of characters representing DNA sequences.
The Fasta format can also include symbols such as a question mark ‘?’ for missing data, or hyphen ‘-‘ to indicate an insertion or deletion events, collectively indels. It is common to represent a multiple sequence alignment in Fasta format with these symbols. It is also a common format for storing high-throughput read data, but without quality scores – if you want to include read quality you would use FASTQ format.
Hands On: View your data
Let’s view the unaligned sequence in a more understandable form.
Click on the title of your file to see the row of small icons for saving, linking etc:
Click on the visualise icongalaxy-visualise and then select the Multiple Sequence Alignment tool.
You should see something like this:
Play around with the view. You can change colour schemes and add or remove various elements. Good colour schemes for nucleotide data are “Clustal2” and “nucleotide”.
If you cannot see the slider at the top (for moving left or right in the view) you will need to check the “Show residues indices” in the “Vis. elements” drop-down menu.
Do not adjust the scale slider! Currently, this breaks the page.
Question: Understanding the FASTA file
How many sequences are there in your data?
How long is the longest sequence, and what is it?
What about the shortest sequence?
There are 55 sequences. The longest is from Anolis paternus with length 1729 nucleotides; the shortest is A. luciae with length 1252.
Sequence Alignment
video Watch the video to find out
[0:00] What ‘alignment’ really means and why it is useful for phylogenetics; [6:22] What makes a good alignment; [12:15] How pairwise sequence alignment and dynamic programming work; [33:47] How the multiple sequence alignment algorithms work; and to
[40:00] explore multiple sequence alignment of the Anolis sequences with SeaView.
Lecture: Sequence alignment
This content is available in multiple, equivalent formats. Choose your preferred format below.
Molecular sequences must be aligned before they can be used to build phylogenies.
Aligning sequences amounts to finding the nucleotide positions (sites) that we can be confident have the same evolutionary history: they correspond to each other across species and can be considered to have evolved from the same common ancestor.
A good clue to identify these sites, which are called homologous, is that they are well conserved, with only a few changes.
Below is an example of an alignment. On the left are the sequences in Fasta format.
In the middle we see an alignment of those sequences, which has gaps in it that help line up the sites so that more of them agree.
A sign of a “good” alignment is one in which the colours line up vertically. The overhanging parts can be removed as seen in the “trimmed version” on the right.
While aligning two sequences is “easy”, in the sense that an optimal alignment between two sequences can be found in a reasonable amount of time, optimally aligning multiple sequences is computationally intractable. Multiple sequence alignment is a complex process and many methods have been developed to tackle this challenge.
Aligning sequences with MAFFT
Today you will be aligning sequences using a modern multiple alignment program called MAFFT, which is available on Galaxy.
Hands On: Sequence alignment with MAFFT
In Galaxy, search for and select the MAFFT ( Galaxy version 7.508+galaxy1) from the tool finder on the left, and run it with the following parameters:
param-file In the MAFFT tool, the Sequences to align field should already be filled with your unaligned data. If it isn’t, select it using the drop-down menu.
In the Data type field select “Auto detection”.
Leave the MAFFT flavour as “fftns”. This is a good default.
In the Matrix selection select “No matrix”.
Click “Run tool”.
Here is a visualisation of the resulting alignment. Note that the colours are now vertically aligned:
Click on the title of the completed MAFFT job to show the row of small icons for saving, linking etc.
Click on the visualise icongalaxy-visualise
You will be presented with a couple of options. Select “Multiple Sequence Alignment”.
Your alignment is displayed!
The colour scheme is horrible to start with because it’s not automatically detecting the data as DNA sequences. Click on the “Color scheme” button and select “Clustal2” for a nicer picture.
You can click and drag the display of nucleotides in the upper panel, and when you go far enough to the right you’ll see some gaps have been introduced by MAFFT. On either side of each gap you should see that the nucleotides match up pretty well. This is because the MAFFT algorithm has identified that these site are homologous, and that either an insertion event has happened for a group of sequences, or a deletion happened in the others.
You may be tempted to play around with “Vis. elements” and show the scale slider - don’t! It’s currently broken and will crash your browser tab :(.
You should ALWAYS visually check your alignment to see if it makes sense.
A tool you can use on your own computer is SeaView.
Distance-based phylogenetic inference
video Watch the video to delve into the mathematics of building phylogenetic trees from distances. [0:00] Why use distances and how they relate to the structure of a phylogenetic tree
[3:05] Types of distances and distance matrices
[11:31] The mathematics behind the Jukes-Cantor/JC69 and HKY85 models [16:04] An example of building a tree from ultrametric distances [21:01] Building a tree from non-clocklike distances with the Neighbour-joining method [25:59] Real life data and limitations for building trees from distances.
Lecture: Phylogenetic Trees
This content is available in multiple, equivalent formats. Choose your preferred format below.
We are going to build our first tree, using a very common method called Neighbor-Joining. This method was created in the 1980s by Saitou & Nei (Saitou and Nei 1987).
Building a Neighbor-Joining Tree
The Neighbor-Joining (NJ) algorithm is a standard method that takes a set of distances between taxa as input, and sequentially connects them into larger and larger clusters until all taxa have been joined.
NJ is rarely used as a complete tool for phylogenetic analysis. Although it is quite accurate and fast, there are other fast methods that can be then applied to modify the NJ tree and create a better one.
The FastTree2 program that we are using does this. First it creates a “rough” NJ tree, and then modifies it to optimise a quantity called Minimum Evolution (ME) (more on this later). A detailed description of how FastTree works is available from Microbes online.
Hands On: Build a Neighbour-Joining Tree with FastTree
Search for the FastTree ( Galaxy version 2.1.10+galaxy1) in the tool finder on the left, and run it with the following parameters:
“Aligned sequences file (FASTA or Phylip format)”: fasta
param-file“FASTA file”: outputAlignment (output of MAFFTtool)
“Protein or nucleotide alignment”: Nucleotide
“Nucleotide evolution model”: Jukes-Cantor + CAT
“Show advanced options”: Yes
“Use constant rates?”: Use constant rates.
“Turn off maximum-likelihood.”: Yes
Click on “Run tool”.
It won’t take very long for FastTree to build your tree.
But when it’s done, how can you see it?
Clicking on the ‘eye’ icon galaxy-eye of the output doesn’t at first appear to be very illuminating: it’s just a parenthesised list of taxon names and numbers.
This is Newick Format, and it’s worth knowing at least a little of what it means.
