From small to large-scale genome comparison
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How can we run pairwise genome comparisons using Galaxy?
How can we run massive chromosome comparisons in Galaxy?
How can we quickly visualize genome comparisons in Galaxy?
Requirements:
Learn the basics of pairwise sequence comparison
Learn how to run different tools in Galaxy to perform sequence comparison at fine and coarse-grained levels
Learn how to post-process your sequence comparisons
Time estimation: 2 hoursSupporting Materials:Published: Feb 8, 2021Last modification: Jul 31, 2024License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00176rating Rating: 5.0 (0 recent ratings, 2 all time)version Revision: 8
Sequence comparison is a core problem in bioinformatics. It is used widely in evolutionary studies, structural and functional analyses, assembly, metagenomics, etc. Despite its regular presence in everyday Life-sciences pipelines, it is still not a trivial step that can be overlooked. Therefore, understanding how sequence comparison works is key to developing efficient workflows that are central to so many other disciplines.
In the following tutorial, we will learn how to compare both small and large sequences using both seed-based alignment methods and alignment-free methods, and how to post-process our comparisons to refine our results. Besides, we will also learn about the theoretical background of sequence comparison, including why some tools are suitable for some jobs and others are not.
This tutorial is divided into two large sections:
- Fine-grained sequence comparison: In this part of the tutorial we will use
GECKO(Torreno and Trelles 2015) to perform sequence alignment between small sequences. We will also identify, extract and re-align regions of interest. - Coarse-grained sequence comparison: In this part of the tutorial, we will tackle on how to compare massive sequences using
CHROMEISTER(Pérez-Wohlfeil et al. 2019), an alignment-free sequence comparison tool. We will generate visualization plots for the comparison of large plant genomes and automatically detect large-scale rearrangements.
AgendaIn this tutorial, we will cover:
Fine-grained sequence comparison
Imagine you are working on an evolutionary study regarding the species Mycoplasma hyopneumoniae. In particular, you are interested in the strains 232 and 7422 and wish to compare their DNA sequence to know more about the evolutionary changes that took place between both. The workflow you will follow starts with (1) acquiring the data, (2) getting it ready for Galaxy, (3) running the comparison and (4) inspecting and working with the resulting alignments. Let’s go!
Preparing the data
First we will be uploading the data to Galaxy so that we can run our tools on it.
Hands On: Mycoplasma data upload
Create a new history for this tutorial and give it a descriptive name (e.g. “Mycoplasma comparison hands-on”)
To create a new history simply click the new-history icon at the top of the history panel:
- Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
- Type the new name
- Click on Save
- To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
Import
mycoplasma-232.fastaandmycoplasma-7422.fastafrom Zenodo.https://zenodo.org/record/4485547/files/mycoplasma-232.fasta https://zenodo.org/record/4485547/files/mycoplasma-7422.fasta
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
As default, Galaxy takes the link as name, so rename them.
Rename the files to
232.fastaand7422.fastaand change the datatype if needed tofasta(Galaxy will auto-discover the format of the files).
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select your desired datatype from “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button


If you were successful, both sequences should now be available as .fasta datasets in your history.
Question
- What do you think about the size of the sequences in regards to the difficulty of comparing them? (You can check the size of the files by clicking on the information icon)
- It always depends on the focus of our study. For instance, if we were looking for optimal alignments, two 1 MB sequences are indeed large enough to make most approaches either fail or take a decent amount of time and resources. On the other hand, if we were looking for seed-based local alignments (e.g.
GECKOorBLAST(Altschul et al. 1990) ), the comparison would require merely seconds (check the slides for more information).
As we discussed in the previous section, running optimal aligning tools on such “small” data can be difficult (in fact, tools such as the well-known EMBOSS needle will require cuadratic amounts of time and memory, whereas tools such as EMBOSS strecher will require quadratic time (Myers and Miller 1988)). These limitations can make it impractical in many situations. Therefore, we will now learn how to overcome these limitations by employing seed-based methods, particularly GECKO.
Running the comparison
We will now run a comparison between Mycoplasma hyopneumoniae 232 and Mycoplasma hyopneumoniae 7422 in Galaxy using GECKO.
