In this tutorial we will use OpenRefine tool to clean occurrence records retrieved from GBIF (Global Biodiversity Information Facility).
This tutorial is based on the GBIF Laure Russell 2021 “Biodiversity data mobilization course” accessible on GBIF website on Use case 1 “Herbarium Specimens” using file from Exercise 3C, at the bottom of the page, reachable through this direct URL.
Retrieve data from GBIF “Biodiversity data mobilization course”
Hands On: Data import and project creation
Create a new history for this tutorial and give it a name (example: “OpenRefine tutorial”) for you to find it again later if needed.
To create a new history simply click the new-history icon at the top of the history panel:
Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
Type the new name
Click on Save
To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
Figure 1: Output of Regex Find And Replace example
Rename the datasets if needed, for example with “UC1-3c-open-refine-tabular” to keep orginal name and specify the tabular format.
Click on the galaxy-pencilpencil icon for the dataset to edit its attributes
In the central panel, change the Name field
Click the Save button
Deploy an OpenRefine instance and push your data in
Hands On: Deploy an OpenRefine instance and import data from your Galaxy history
OpenRefine tool with the following parameters:
“Input file in tabular format”: UC1-3c-open-refine-tabular
click the button “run tool”
You will then be redirected. A notification “Interactive Tools” shows up on the left-hand side, indicating you have an interactive tool running.
Click on the notification, click on the empty box in front of the text saying “Openrefine”.
Then, click on the text “Openrefine” to open the tool in a new tab. It might take a moment until your cursor changes and the text becomes a hyperlink.
Open the OpenRefine instance
go to “Open Project” space
select the project named “Galaxy file”
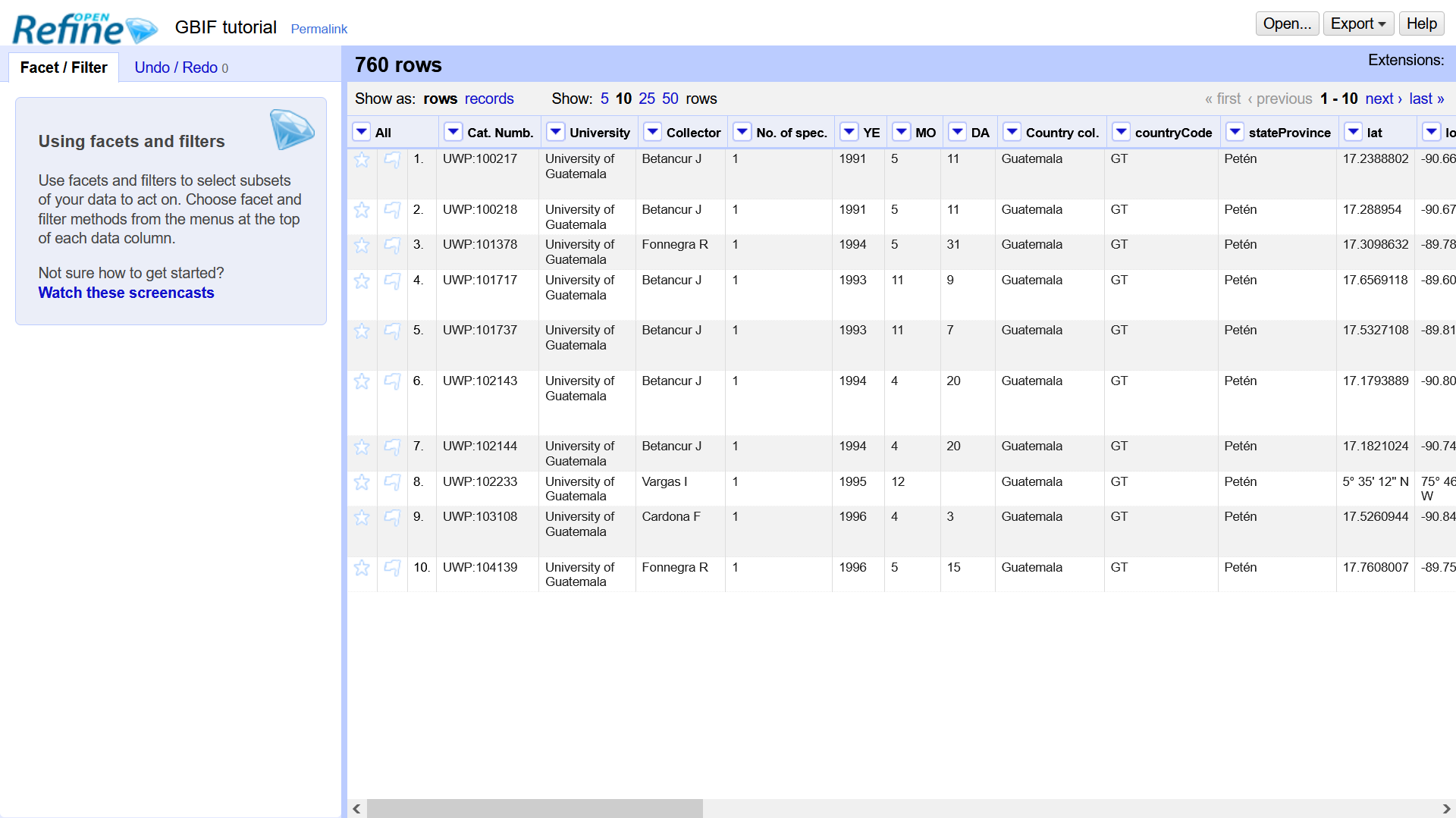
You will now have your project with first 10 lines of your file displayed
Faceting
Faceting is a feature that will allow us to get a big picture overview of the data, and to filter down to just the subset of rows
that we want to change or view in bulk. It facilitates the use and analysis of data and can be done with cells containing any
kind of text, numbers and dates.