Each matched pair of parentheses denotes a cluster or subtree: “(A,B)” means that A and B are each others’ closest relatives (also called sister taxa).
A number after a cluster (so, after a closing parenthesis) is a label for that cluster. In the output from FastTree, this label is an indicator of the support for that branch.
If there is a colon ‘:’ followed by a number, then this is the branch length for the subtree.
The rooted, 3-taxon trees above have three taxa, labelled A, B and C. Two of the internal nodes have been labelled (x and y), but it isn’t necessary to do so in general (for example, if you wanted to use the label for something like support of each branch, as does FastTree).
In both trees, A and B are sister taxa, and branch lengths are indicated near each branch: you can see how the branch lengths are above each cluster, including the individual taxa (the “leaves” of the tree), but not above the root.
The Newick format for the tree on the left is “((A:3, B:2)x:2, C:6)y;” and for the one on the right it is “((A:3, B:2)x:3, C:5)y;”. The number after each colon is the length of the branch above it (closer to the root).
Note that these two trees are very similar: they only differ in the position of the root (y), either being distance 2 from node x, or being 3 from it. The distance between any two nodes in the tree is the sum of the branch lengths on the path connecting them, so for the trees above, the distance matrix is
A
B
C
A
0
5
11
B
5
0
10
C
11
10
0
Ideally, these will reflect the actual input distances, but such distances are based on messy real data, and do not necessarily obey this ideal.
That is why methods like FastTree are employed to find a tree with the best possible agreement between the distance inferred, and that calculated from sequence data.
Hands On: Visualising a tree
To visualise your tree in Galaxy:
Search for the Newick Display ( Galaxy version 1.6+galaxy1) in the tool finder on the left, and run it with the following parameters:
“Newick file”: param-file: tree.nhx (output of FastTreetool)
“Branch support”: Display branch support
“Branch length”: Display branch length
“Choose an ouput format”: PNG
Click on the display icongalaxy-eye next to the title of the completed Newick Display job to display your tree.
Notice that there are quite a lot of long branches adjacent to the extant taxa (leaves) and that these branches are much shorter near the centre of the tree.
Note: Short branches are much harder to get right.
Additional visualisation options
To build a radial tree, rerun Newick Display and choose the “Draw a radial tree”: Yes option.
Alternatively you can visualise your tree outside of Galaxy by downloading your FastTree output and using software such as SplitsTree or FigTree. These tools provide additional options for interactively exploring and customising the appearance of your tree.
(If you wish you may of course re-run FastTree and allow it to seek a Maximum Likelihood tree – maybe once you’ve learned more about Maximum Likelihood.)
Searching for the “best” tree
The other way we can estimate a phylogeny is by choosing some kind of score of “goodness” and then searching the entire set of possible trees for the tree (or trees) that optimises this score.
Note that such scores are “surrogates for truth” in that we hope the optimal score will correspond to the true tree, but it is not necessarily the case. In many analyses we therefore use multiple methods, in the hope that they will give us the same answer. Minimum Evolution (ME), Maximum Parsimony (MP), and Maximum Likelihood (ML) are common such score functions.
Comment: Data vs Method
If your conclusion changes based on your reasonable choice of analytical method, then perhaps your data are not adequate.
Minimum Evolution (ME)
Minimum Evolution is the idea that the sum of the branch lengths should be as small as possible to still account for the distances between the leaves of the tree, in that the sum of squared differences between the distances implied by the tree and the observed distances from the data, is minimised. You can read more about this in an article by Rzhetsky and NeiRzhetsky and Nei 1993.
There are some variations on this ME criterion and FastTree uses an approximation of one of them to find good trees.
Maximum Parsimony (MP) and Parsimony Length
Most tree estimation methods output trees with branch lengths that correspond to the amount of evolutionary “work” that has to be done to turn one sequence into another.
This can be given as the minimum number of character state changes required – the so-called parsimony length – to convert the (hypothetical) sequence at one end of a branch to that at the other end.
The Maximum Parsimony method is based on this approach.
Finding the parsimony length of a site pattern is easy and fast due to a clever algorithm created by Walter Fitch; hence, finding the score (the “goodness”) of a tree is fast. But finding the tree that minimises this score is still computationally intractable, because the space of trees is so huge.
The Maximum Parsimony method for finding the “best” tree is to search tree space for the tree (or trees) that minimises the parsimony length of any tree for that alignment. Note that when parsimony is maximised, this means the fewest possible changes required, so the minimum length.
We do not use the Maximum Parsimony method in this tutorial.
Maximum Likelihood (ML)
video Watch the video to learn about [0:00] the concept of likelihood and how it lends statistic rigour to phylogenetic analysis as well as [26:45] how it is applied in models like Jukes-Cantor, HKY85 and GTR models to select the “best tree” from your data. [34:16] Wander through tree space to find the best tree using Nearest Neighbour Interchange, Subtree Pruning and Regrafting, and Tree Bisection and Reconnection tree perturbations and [45:40] go “hill climbing” with tree-search algorithms. [48:52] Finally, explore the output of IQTree for the Anolis dataset used in the tutorial.
Lecture: Maximum Likelihood & Trees
This content is available in multiple, equivalent formats. Choose your preferred format below.
Likelihood is the most statistically defensible phylogenetic inference method.
It is based on the idea that the tree that has the highest probability of producing the sequences at the tips of the tree is the tree that is the “most likely” to be correct: this is called the Maximum Likelihood (ML) Tree.
Likelihood is not the same as probability, though they are often confused with each other. However, it is proportional to the probability that the tree is correct, out of the set of possible trees and models you are considering.
One major, almost ubiquitous, assumption about molecular sequence data is that each site evolves independently of all other sites. Biologically, this isn’t always the case, but in practice, this makes things much more tractable, and we still have a good chance of getting the tree(s) right.
Another assumption we make is that the substitution rate – the rate at which changes of nucleotide at a given position in the sequence happen – is only dependent on the current state, i.e., we do not care about how a sequence came to be what it is, only what the sequence is now, to determine what are the probable evolutions of it.
This seems much more biologically reasonable and makes this into a Markov process, which in turn enables a lot of calculations to be made simply.
Searching for trees and their branch lengths
When dealing with nucleotides A, C, G, T, there are 4x4 rate matrices with different names: Jukes-Cantor (JC69) with one parameter, Hasegawa-Kishino-Yano (HKY85) with five parameters, and many more, that define the rates at which nucleotides change.
There are other 20x20 matrices for amino acids, and even 64x64 matrices for codons.