Hands On: Comparing two mycoplasmas with GECKO
- GECKO ( Galaxy version 1.2) with the following parameters
- param-file “Query sequence”:
232.fasta- param-file “Reference sequence”:
7422.fasta- “K-mer seed size”:
16- “Minimum length”:
50- “Minimum similarity”:
60- “Generate alignments file?”:
Extract alignments (CSV and alignments file)- Check out the files that have been generated, i.e. the
CSVand theAlignmentsfile.Question
- What information is provided in the
CSVfile?- And in the
Alignmentsfile?- What happens if we re-run the experiment with other parameters (e.g. change
Minimum lengthto5000andMinimum similarityto95)?
- The
CSVfile contains a summary of the detected High-Scoring Segment Pairs (HSPs) or alignments. The file is divided in a few rows of metadata (e.g. containing the sequence names) and one row per alignment detected. Check out theGECKOhelp (bottom of the tool tool page to know what each column does!- The
Alignmentsfile contains the actual regions of the query and reference sequence for each alignment detected. With this file, you can investigate individual alignments, find mutations and differences between the sequences, extract the aligned part, etc.- Changing the parameters affect the number of alignments GECKO will detect. In fact, if we use parameters that are too restrictive, then we might not get any alignments at all! On the other hand, if we use parameters that are too permissive, then we might get a lot of noise in the output. Thus, it is very important to understand what the parameters do. Never leave your parameters default, always know what they do! Check out the help section to get information about the parameters.
Comment: Note about parameters
- Besides the
minimum lengthandminimum similarityparameters, which are applied as a filter after the comparison is completed, thek-mer seed sizeis an internal parameter that regulates the number of seeds that can be found. A smallerk-mersize will translate into detecting more seeds, which are starting points for alignments.- Notice that this parameter must be taken into account depending on the type of sequence that we are working with. For example, if we set
k-mer seed sizeto32, thenGECKOwill attempt to find alignments that start with 32 consecutive, equally aligned base pairs between the two sequences. If your sequences are far away from each other (in terms of evolutionary distance) then it will be very hard to find such 32 consecutive base pairs!- Some advice: this parameter can affect performance greatly. For instance, setting
k-mer seed sizeto8in the case of chromosomes can require much more computing time than using for instance32. On the other hand, if we set it to32in the case of small bacterial sequences, we might not find any alignments!
Post-processing: extracting alignments
We will now use additional tools to post-process our alignments. Consider the case where you are interested in a set of DNA repeats located at a given position in the sequences.
Comment: Note about interactive exploration of alignmentsIn a different scenario where e.g. you do not know what to look for or need to find the location of particular alignments, and you need an interactive exploration, you can also use
GECKO-MGVto ease the process.GECKO-MGVgenerates a visual representation where you can zoom in and out of the alignments, select and export as FASTA, etc., find more in theGECKO-MGVarticle (Diaz-del-Pino et al. 2019) or run it with a dockerized container, as described in the GitHub repository.
For our current experiment, we will be looking for the following set of repeats:
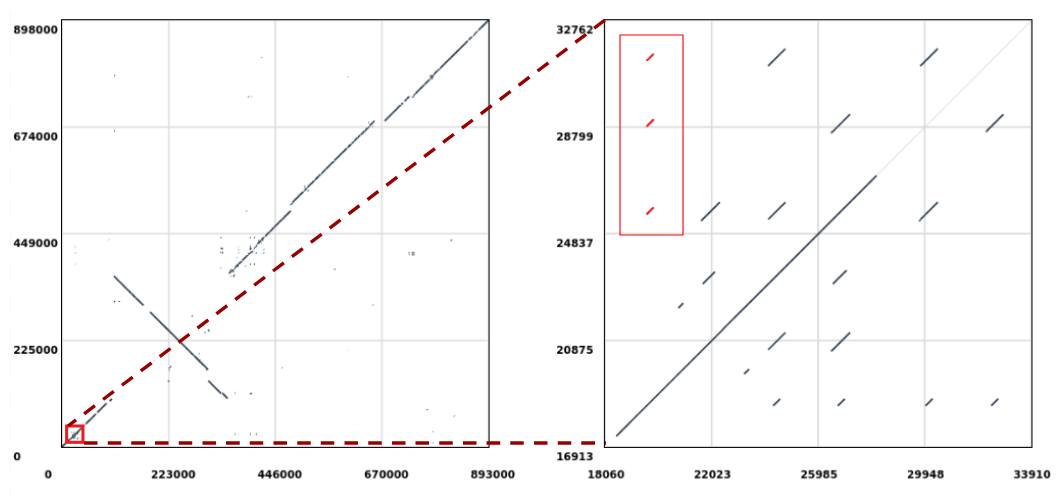 Open image in new tab
Open image in new tabLet’s extract the repeats highlighted in red (Figure 1, right) which are aligned to the position 19,610 in the query sequence and perform a multiple sequence alignment on them to check if there are any evolutionary differences. The sequences will be extracted from the reference (i.e. Mycoplasma hyopneumoniae 7422) since this is where the repeats duplicate in respect to the query sequence (notice that in Figure 1 we are selecting the ones stacked vertically).