Hands On: Faceting and mass editing
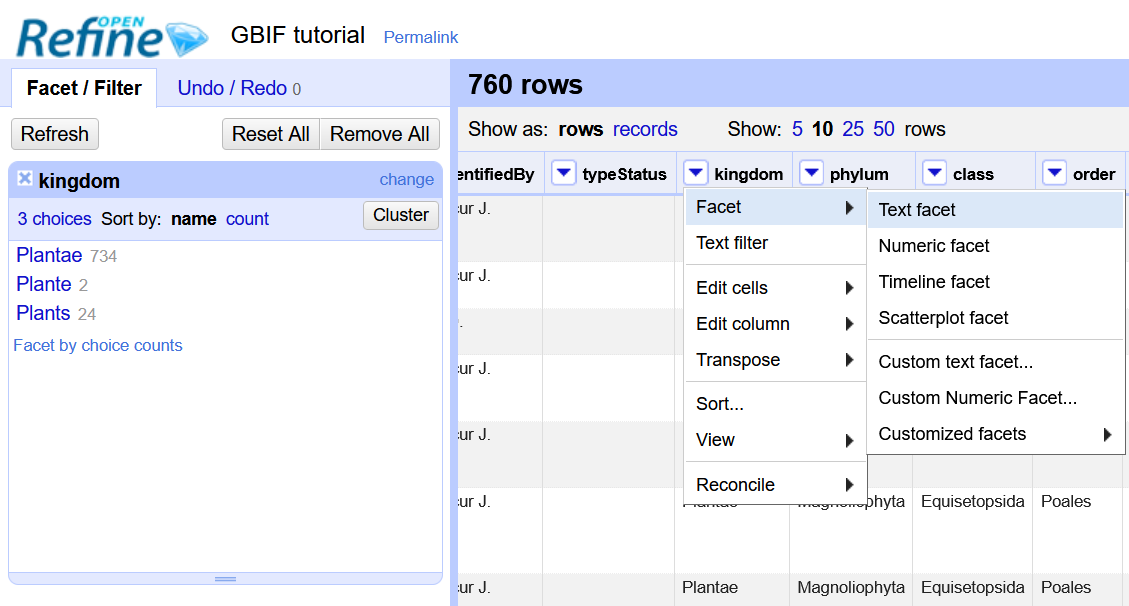
Go to column “kingdom”, and then click on the column menu and follow the route to Text facet.
On the left a window with the name of the column will appear, that is the facet.
Click on count to sort by count, then click on name to sort alphabetically
Fix the spelling mistakes (Plante -> Plantae). Place the cursor over the text in the window and click on edit, then fix the error in the text box, and to save click on apply.
All the values will be fixed automatically.
Question
How many Plantae occurences you now have?
736
Hands On: Faceting and white space 1
Go to “Country col.” column and click on column menu and perform a Text Facet
On a quick view, the country appears to be spelled correctly, but the facet shows three different values due to the extra spaces at the end of the text.
Fix the error from the column menu on “Country col.” column, following the route by clicking the dropdown menu, Edit Cells > Common transforms > Trim leading and trailing whitespace.
You will see a notification message “Text transform on 38 cells in column Country col.: value.trim()” and the possibility to come back on previous state clicking on the undo hyperlink.
Now check the facet window; only one value will remain.
Hands On: hands_on Faceting and white space 2
Go to column “Full name” and click on the dropdown menu, then go to Text facet. Then click on count.
Guzmania lingulata is the first item in the list with 25 specimens, but it is also present in the 3rd position with 20 specimens.
Fix the error from the “Full name” column menu, Edit Cells > Common transforms > Collapse consecutive whitespaces.