To convert from a rate to a probability, hence giving us a likelihood, requires that we have a branch length. Then, we can calculate the probability under a given model, and after a specific time interval, of going from one nucleotide to another. We multiply these site probabilities to calculate the probability of going from an entire sequence to another.
Thus, looking for the optimal tree under likelihood requires we also search for the best-fit branch lengths, as well as looking for the best tree.
Maximum Likelihood is therefore the slowest tree inference method we discuss in this tutorial.
Models of sequence evolution
If you are in a hurry to do the phylogenetic analysis you can skip this section and go to the next Hands-on: running IQ Tree.
Likelihood is based on probability, so requires we choose a probabilistic model for the evolution of sequences.
The simplest model for DNA is that each nucleotide has the same rate of change, and that all nucleotides appear with equal frequency (called the base frequencies) of 25%, 25%, 25%, 25%. This is the Jukes-Cantor (JC69) model published in 1969, and this model has just one parameter.
More biological realism allows for different nucleotide proportions outside the uniform 25% rate. This is the Felsenstein 1981 model, known as F81, and it has three more parameters for the rates (not four: given the first three base frequencies, this defines the other one).
A next level of sophistication is the Hasegawa-Kishino-Yano model (HKY85) published in 1985, which acknowledges that transitions (changes of state within the purines A, G or within the pyrimidines C, T) occur more readily than transversions (changes from purine to pyrimidine or vice versa).
Hence the HKY85 model has an additional parameter of these different types of subtitution: it can be represented by the substitution rate matrix below:
In the above, the \(\pi\) symbol is used for the base frequencies, and a \(\kappa\) symbol is used for the transition/transversion ratio parameter. The asterisk “*” is a short-hand to mean “the sum of everything else in the row.”
A more general model still is the General Time-Reversible model (GTR), in which each substitution type has its own rate. It still keeps the property that a substitution from \(x\) to \(y\) has the same probability as one from \(y\) to \(x\) (this comes from the “reversible” property) but otherwise all rates are independent of each other:
A further level of sophistication is the recognition that some sites may be constrained from changing at all. For example, there may be some that have a critical role in fixing the correct amino acid for a protein to function. This addition to the above methods is known as “invariable” sites and is usually represented by a “+I” appended to the model name.
The last level of sophistication is that some sites may evolve faster than others, even if they are under the same kind of model with the same parameters in the matrix \(Q\).
The most common way to allow for this is to imagine that the relative rate for a particular site is drawn from a Gamma \(\Gamma\) probability distribution, which has some nice properties like allowing most sites to change very slowly and permitting some to change rapidly.
This is usually denoted by a “+\(\Gamma\)” or “+G” appended to the model name.
There are many more models, with many more parameters and constraints. Finding the best one to fit a data set is a complex task!
Fortunately there are tools that help determine the most appropriate model for a given data set, such as the Akaike Information Criterion (AIC) and some variations of that.
The program IQTree, which we use later, performs a step to determine which model is most appropriate for your data set, based on AIC and other schemes to avoid over-fitting while still having as good a fit to your data as possible.
In that step, trees, and their likelihoods based on your data, are estimated for many different models. Each yields a likelihood score but rather than simply take the model that maximises the likelihood, over-complex models are penalised, to avoid over-fitting. One such penalty function is the AIC; there are others.
There are whole books describing this process, and it’s clearly well beyond the scope of this tutorial to go into such depth, but now you should have some appreciation of what is going on behind the scenes when an Maximum Likelihood method is looking for the best model for your data.
Assessing the Quality of trees
A tree-building method will, of course, build you a tree.
But what if your data are not even from a tree? Or, what if the data are from sequences that are so distantly related that they are virtually independent of each other and are essentially random?
It is important that, once you have estimated a tree, you assess how reliable it is.
Remember that a phylogeny is a collection of hypotheses of relatedness. Each branch separates some of the taxa from the others, and if the branch is above a subtree it corresponds to a hypothesis that the taxa in that subtree are monophyletic with respect to the other taxa in the rest of the tree (as shown in Figure 1.).
This means that it is meaningful to assess the reliability of branches of your tree, in addition to just assessing it overall.
Resolution
A good phylogenetic tree is one that is well resolved – that is, every time a lineage branches, it forms two new branches.
Equivalently, every internal node has three edges touching it.
An unresolved node may be a true representation of the branching pattern of a group of lineages. For example, this is generally the case for very rapid diversification, such as during an island radiation (species arrives in new place with lots of niches; diversifies incredibly quickly).
In phylogenetics unresolved nodes are more often due to a lack of resolving power in the data, so the phylogenetic method cannot choose the branch ordering:
If there are many unresolved branches in the phylogeny, this is an indication that there is not enough information in your data: you’ll need to obtain more.
Bootstrapping
A very common (and useful) method for dealing with unresolved branches is called bootstrapping, which is a technique that has a solid basis in statistics (not just phylogenetics). The idea is that one resamples with a replacement data set to create a “pseudoreplicate” that is analysed in the same way as the original data. This process is then repeated many times to create a distribution. Bootstrapping is known to be a is a good way to measure the internal consistency of a data set, and its use in phylogenetics is well established.
The naive method for bootstrapping is called “non-parametric” and works by effectively resampling the patterns at each site in the alignment, creating a pseudo-alignment of the same total number of sites, then re-building the tree.
IQTree has a very - ultra - fast bootstrapping method that is cleverer and works a bit better than the naive method. When we use IQTree in the next part of the tutorial, we will also do bootstrapping on the tree. See Minh et al. 2020 for details on the method.
Bootstrapping can be done on any inference method. We will use the likelihood method that searches for the tree and branch lengths that maximises the likelihood for (1) our actual data, and then (2) for each of the pseudoreplicates, noting for each of these which branches occur in the best trees found.
By keeping track of which branches occur in the best trees found for each of the pseudoreplicates, we can note how often the branches in the best tree for our actual data occur in the resampled data. If they occur a lot – say, 80% of the time or more – then we can be fairly sure that that branch is well supported by the data.
Bootstrap values therefore appear for each branch, and are most often expressed as a percentage or proportion. Branches at the leaves that occur in every possible tree so these would get 100% bootstrap values every time, and don’t tell us anything.
(Note: FastTree does not do bootstrapping natively, but can in conjuction with other tools (see details). It’s fiddly to do this so we will not try it in this tutorial.)
Estimating a Maximum Likelihood tree with IQTree
IQTree is a state-of-the-art cross-platform program that uses maximum likelihood to find optimal phylogenetic trees.