Extracting repeat alignments and running Multiple Sequence Alignment
Hands On: Multiple Sequence Alignment of a set of repeats
- Search for the tool Text reformatting with AWK ( Galaxy version 1.1.2) and run it with the following parameters
- param-file “File to process”:
Gecko on data 2 and 1: Alignments(Note: if you have run the previous experiment with different parameters, make sure to select here the alignments file corresponding to the first experiment, and make sure you ran it with the same parameters!)- “AWK Program”:
BEGIN{FS=" "} /@\(196[0-9][0-9]/ { printf(">sequence%s%s\n", $(NF-1), $NF); getline; while(substr($0,1,1) != ">"){ if(substr($0,1,1) =="Y"){ print $2; } getline; } }(Paste this code into the text box)Comment: Note about AWKAlthough the AWK script looks a bit threatening, it is very simple:
- The
BEGIN{FS=" "}tells it to separate fields by a space.- The
/@\(196[0-9][0-9]/is a regular expression that indicates we are looking for a line containing the string@(196xxwherexxare two random digits between 0 and 9. This is used to identify the repeats that start at coordinates 19,600 to 19,699.- The previous regular expression triggers an action. The first part
printf(">sequence%s%s\n", $(NF-1), $NF); getlineprints out the sequence ID along with the coordinates and moves on to the next line.- The second part
while(substr($0,1,1) != ">"){ if(substr($0,1,1) =="Y"){ print $2; } getline;scans the next lines and prints the nucleotide sequence corresponding to theYsequence (the reference), up until a>is found, which means we are done with the sequence.Change the name of the output file
Text reformatting on data ...torepeatsChange the datatype to.fasta.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select your desired datatype from “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
- ClustalW ( Galaxy version 1.1.2) with the following parameters
- param-file “FASTA file”:
repeats.fasta- “Data type”:
DNA nucleotide sequences- “Output alignment format”:
Native Clustal output format- “Show residue numbers in clustal format output”:
No- “Output order”:
Aligned- “Output complete alignment”:
Complete alignment- Inspect the output file
ClustalW on data ... clustal.
- The file is divided into several blocks.
- Each block contains the next 50 contiguos nucleotides of each alignment in one line per sequence.
- Gaps are included.
- The asterisk symbol
*indicates that there is consensus across all sequences in the current position.- Another file
ClustalW on data ... dndis also generated which can be used to view the output alignment as a tree.