Question
How many Guzmania lingulata records only appear in the list finally?
45
Hands On: hands_on Faceting and duplicates
Go to column catalog in “Cat. Numb”, and follow the route Facet > Customized facets > Duplicates facet.
The facet will show 4 duplicates
Click on true, and you’ll see the values in the main window
After a check with the specimens labels, fix the values clicking edit directly on the cell with the correct catalogue numbers
UWP:122470 for Vargas P
UWP:122471 for Vargas I
UWP:157351 for Betancur H
UWP:157339 for Betancur J
click apply after you finish each edit
Filtering
Hands On: hands_on Basic filter
Go again to “Full name” column menu and perform a Text facet to visualize the values
Then go again to the column menu and click on Text filter
Perform the following filters and fix them as described below:
search for “sp1” entries -> Then remove it and obtain “Cyperus”, clicking on Edit directly in the cell
search for “SP2” entries, check case sensitive -> To remove it and obtain “Cyperus”, you can Edit directly in the cell
search for “spp”.
Go to “Full name” column menu, then click Edit cells > Transform
In the text box paste the formula value.replace(" spp.", "") and click ok
Question
Do you think you can use also Edit cells > Transform formula to apply the changes you made manually for the two first terms searched (“sp1” and “SP2”)?
Why can you easily edit these two first entries directly but not the third one?
Yes, using respectively value.replace(" sp1", "") and value.replace(" SP2", "") formulas
Because the first two searches only concern one entry for each when the third one returns several.
Hands On: hands_on Advance filter 1
Go to column “genus” and perform a Text filter.
Check regular expression and case sensitive , then paste the expression “^[a-z]”
This regular expression filters the strings in which the first letter is lowercase.
Perform a correction since the genus should be capitalized.
Regular expressions are a standardized way of describing patterns in textual data. They can be extremely useful for tasks such as finding and replacing data. They can be a bit tricky to master, but learning even just a few of the basics can help you get the most out of Galaxy.
Finding
Below are just a few examples of basic expressions:
Regular expression
Matches
abc
an occurrence of abc within your data
(abc|def)
abcordef
[abc]
a single character which is either a, b, or c
[^abc]
a character that is NOT a, b, nor c
[a-z]
any lowercase letter
[a-zA-Z]
any letter (upper or lower case)
[0-9]
numbers 0-9
\d
any digit (same as [0-9])
\D
any non-digit character
\w
any alphanumeric character
\W
any non-alphanumeric character
\s
any whitespace
\S
any non-whitespace character
.
any character
\.
literal . (period)
{x,y}
between x and y repetitions
^
the beginning of the line
$
the end of the line
Note: you see that characters such as *, ?, ., + etc have a special meaning in a regular expression. If you want to match on those characters, you can escape them with a backslash. So \? matches the question mark character exactly.
Examples
Regular expression
matches
\d{4}
4 digits (e.g. a year)
chr\d{1,2}
chr followed by 1 or 2 digits
.*abc$
anything with abc at the end of the line
^$
empty line
^>.*
Line starting with > (e.g. Fasta header)
^[^>].*
Line not starting with > (e.g. Fasta sequence)
Replacing
Sometimes you need to capture the exact value you matched on, in order to use it in your replacement, we do this using capture groups (...), which we can refer to using \1, \2 etc for the first and second captured values. If you want to refer to the whole match, use &.
Regular expression
Input
Captures
chr(\d{1,2})
chr14
\1 = 14
(\d{2}) July (\d{4})
24 July 1984
\1 = 24, \2 = 1984
An expression like s/find/replacement/g indicates a replacement expression, this will search (s) for any occurrence of find, and replace it with replacement. It will do this globally (g) which means it doesn’t stop after the first match.
Example: s/chr(\d{1,2})/CHR\1/g will replace chr14 with CHR14 etc.
You can also use replacement modifier such as convert to lower case \L or upper case \U. Example: s/.*/\U&/g will convert the whole text to upper case.
Note: In Galaxy, you are often asked to provide the find and replacement expressions separately, so you don’t have to use the s/../../g structure.
There is a lot more you can do with regular expressions, and there are a few different flavours in different tools/programming languages, but these are the most important basics that will already allow you to do many of the tasks you might need in your analysis.
Tip:RegexOne is a nice interactive tutorial to learn the basics of regular expressions.
Tip:Regex101.com is a great resource for interactively testing and constructing your regular expressions, it even provides an explanation of a regular expression if you provide one.
Tip:Cyrilex is a visual regular expression tester.
Question
Try to find a regular expression to apply the same kind of Text filter operation as in the previous exercise. Which regular expression can work?
On my side, I found this formla value.replace(value.substring(0,1),toUppercase(value.substring(0,1)))
Hands On: hands_on Advance filter 2
Go to column “Full name” and perform a Text filter.