It can perform model selection and bootstrapping.
And it’s on Galaxy!
Hands On: Estimating a Maximum Likelihood tree with IQTree
Find the IQTree ( Galaxy version 2.1.2+galaxy2) program in the tool finder, and run it with the following parameters:
In “General options”:
param-file“Specify input alignment file in PHYLIP, FASTA, NEXUS, CLUSTAL or MSF format.”: your aligned sequence data (output of MAFFTtool)
“Specify sequence type as either of DNA, AA, BIN, MORPH, CODON or NT2AA for DNA, amino-acid, binary, morphological, codon or DNA-to-AA-translated sequences”: DNA
In “Modelling Parameters”:
In “Rate heterogeneity”:
“Write maximum likelihood site ratios to .mlrate file”: Yes
In “Bootstrap Parameters”:
In “Ultrafast bootstrap parameters”:
“Specify number of bootstrap replicates (>=1000).”: 1000
Click “Run tool”.
To visualise your tree in Galaxy, search for the Newick Display ( Galaxy version 1.6+galaxy1) in the tool finder on the left, and run it with the following parameters:
“Newick file”: param-file: MaxLikelihoodTree (output of IQTreetool)
“Branch support”: Display branch support
“Choose an ouput format”: PNG
Click on the display icongalaxy-eye next to the title of the completed Newick Display job to display your tree.
Alternatively you can visualise your tree outside of Galaxy by downloading your IQTree output and using software such as SplitsTree or FigTree. These tools provide additional options for interactively exploring and customising the appearance of your tree.
Figure 17: The resulting tree found by IQTree, displayed using Newick Display.
Observe that the bootstrap values (in red) in the IQTree output for deep branches are not as high.
Note that bootstrap values for UFBoot (provided by IQTree) are actual estimates of the probability that the branch is correct, so are not quite the same as traditional “naive” bootstrap values.
With the visualisation open answer the following questions:
Question: How well supported is your tree?
What are the bootstrap values near the root of the tree? Do you think those branches are well supported?
Which do you think is the biggest well-supported clade?
Are there some nodes that would be better left unresolved?
Is your tree “probably right”? – or 80% right?
Near the base of the tree the bootstrap values are high: mostly around 100%. These appear to be well supported. Since they’re near the root, there are some very large well-supported clades, e.g., all the way from A. disticus near the top, down to A. lineatus near the bottom. There are a number of poorly supported clades within this clade though, with some low bootstrap values; the smallest of these is just 29% for the clade from C. barbouri to Diplolaemus darwinii.
Overall the tree looks well supported, but it’s probably wrong somewhere. It would be worth seeking more data, molecular or morphological, to resolve those poorly supported clades.
Report on the final tree
Look at the IQTree Report file.
In that you will see a long list of models that have been tested, with the favoured one at the top.
You will also see the Newick Format of the best tree found. When I ran it, the best model was “GTR+F+R6”, which means the General Time-Reversible
Question: Understanding the IQ-Tree report
What is the second-most favoured model?
How many relative rates of evolution have been estimated, and what are these rates?
The second-best supported model is GTR + F + R7: it’s almost identical to the first model, but with one more rate category.
There are 6 relative rates, in the table with columns Category, Relative_rate and Proportion: the rates are 0.01936 (very slow), 0.1952, 0.6315, 1.365, 2.662, and the fastest, 7.146. Very few sites are estimated to be in this category - about 2.3% - whereas about 27% of the sites are deemed to be in the slowest category.
The report below shows a long list of models that have been tested, and these are sorted by their AIC score.
The columns comprise the name of the model, the log-likelihood (that is, the log of the likelihood), of the best-fit tree using that model, then six more columns that are the penalised according to the number of parameters each model has, and an overall weighting of the posterior probability of each model. In the table below, the GTR+F+R6 model has approximately 81.7% of the probability mass based on AIC, but in terms of BIC, it is about 2.37% (guide at the bottom of the table).
It next shows details of the model selected, with relative rate parameters for the various substitutions (A-C is from A to C, etc.); estimated nucleotide frequencies, and then the rate categories.
In this analysis the best-fit model is GTR+F+R6:
“Model of rate heterogeneity: FreeRate with 6 categories”
… which allows for six categories of relative rates, and shows the proportion of sites estimated to be in each category.
The last thing in the report is the tree! First in the nostalgic ASCII-format “drawing,” and then the same tree in Newick format.
video Watch the video to see how SplitsTree4 can be used to explore the evidence supporting different phylogenetic splits in data from Anolis species using networks built with uncorrected P, Jukes-Cantor and HKY85 models.
Introductory Lecture: Welcome and why phylogenetics?
This content is available in multiple, equivalent formats. Choose your preferred format below.
Perhaps surprisingly, phylogenetic estimation doesn’t have to start with a tree. Instead you can start with a phylogenetic network.
Phylogenetic networks have two purposes:
to show an estimate of the evolutionary history that is not strictly branching, so, involving horizontal gene transfer or hybridisation events.
or
to show conflicting phylogenetic signal in the data set, suggesting different possible trees.
In this tutorial we use networks for the second purpose because we are working under the assumption that there is a true tree, which is the actual evolutionary history of our species of interest.
To understand what this kind of phylogenetic network is, and how to interpret one, we need to think about what the branches of a tree do. Branches split the taxa into two groups: those on one side of the branch, and those on the other. We are thinking about unrooted trees in this context, so the two branches coming from the root constitute a single split.
Thus every branch of a tree can be thought of as a split and a tree is a collection of compatible splits: where by “compatible” we just mean that they can be on the same tree.
So our tree search is an attempt to find a “best” set of splits that are all compatible, and which together explain the evolutionary relationships among the taxa of interest.
However, the data may support multiple splits that are not compatible. For example, we might have a set of nucleotide sequence data like this:
In this table the sequence is listed in full in the second column, then broken up into different categories in subsequent columns.
The first four sites are constant, so don’t tell us anything much about the phylogeny.
The next four singleton sites segregate one taxon from the others (which is again not terribly useful in terms of resolving the branching in the phylogeny).
The so-called “parsimony informative” sites start at site 9. These sites tell us about the support for the internal branches of the tree.
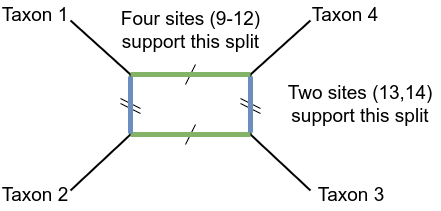
Sites 9-12 suggest splitting the taxa into (1,2) vs (3,4). We write this as a split \(12\vert34\) for brevity, or even just 12.