Your output alignment file ClustalW on data ... clustal should look similar to the following one (click on galaxy-eye) :
CLUSTAL 2.1 multiple sequence alignment
sequence@_19610_31252_ AAAATAAAATCAGAATTTCGTGAAAAAGCACGTAAAATAGCGACTCTTTG
sequence@_19610_28814_ AAAATAAAATCAGAATTTCGTGAAAAAGCACGTAAAATAGCGACTCTTTG
sequence@_19610_25551_ AAAATAAAATCTGAATTTCGCGAAAAAGCACGTAAAATACCGACTCTTTG
*********** ******** ****************** **********
sequence@_19610_31252_ TTTTTCACCACCGGATAAATCTTTGACTTGTTGGTTTAGTTTGTCATTTT
sequence@_19610_28814_ TTTTTCACCACCGGATAAATCTTTGACTTGTTGGTTTAGTTTGTCATTTT
sequence@_19610_25551_ TTTCTCGCCACCCGATAAATCTTTGACTTGTTGATTTAGTTTTTCATTTT
*** ** ***** ******************** ******** *******
sequence@_19610_31252_ CGATATTGAGGAAATTTGCACTTTTTTCAAGTAAGACTTGGTCAAATTCC
sequence@_19610_28814_ CGATATTGAGGAAATTTGCACTTTTTTCAAGTAAGACTTGGTCAAATTCC
sequence@_19610_25551_ CAATATTAAGAAAATTTGCTCTTTTTTCAAGCAAATTTTGATCAAATTCT
* ***** ** ******** *********** ** *** ********
sequence@_19610_31252_ CTTTTAATTATGTTATTTCCAATTAAAATATTATTTTTAACCGATAAATT
sequence@_19610_28814_ CTTTTAATTATGTTATTTCCAATTAAAATATTATTTTTAACCGATAAATT
sequence@_19610_25551_ TTTTGAATTAAGCTATTTCCAATTAAAATATTATTTTTAACAGAAAGATT
*** ***** * **************************** ** * ***
sequence@_19610_31252_ CTCAATCAAATTAAAATCTTGAAAAACTACATCAATTAAAGGGTTTTTTT
sequence@_19610_28814_ CTCAATCAAATTAAAATCTTGAAAAACTACATCAATTAAAGGGTTTTTTT
sequence@_19610_25551_ TTCAATTAGGTTAAAATCCTGAAAAACTACATCAATTAAAGGATTTTTTT
***** * ******** *********************** *******
sequence@_19610_31252_ CTTCTTTACCTT
sequence@_19610_28814_ CTTCTTTACCTT
sequence@_19610_25551_ CTTCTTT-----
*******
We can see that there are several locus along the duplicated repeats where single point mutations have taken place, and that the ending of the last repeat is missing.
So far we have learnt how to run our own custom sequence comparison, extract a set of DNA repeats and perform multiple sequence alignment on them (MSA). While this represents an common example of a bioinformatics pipeline, in the next part of the tutorial we will jump to a large-scale comparison scenario where we do not need fine-grained alignments, but instead we will be looking at the “bigger picture” using alignment-free methods.
Coarse-grained sequence comparison
In this second part of the tutorial, we are going to work with chromosome-sized sequences. While we can still use GECKO for chromosomes, it will take some more time and resources. However, consider now the case where you do not need alignments, but rather are in one of the following cases:
- You are working with a very large de novo assembly genome for which you do not know the strain and thus you need to compare it to several candidates.
- You want to study large evolutionary rearrangements at a block level rather than alignment level at several species at once.
- You want to generate a dotplot between several massive chromosomes from e.g. plants to find the main syntenies, but your sequences are full of repeats and other computational approaches fail.
As you can imagine, all three scenarios require several large-scale sequence comparisons. While there are also other ways to approach these situations, in this tutorial we will learn how we can use CHROMEISTER which is specifically designed for large-scale genome comparison without alignments (alignment-free method).