Check regular expression and case sensitive, then paste the expression ^[A-Z].*\s[A-Z]
This regular expression filters the strings that start with a capital letter followed by 0 or more characters, then a space, then a capital letter.
Perform a correction since the second word of the name should be lowercase.
Clustering
Hands On: Basic clustering
Go to “County” and perform a Text facet.
Keep in mind that the correct counties are: “Flores”, “La Libertad”, “Melchor de Mencos”, “San Andres” and “San Jose”.
On the top right of the facet window click on Cluster, a new window will appear.
Click on the Cluster button from this new window.
Now you can see information about the clusters:
“Cluster size”: the number of different versions that the clustering algorithm believes to be the same.
“Row count”: the number of records with any of the cluster values.
“Values in cluster”: the actual values that the algorithm believes to be the same. There is also the number of records with each particular value, and the possibility to browse the contents of the cluster in a different tab.
“Merge?”: check if values are to be merged into a single standard value.
“New cell value”: the value to be applied to every record in the cluster. By default, it is the value with most records. You can also click on any value to apply that to the New cell value.
Comment
If you want to know more about clustering have a look at the manual
Click on Select All and then on Merge Selected & close
You will see a notification message “Mass edit 119 cells in column County”.
To fix the remaining counties go again to Cluster in the facet window of Count.
In the Cluster and edit window, go to Keying Function, then select ngram-fingerprint
set “1” as the value in n-Gram Size.
Press the Cluster button, you normally see a cluster about “San Andres” of size “4”.
Click on Select All and then on Merge Selected & close, you will see a notification message “Mass edit 360 cells in column County”.
Your counties are now fixed! Congratulation!
Exporting
Hands On: hands_on Exporting cleaned file into your Galaxy history
On the upper right corner click on Export and select Galaxy exporter.
A notification message as “Dataset has been exported to Galaxy, please close this tab” is displayed.
You normally have your resulting data file exported on your Galaxy history as “openrefine-Galaxt file.tsv” dataset.
When you want to close OpenRefine, go back to the Galaxy window. Go to the middle window, “Active Interactive Tools”. Below Openrefine click stop.
The interactive tool is then stopped and the respective task shows red in your history. This does not affect your data, which is safely stored in the “openrefine-Galaxt file.tsv” dataset.
You can continue working with it in Galaxy for the following tasks.
Comment
You can also download the file directly on your computer, choosing Export and Custom tabular exporter, allowing you to select notable columns and rows you want to download.
API use
Reconciliation matches the information in one of your columns to an outside database. This is particularly helpful when it
comes to name validation, as it proves the name you have exists somewhere else. This is a really useful service but can be
time-consuming. In this case, we will go through the process with only three records using the API from GBIF.
To open your dataset again from Galaxy in OpenRefine, follow the earlier steps from this tutorial “Deploy an OpenRefine instance and push your data in”.
Hands On: hands_on Higher taxonomy
In your opened dataset in OpenRefine, go to the “Collector” column, then make a Text facet. Select the collector “Elsa P”.
Under “Full name”, click on column menu and then Edit column > Add column by fetching URLs…
call the new column “Api_name”
Change the Throttle Delay to 250 and paste the expression "http://api.gbif.org/v1/species/match?verbose=true&name="+escape(value,'url')
Click ok and wait, this might take some time depending on internet connection and the number of taxa.
Go to “Api_name”, click on column menu and then Edit column > Add column based on this column....
Call the new column “higherClassification” and paste the expression:
click ok.
You will see the Kingdom, Phylum, Class, Order and family of each taxon.
Under “higherClassification” follow the route Edit column > Split into several columns…, leave the initial settings and click ok.
Now you know how to obtain the taxonomic categories of a given taxon if this is available in the GBIF API. Column names can be edited in Edit column > Rename this column.
For the purpose of the original GBIF workshop, the columns created in this exercise (Higher taxonomy) must be deleted.
Under All, which is the first column, go to Edit columns > Re-order / remove columns….
No need to export this file as it normally comes back to the previous version you already exported.
Conclusion
Here you learned how to use OpenRefine tool from Galaxy platform to clean Biodiversity data. This tutorial notably allowed you to apply some basic but powerful functionalities of OpenRefine to clean your data.
You've Finished the Tutorial
Please also consider filling out the Feedback Form as well!
Key points
OpenRefine is a powerful tool, with many functionalities to check, clean and enrich your data
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channels
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{ecology-openrefine_gbif,
author = "Yvan Le Bras and Sophie Pamerlon and Laura Russell",
title = "Cleaning GBIF data using OpenRefine (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/ecology/tutorials/openrefine_gbif/tutorial.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Funding
These individuals or organisations provided funding support for the development of this resource
Questions:
Open image in new tab