The next two sites, numbers 13 and 14, suggest the split (2,3) vs (1,4), which we could write as \(23\vert14\) or \(14\vert23\) or just 14.
The last site suggests that taxa 1 and 3 should go together.
Figure 18: Splits in a simple phylogenetic network
In the above figure we have four taxa 1,2,3,4, in a phylogenetic network.
The pairs of parallel lines correspond to two of the splits that could separate taxa from each other, and which could (separately) appear in phylogenetic trees.
The green, horizontal branches separate taxa 1 and 2 from 3 and 4; the split \(12\vert34\). These are longer than the blue, vertical ones, which separate taxa 1 and 3 from 2 and 4: the split \(13\vert24\).
The beauty of the network is that both thes pieces of information can be shown on the same figure, despite them not being compatible – they can’t both be on the same tree.
Note: SplitsTree 4 is an older version, but works well. SplitsTree 6 is in development but appears to work equally well (at the time of writing). They do the same thing, and we only use tools common to both versions. Installing either version takes a minute or two.
Download the aligned data .FASTA file (the output of MAFFT) to your own computer.
Start up SplitsTree and open the file. Within moments you should see something like this (using SplitsTree 4):
Click on some of the interior branches, which will highlight sets of parallel lines, that correspond to each split that is shown in the network.
This network shows a number of deep branches that are quite well resolved, in the sense that they have very long, thin parallelograms, but there is a jumble of very small parallelograms in the centre of the network, indicating that there is not a lot of information in the data to determine the early branching order of the Anolis phylogeny.
Note that the initial distance measure is using “Uncorrected P” distance, which is simply the proportion of sites that differ between each pair of sequences. It is possible to use more sophisticated models for maximum likelihood, such as Jukes-Cantor and HKY85.
Click on the Distances menu and select “HKY85”. A dialog box will appear with some options. Click “Apply” and get a network like this:
The above shows you that the basic structure of the network does not change very much using different distance measures. This is a good thing because it means reasonable assumptions you make about your data are not drastically changing the results.
Finally, perform a bootstrap analysis on this network. Click on the Analysis menu and select Bootstrap. Leave the default number of replicates as 1000 and click “run”.
After a few seconds (less than a minute) you should see something like this:
This network shows the percentage of times out of those 1000 replicates that each split was in the network created for each replicate.
Zoom in (there is a magnifying glass tool at the top) and scroll around the figure to see which are the strongly supported splits, which should correspond to the well supported bootstrap values in the trees you inferred above.
Troubleshooting
Here are a few things that can catch us out:
Be wary of long branches that come out together in the estimated phylogeny. This can be the result pairs of sequences that are very different from the rest, so match each other “by chance” more than they match the rest.
Fix: break up these long branches by adding in some taxa that are closely related to one or the other; remove one long branch at a time to see where the remaining one fits best; consider other methods that are more robust to LBA.
Sequences that are hard to align might contain many gaps and many equally “good” alignments.
Fix: Try different multiple alignment programs; consider using “alignment-free” methods such as k-mer distances; remove very problematic regions using programs such as GBlocks (also available on Galaxy).
Low bootstrap support or lots of conflict in a network.
Fix: Look at which sites support which splits (internal branches); consider sliding window approaches to identify recombination, or check that your sequences don’t span regions with different selection pressures; consider using PartitionFinder or similar methods to work out which sets of sites have similar evolutionary dynamics.
Fix: They might not need fixing: it might just be that the genes’ evolutionary histories aren’t the same as those of the species that host them. Look at all the gene trees and see what other events might have led to the differences between them.
Fix: Consider mid-point rooting: it is in most cases pretty good.
Summary
Phylogenetics provides the statistical framework that is essential for comparing biological organisms. A phylogenetic tree provides a best estimate of the evolutionary relationships between species (taxa) of interest, which is the framework we need to compare them.
A key component of molecular phylogenetics is creating an alignment – this is a complex process that can have different outcomes using different methods. It is always a good idea to look at the alignment to see if it makes sense: has the alignment program included the insertion/deletion events which are consistent with a phylogenetic relationship between the species?
While estimating phylogenetic trees is computationally challenging, there are a range of well-validated methods to use, constructing them based on distances, molecular sequences, and other data; these can also be used to create phylogenetic networks that represent the complexities in the data. There is an extensive range of scoring functions by which we can compare trees, including: Minimum total distance (minimum evolution); the maximum amount of evolutionary “work” to account for the data (maximum parsimony); or by finding the model that has the highest probability of giving us the data we saw (maximum likelihood).
It’s important to remember that these are all statistical estimates, so they may differ, and it is good advice to use multiple methods to confirm general phylogenetic relationships rather than choose a single method.
We can use Bootstrapping to calculate a measure of confidence for clades in trees based on molecular sequences. Bootstrapping involves representative independent re-samples of the input alignment which are analysed again using the same methods, 100s to 1000s of times, to gauge how reliable each branch is, in the sense of how often the branch is part of the best tree found for each re-sample. This isn’t a measure of confidence in the statistical sense, but a rule of thumb of 80% or more being “good support” is common in the literature – remembering that as sequences get longer and longer, bootstrap support values go up, no matter how poor the data are!
It’s worth noting that this tutorial is only focusing on the estimation of individual best trees rather than taking a Bayesian approach in which a posterior probability of trees is created, using programs like MyBayes or BEAST. These programs use even more computational resources and can run for many days or weeks as they wander around “tree space”, building up a representative distribution of the probability that each tree is “right”. This computational burden is one of the main reasons we have not gone into Bayesian methods in this tutorial. Still, many good examples are available online on the web pages for the above programs.
We hope that this tutorial and accompanying videos have given you a better understanding of the principles of phylogenetics and how these methods work, which will help you make informed decisions about the phylogenetic analyses you perform.
See the resources below to learn more about phylogenetics.
Resources
To develop a deeper understanding of phylogenetic trees, there is no better way than estimating phylogenies yourself — and work through a book on the topic at your own pace.
Books
Phylogenetics in the genomics era, 2020. An open access book covering a variety of contemporary topics.
Tree Thinking, 2013, by David A. Baum & Stacey D. Smith
SplitsTree or FigTree can be used to visualise phylogenetic trees outside of Galaxy. These tools provide additional options for exploring and customising your trees.