Introduction
Before jumping on the hands-on, let us see an example of the second case: say we wanted to study the evolutionary rearrangements between the grass and common wheat genomes (Aegilops tauschii and Triticum aestivum). The following plot shows the comparison:
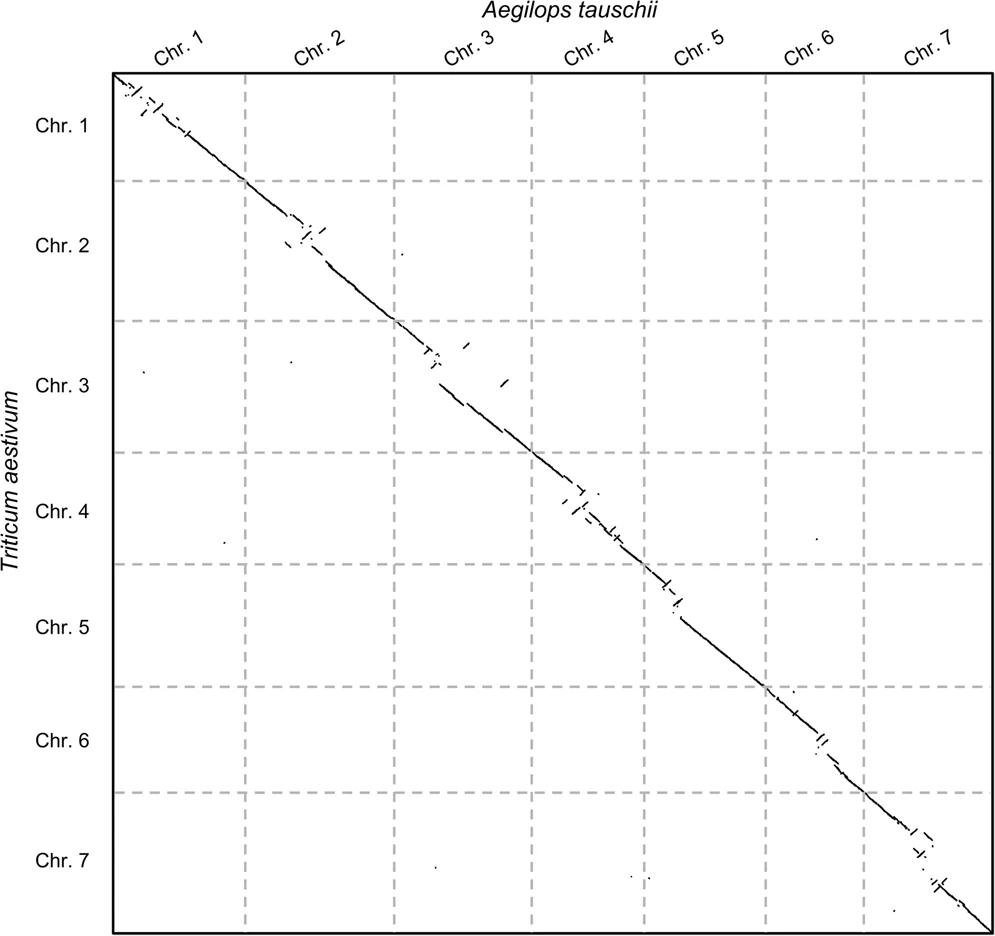 Open image in new tab
Open image in new tabNow there are some things to note here: (1) these alignment-free comparisons can be performed very quickly, (2) we can visually see the large rearrangements and (3) we can identify which chromosome comparisons actually have any signal. This last point is interesting because it allows us to use CHROMEISTER to quickly identify which comparisons are worth to perform with more accurate tools and avoid lots of unnecessary computation (in this case only the diagonal has similarity, but it might not be the case, e.g. Homo sapiens and Mus musculus).
Let us now jump into the hands-on! We will learn how to compare chromosomes with CHROMEISTER, particularly from the grass and common wheat genomes, which are nearly 5 times larger than the average human chromosome!
Preparing the data
Hands On: Chromosome data upload
Create a new history for this tutorial and give it a descriptive name (e.g. “Chromosome comparison hands-on”)
To create a new history simply click the new-history icon at the top of the history panel:
- Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
- Type the new name
- Click on Save
- To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
Import
aegilops_tauschii_chr1.fastaandtriticum_aestivum_chr1.fastafrom Zenodo.https://zenodo.org/record/4485547/files/aegilops_tauschii_chr1.fasta https://zenodo.org/record/4485547/files/triticum_aestivum_chr1.fasta
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
As default, Galaxy takes the link as name, so rename them.
Rename the files to
aegilops.fastaandtriticum.fastaand change the datatype tofastaif needed.
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select your desired datatype from “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button
Comment: Note on the name of the chromosomesPlease notice that these chromosomes are not labelled as “chromosome 1” at their original sources. We have renamed them for simplicity.
Question
- We already discussed the mycoplasma sequences in regards to their size. What do you think about the size of the two chromosomes that we will be comparing now from a computational standpoint?
- Chromosome-like sequences are arguably some of the largest DNA sequences you can find. Regarding the comparison, optimal chromosome comparison typically requires either large clusters to be run or special hardware accelerators (such as GPUs). On the other hand, for seed-based local alignment we can still use common approaches, but they will take a considerable amount of time. Finally, if we use alignment-free methods such as
CHROMEISTER, we can perform a comparison in few minutes (check the slides for more information) instead of hours.