Dobzhansky, T., 1973 Nothing in Biology Makes Sense except in the Light of Evolution. The American Biology Teacher 35: 125–129. http://www.jstor.org/stable/4444260
Saitou, N., and M. Nei, 1987 The neighbor-joining method: a new method for reconstructing phylogenetic trees. Molecular Biology and Evolution 4: 406–425. 10.1093/oxfordjournals.molbev.a040454
Rzhetsky, A., and M. Nei, 1993 Theoretical foundation of the minimum-evolution method of phylogenetic inference. Molecular Biology and Evolution 10: 1073–1095. 10.1093/oxfordjournals.molbev.a040056
Jackman, T. R., A. Larson, K. de Queiroz, and J. B. Losos, 1999 Phylogenetic Relationships and Tempo of Early Diversification in Anolis Lizards. Systematic Biology 48: 254–285. 10.1080/106351599260283
Rainford, J. L., M. Hofreiter, D. B. Nicholson, and P. J. Mayhew, 2014 Phylogenetic distribution of extant richness suggests metamorphosis is a key innovation driving diversification in insects. PloS one 9: e109085. 10.1371/journal.pone.0109085https://europepmc.org/articles/PMC4183542
Minh, B. Q., H. A. Schmidt, O. Chernomor, D. Schrempf, M. D. Woodhams et al., 2020 IQ-TREE 2: New Models and Efficient Methods for Phylogenetic Inference in the Genomic Era. Molecular Biology and Evolution 37: 1530–1534. 10.1093/molbev/msaa015
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{evolution-abc_intro_phylo,
author = "Michael Charleston",
title = "Phylogenetics - Back to basics (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/evolution/tutorials/abc_intro_phylo/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Congratulations on successfully completing this tutorial!
You can use Ephemeris's shed-tools install command to install the tools used in this tutorial.
5 stars:
Liked: The materials presented and resources provided where put together well. I liked that questions could be asked throughout the presentation and that I could ask basic questions without feeling like they were too basic. I think the content was well pitched for someone like me who had phylogenetic training 20 years ago. I liked the breadth of the content covered but my knowledge is so poor that it did overwhelm me towards the end. That was expected though.
Disliked: Although I can see the workshop can't go any longer, as my brain couldn't cope, I did struggle towards the end to keep pace with everything. Having said that, it was good to get the breadth of content in and I will enjoy revisiting the resources provided to consolidate the knowledge. A follow up workshop is really needed as the distance matrices and the best models to choose seemed like they needed more time spent on them.
June 2024
4 stars:
Disliked: Please Provide the way to plot a mid point root tree.
May 2024
5 stars:
Liked: It was clear and well handled from basics to hands on tutorial
Disliked: I would add an aminoacid sequence example
Questions:
 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tab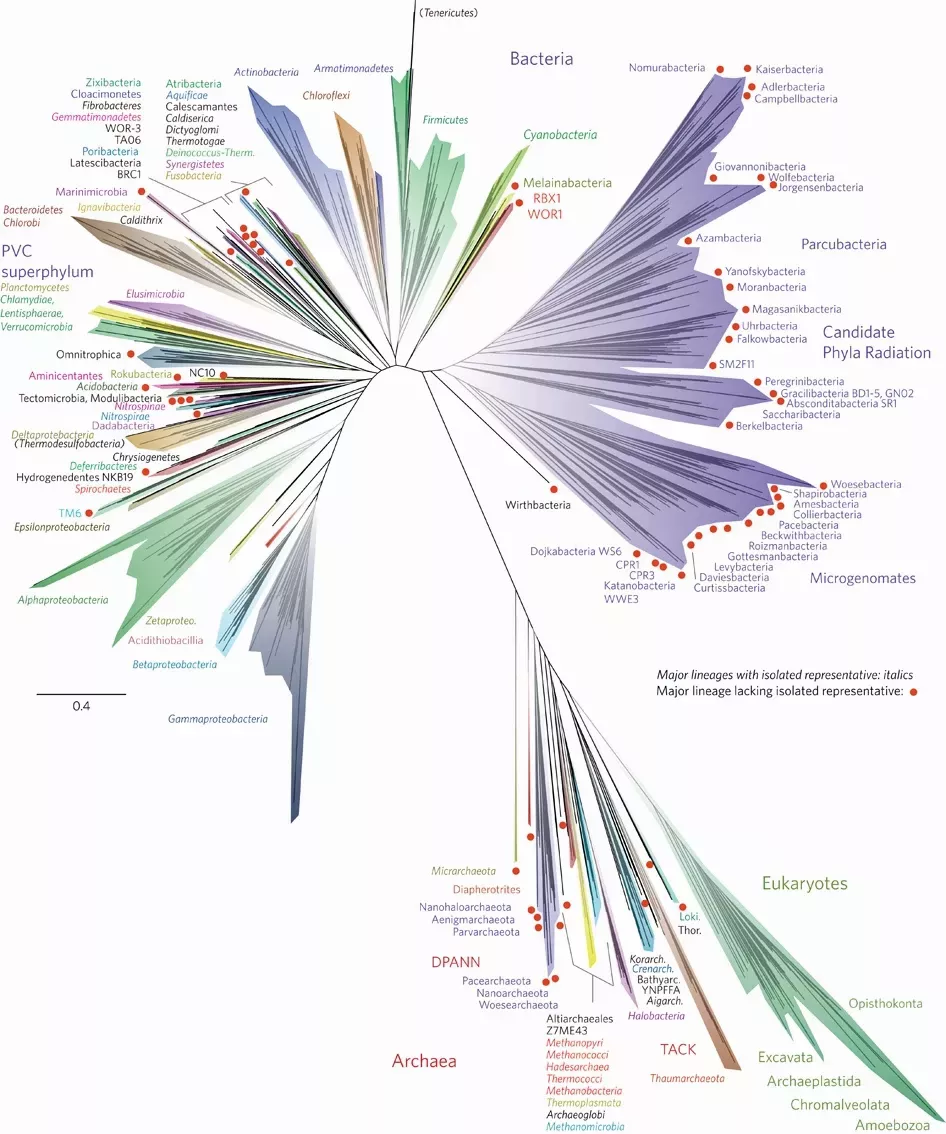 Open image in new tab
Open image in new tab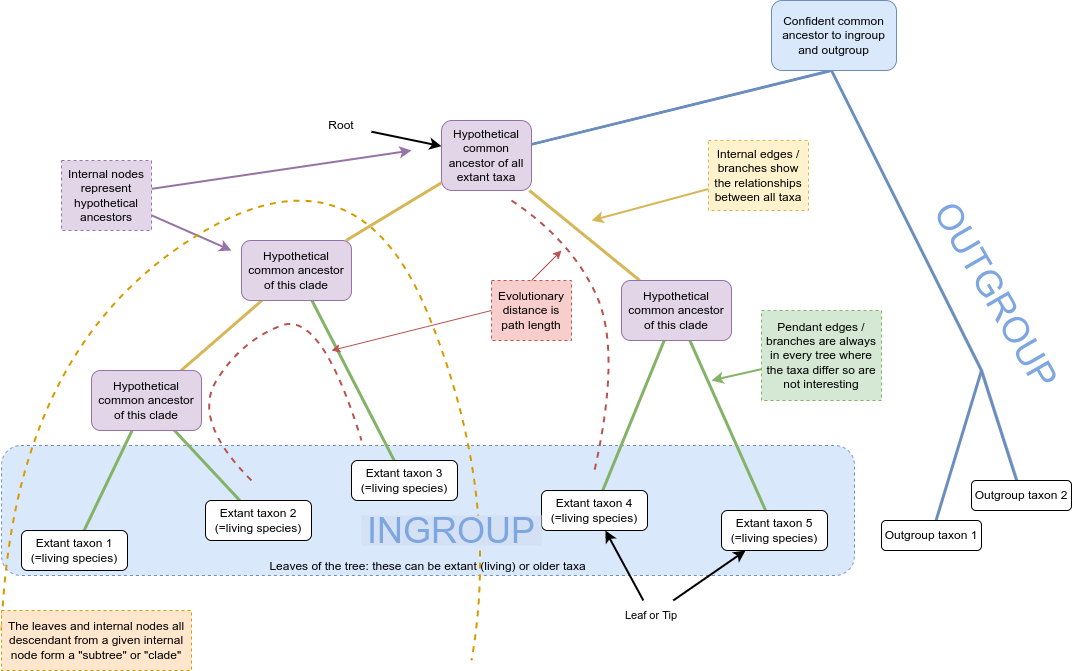 Open image in new tab
Open image in new tab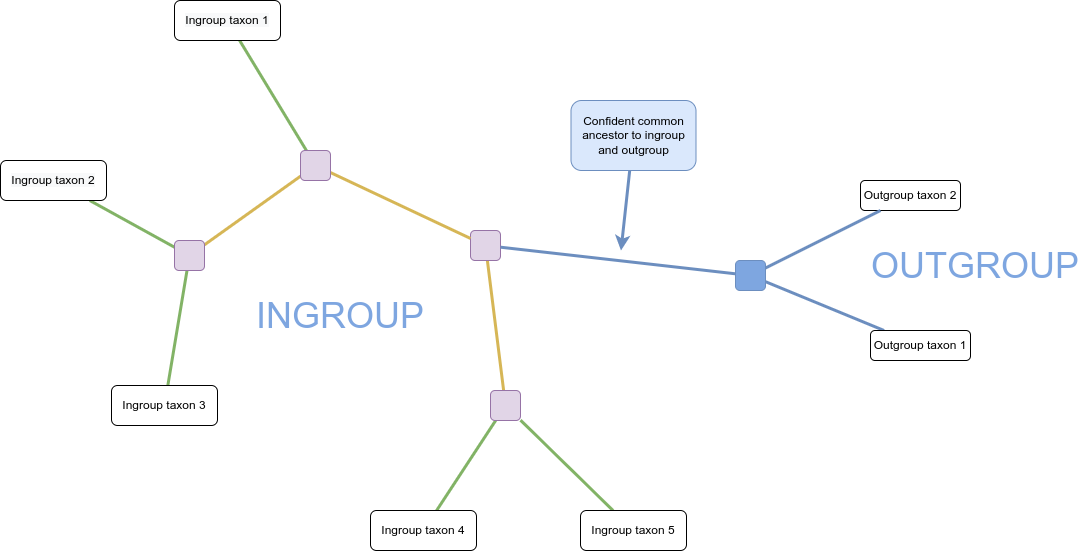 Open image in new tab