Running the comparison
Hands On: Comparing two plant chromosomes with CHROMEISTER
- CHROMEISTER ( Galaxy version 1.5.a) with the following parameters
- param-file “Query sequence”:
aegilops.fasta- param-file “Reference sequence”:
triticum.fasta- “Output dotplot size”:
1000- “K-mer seed size”:
32- “Diffuse value”:
4- “Add grid to plot for multi-fasta data sets”:
No- “Generate image of detected events”:
Yes- Run the job and wait for the results. It should take around ~3 minutes.
- Let’s inspect the output files:
- “Comparison matrix”: This file is the “core” of the comparison. It contains the heuristically matched seeds sampled per section of the chromosomes. This file is used for custom post-processing.
- “Comparison dotplot”: This file is a
.pngimage representing the pairwise comparison.- “Comparison metainformation”: This CSV file contains information about the comparison such as name of the sequences compared, length, etc. It is particularly useful when using multi-fasta inputs.
- “Detected events”: This CSV file contains information regarding rearrangements automatically detected.
- “Detected events plot”” This file is a
.pngimage showing the detected events.- “Comparison score”: This text file contains the scoring distance between the query and the reference.
Comment: About parametersSome of the parameters used in
CHROMEISTERare similar to those inGECKO, but others are new, in particular:
- “Output dotplot size”: This number represents the width and height of the resulting comparison plot, but it also affects the degree of precision with which alignment-free blocks are calculated. A value of
1000is adequate for mostly everything (resulting in a1000x1000output doplot), but for extremely large sequences a value of2000will yield more resolution since less blocks will be grouped together.- “K-mer seed size”: This value is the same as in
GECKO. Generally,32is a good choice for any sequence that is not very small such as the mycoplasmas from the previous part of the tutorial, which were around 1 Mbp in size.- “Diffuse value”: This parameter regulates the stringency with which alignment-free seeds are matched. A diffuse value of
1means perfect matching, whereas a value of4means match only a fourth of the seed (taken in uniform steps). The value of4is recommended for everything except when signals start to deteriorate in large comparisons with plenty of repeats.- The “Add grid to plot for multi-fasta data sets” parameter adds grid lines to the plot to separate multiple sequences. This is useful when using multi-fasta inputs.
- The “Generate image of detected events” parameter will include, if enabled, a plot of the rearrangements detected with colors, one per type of rearrangement. More on that later!
Your Comparison dotplot file (remember to inspect each using the galaxy-eye icon) should look like this:
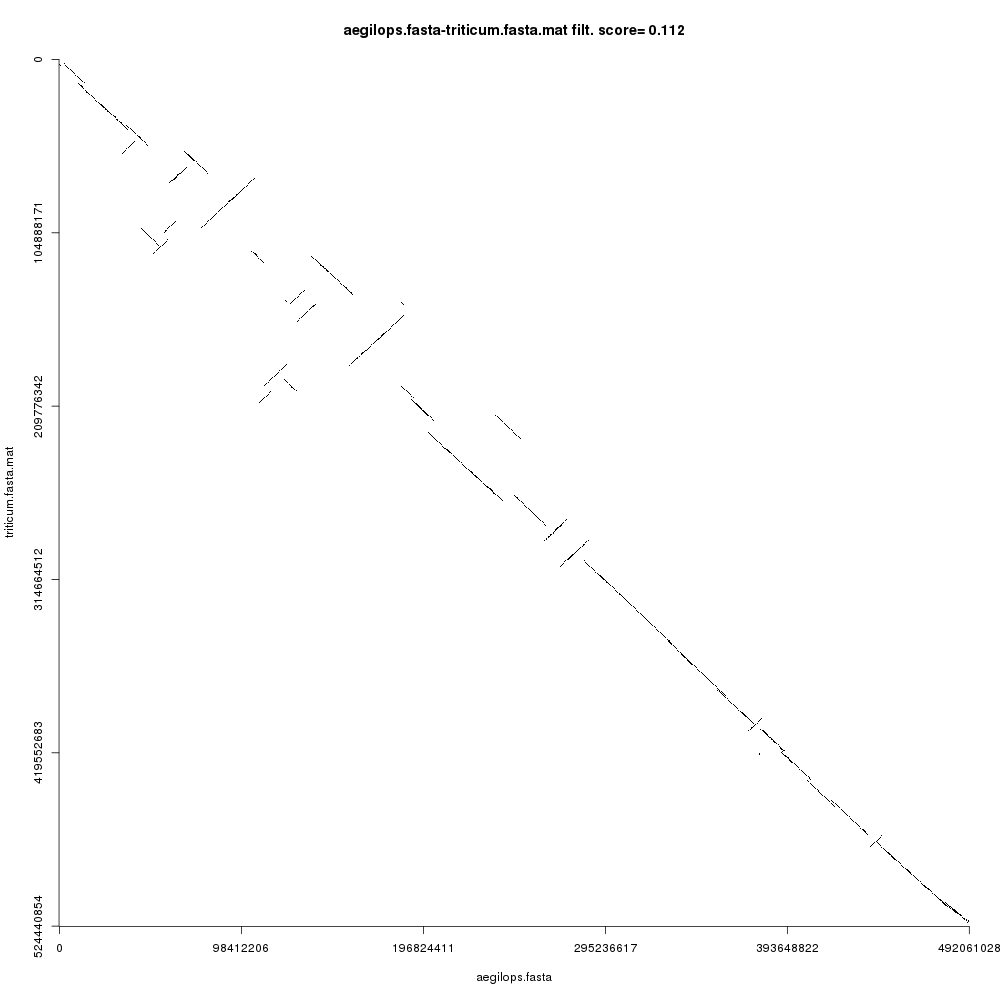 Open image in new tab