Open image in new tab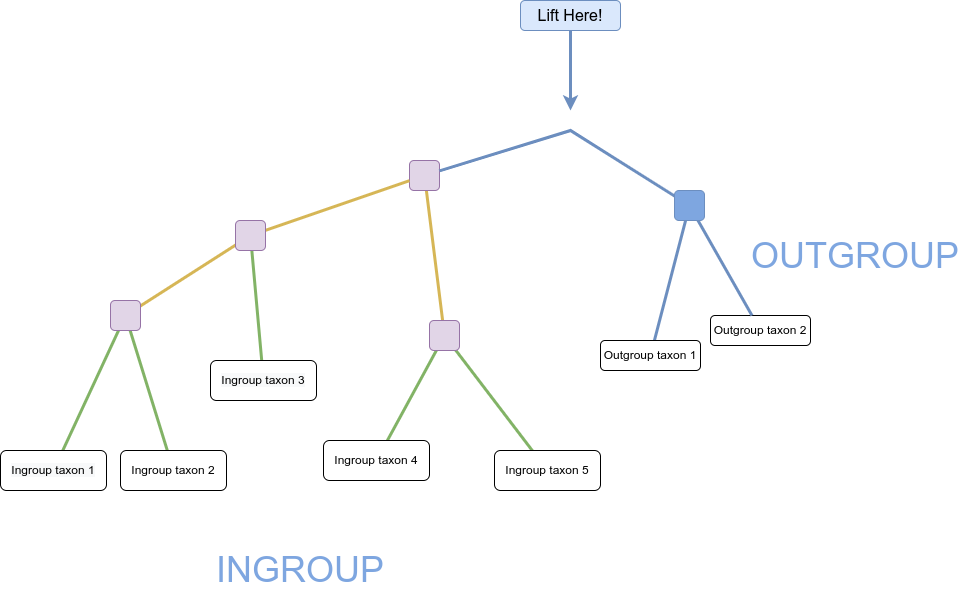 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tab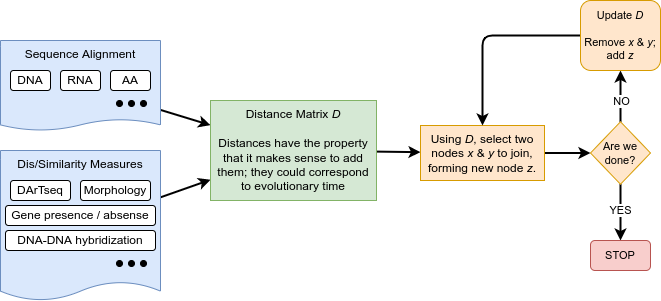 Open image in new tab
Open image in new tab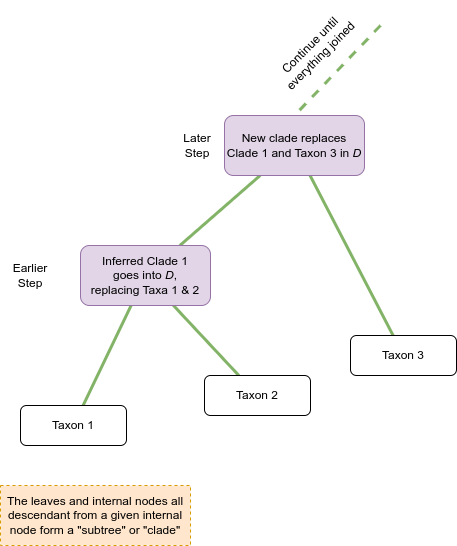 Open image in new tab
Open image in new tab


 Open image in new tab
Open image in new tab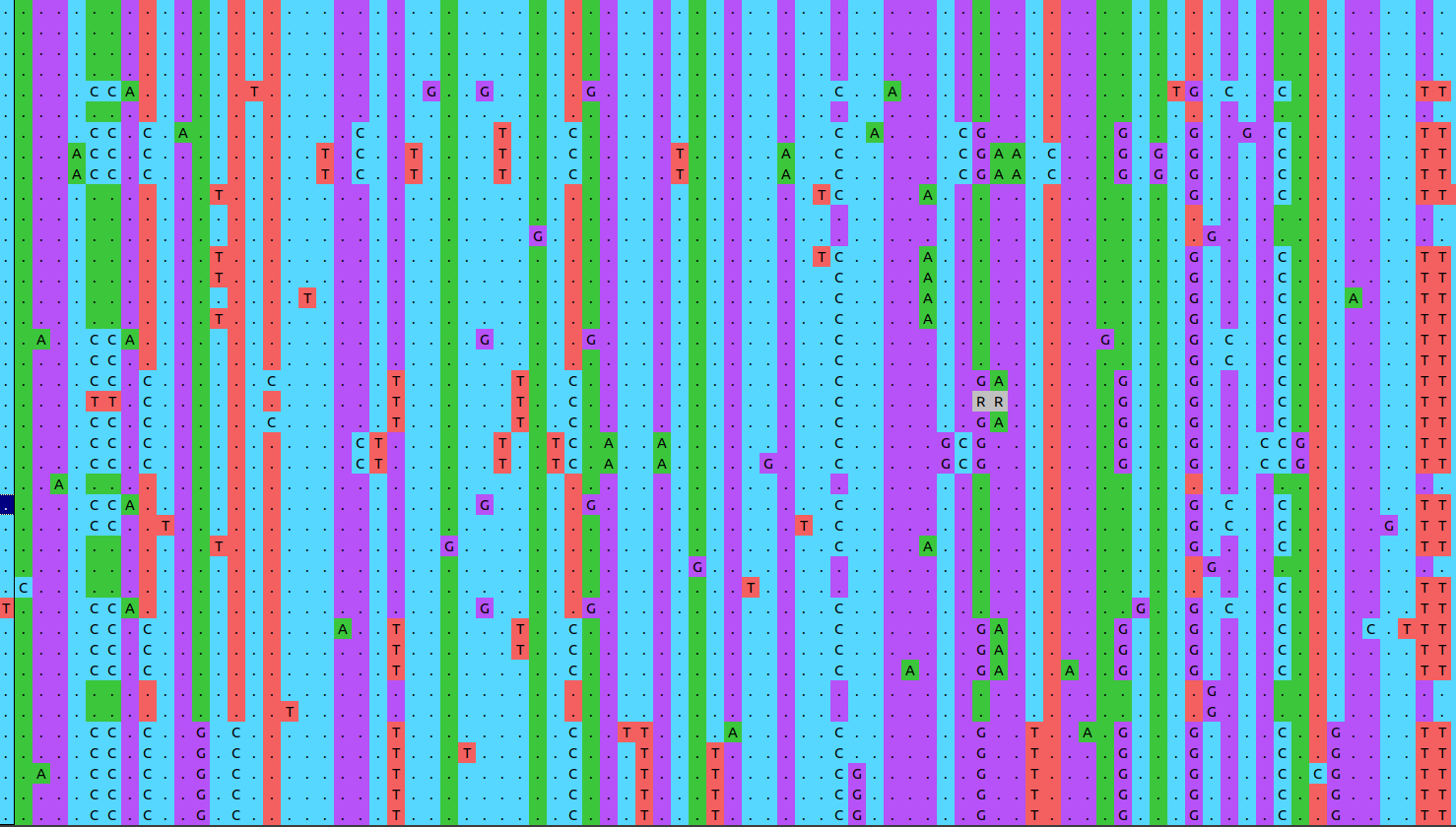 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tab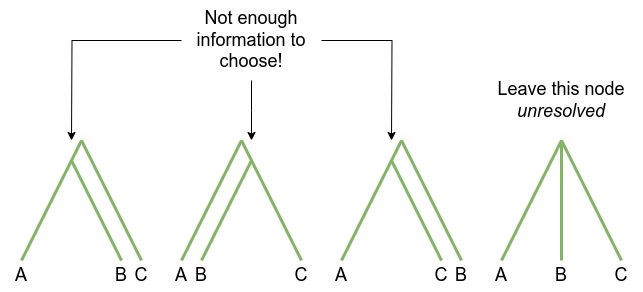 Open image in new tab
Open image in new tabOpen image in new tab

 Open image in new tab
Open image in new tabClick on some of the interior branches, which will highlight sets of parallel lines, that correspond to each split that is shown in the network. This network shows a number of deep branches that are quite well resolved, in the sense that they have very long, thin parallelograms, but there is a jumble of very small parallelograms in the centre of the network, indicating that there is not a lot of information in the data to determine the early branching order of the Anolis phylogeny.
The above shows you that the basic structure of the network does not change very much using different distance measures. This is a good thing because it means reasonable assumptions you make about your data are not drastically changing the results.
This network shows the percentage of times out of those 1000 replicates that each split was in the network created for each replicate. Zoom in (there is a magnifying glass tool at the top) and scroll around the figure to see which are the strongly supported splits, which should correspond to the well supported bootstrap values in the trees you inferred above.