Open image in new tabFigure 3 shows the comparison plot for the plant chromosomes. Notice that the origin of both sequences is at the top-left and the ending is at the bottom-right of the plot. Noise and small repeats are filtered out automatically by CHROMEISTER to allow focusing on where the main similarity blocks are located. We can see that there three types of blocks:
- Blocks that are “conserved” are on the main diagonal. This means that the sequences are similar (in a coarse-grained fashion) in such regions.
- Blocks that are inverted are on the antidiagonals, i.e. rotated 90 degrees. These blocks show sequence regions that have been reversed and rearranged into the complementary strand.
- Blocks that are not in the main diagonal are “transposed”, meaning that they have been rearranged in one of the sequences but not in the other. These can also be inverted.
Comment: Note on the comparison plotNotice that the comparison plot is only an approximation. It is aimed at showing the general location and direction of syntenies. For example, if
CHROMEISTERwas run with parameter Output dotplot size equal to1000, then each pixel in the plot contains the averaged information of nearly 500,000 base pairs! Thus, any block can contain lots of smaller rearrangements, mutations, inversions, etc., that are ignored for the sake of providing a clean overview of the general alignment direction in a pairwise comparison.
Also note that a score value can be seen in the title of the plot (this value is also available in the Comparison score file). This value is calculated based on the alignment coverage and number of rearrangements and can be used to automatically filter out similar from dissimilar sequence comparisons. A value of 0 means that the sequences are nearly equal (rearrangement-wise), whereas a value closer to 1 means that the sequences are more dissimilar.
Post-processing: detecting rearrangements
Let us now see how the blocks detected in the comparison are automatically classified for further processing. Figure 4 shows the blocks detected heuristically from the comparison and classified according to their position and orientation. This plot is available in the file Detected events plot.
 Open image in new tab
Open image in new tabIn Figure 4 we can see a similar plot to that in Figure 3 but with the addition of colors. Each detected block is labelled according to whether it is in the main diagonal (red), transposed (blue) or inverted (green). Inverted transpositions are also labelled green. Notice that this automatic classification process is based on the Hough transform (Duda and Hart 1972) which is governed by a set of parameters which can therefore affect the sensitivity of the detection of blocks, and hence some blocks can be missed.
Each of these blocks is also available in the CSV file Detected events. Let us take a peek:
xStart,yStart,xEnd,yEnd,strand,approximate length,description
189935556,218167395,202237082,205056373,f,12301526,conserved block
...
156475406,165723309,175173725,185127621,r,18698319,inversion
...
208633875,239669470,213062425,234949502,f,4428550,transposition
...
86602740,73946160,103332815,91252708,r,16730075,inverted transposition
The header line describes each column. xStart and xEnd are the starting and ending coordinates in the query sequence, wheras yStart and yEnd are the same but for the reference sequence. The strand can be either f for the forward strand or r for the reverse strand. Notice that the length of the block is approximate, since it is an estimation based on the length of the line and transformed by the length of each sequence. The description column contains the label of the detected event. The four possible types (conserved block, inversion, transposition or inverted transposition) are shown above with examples.
Besides providing a visual understanding of the large rearrangements that took place between two sequences, the detection of blocks can be further used to research evolutionary distances, for instance by incorporating the number of Large Scale Genome Rearrangements to generate richer metrics in phylogenetic studies.
Conclusion
From a pratical perspective, we have shown how to run pairwise genome comparisons using Galaxy, from small to large-scale sequences (in particular bacterial mycoplasmas and plant chromosomes) throughout two levels of precision:
- Using
GECKOto detect High-scoring Segment Pairs, which can be used to find fine-grained alignments such as repeats, genes, synteny blocks, etc. - Using
CHROMEISTERto find large-scale conserved blocks, which enables us to look at the “big picture” of a comparison as well as study its large-scale rearrangements.
Moreover, we have described how we can use additional tools to post-process our comparisons, including extraction of alignments, multiple sequence alignment, automatic detection of rearrangements, dotplot visualization, etc. Additionally, we recommend taking a look at GECKO-MGV (Diaz-del-Pino et al. 2019), a tool for the interactive exploration of sequence comparisons produced with GECKO.
On the other hand, from a theoretical standpoint, we have discussed why sequence comparison is a difficult problem, how the length of the sequences can affect runtimes, the complexity of the algorithms, impact of parameters, etc., in order to give researchers a broader understanding of how to use sequence comparison algorithms for their scientific experiments (more details in the slides).
You've Finished the Tutorial
Key points
We learnt that sequence comparison is a demanding problem and that there are several ways to approach it
We learnt how to run sequence comparisons in Galaxy with different levels of precision, particularly fine-grained and coarse-grained sequence comparison using GECKO and CHROMEISTER for smaller and larger sequences, respectively
We learnt how to post-process our comparison by extracting alignments, fine-tuning with multiple sequence alignment, detecting rearrangements, etc.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Duda, R. O., and P. E. Hart, 1972 Use of the Hough transformation to detect lines and curves in pictures. Communications of the ACM 15: 11–15.
- Myers, E. W., and W. Miller, 1988 Optimal alignments in linear space. Bioinformatics 4: 11–17.
- Altschul, S. F., W. Gish, W. Miller, E. W. Myers, and D. J. Lipman, 1990 Basic local alignment search tool. Journal of molecular biology 215: 403–410.
- Torreno, O., and O. Trelles, 2015 Breaking the computational barriers of pairwise genome comparison. BMC bioinformatics 16: 250.
- Diaz-del-Pino, S., P. Rodriguez-Brazzarola, E. Perez-Wohlfeil, and O. Trelles, 2019 Combining Strengths for Multi-genome Visual Analytics Comparison. Bioinformatics and biology insights 13: 1177932218825127.
- Pérez-Wohlfeil, E., S. Diaz-del-Pino, and O. Trelles, 2019 Ultra-fast genome comparison for large-scale genomic experiments. Scientific reports 9: 1–10.
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Esteban Perez-Wohlfeil, From small to large-scale genome comparison (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/genome-annotation/tutorials/hpc-for-lsgc/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{genome-annotation-hpc-for-lsgc, author = "Esteban Perez-Wohlfeil", title = "From small to large-scale genome comparison (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/genome-annotation/tutorials/hpc-for-lsgc/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/genome-annotation/tutorials/hpc-for-lsgc/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: clustalw owner: devteam revisions: d6694932c5e0 tool_panel_section_label: Multiple Alignments tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: chromeister owner: iuc revisions: e483be1014b6 tool_panel_section_label: Multiple Alignments tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: gecko owner: iuc revisions: 5efbd15675ca tool_panel_section_label: Multiple Alignments tool_shed_url: https://toolshed.g2.bx.psu.edu/