Refining Genome Annotations with Apollo (prokaryotes)
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to visualize your genome after automated annotations have been performed?
How to manually annotate genome after automated annotations have been performed?
How to evaluate and visualize annotated genomic features?
How do I collaborate when doing genome annotation?
Requirements:
Load a genome into Galaxy
View annotations in JBrowse
Learn how to load JBrowse data into Apollo
Learn how to manually refine genome annotations within Apollo
Export refined genome annotations
- Introduction to Galaxy Analyses
- tutorial Hands-on: Rule Based Uploader
- slides Slides: Genome annotation with Prokka
- tutorial Hands-on: Genome annotation with Prokka
Time estimation: 3 hoursLevel: Intermediate IntermediateSupporting Materials:Published: Jun 4, 2021Last modification: May 15, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00169rating Rating: 4.6 (0 recent ratings, 5 all time)version Revision: 22
After automatically annotating your genome using Prokka for example, it is important to visualize your results so you can understand what your organism looks like, and then to manually refine these annotations along with any additional data you might have. This process is most often done as part of a group, smaller organisms may be annotated individually though.
Warning: Only works on UseGalaxy.euCurrently this tutorial requires an Apollo server to be deployed by the administrator. This will currently only work on UseGalaxy.eu, hopefully this list will expand in the future.
Apollo Dunn et al. 2019 provides a platform to do this. It is a web-based, collaborative genome annotation editor. Think of it as “Google Docs” for genome annotation, multiple users can work together simultaneously to curate evidences and annotate a genome.
This demo is inspired by the Apollo User’s Guide, which provides additional guidance.
AgendaIn this tutorial, we will cover:
Data upload
To annotate a genome using Apollo, we need the reference genome sequence in FASTA format, and any evidence tracks we want to refine into our annotations. “Evidence tracks” can be any data like:
- A set of prior gene predictions or other genomic feature predictions
- The output of a bioinformatics analysis like BLAST or InterProScan
- Sequencing reads from RNA-Seq or another HTS analysis
- If you are not doing a de novo annotation, then a previous released Official Gene Set (OGS)
In this tutorial we have obtained some data from NCBI related to Escherichia coli K12 str. MG1655, and we will visualise this data and use it to make some annotations in order to familiarise you with the process.
Comment: Real Data: Unreal CircumstancesWhile the data for this tutorial is sourced from publicly available databases, and is all related to different experiments on E. coli K12, this is not necessarily the data you might use to annotate your genomes. You probably know best what data you should be using in your own circumstances, for the specific features on which you are focused.
Get data
Hands On: Data upload
Create a new history and give it a good name
To create a new history simply click the new-history icon at the top of the history panel:
- Click on galaxy-pencil (Edit) next to the history name (which by default is “Unnamed history”)
- Type the new name
- Click on Save
- To cancel renaming, click the galaxy-undo “Cancel” button
If you do not have the galaxy-pencil (Edit) next to the history name (which can be the case if you are using an older version of Galaxy) do the following:
- Click on Unnamed history (or the current name of the history) (Click to rename history) at the top of your history panel
- Type the new name
- Press Enter
Click the upload icon galaxy-upload
Switch to the “Rule-based” tab
Copy & Paste the following table into the Rule-based uploader textbox:
https://zenodo.org/records/4889110/files/augustus.gff3 Augustus gff3 https://zenodo.org/records/4889110/files/blastp_vs_swissprot_2018-01-22.blastxml Blastp vs swissprot blastxml https://zenodo.org/records/4889110/files/BWA-MEM_K12_Coverage.bigwig BWA-MEM K12 Coverage bigwig https://zenodo.org/records/4889110/files/BWA-MEM_K12_Mapping.bam BWA-MEM K12 Mapping bam https://zenodo.org/records/4889110/files/BWA-MEM_O104_Coverage.bigwig BWA-MEM O104 Coverage bigwig https://zenodo.org/records/4889110/files/BWA-MEM_O104_Mapping.bam BWA-MEM O104 Mapping bam https://zenodo.org/records/4889110/files/E._coli_str_K-12_substr_MG1655_100kb_subset.fasta Genome fasta https://zenodo.org/records/4889110/files/K12_Variants.vcf K12 Variants vcf https://zenodo.org/records/4889110/files/NCBI_AnnotWriter_Genes.gff3 NCBI AnnotWriter Genes gff3 https://zenodo.org/records/4889110/files/O104_H4_LASTZ_Alignment.bed O104 H4 LASTZ Alignment bed https://zenodo.org/records/4889110/files/O104_Variants.vcf O104 Variants vcf https://zenodo.org/records/4889110/files/TopHat_SRR1927169_rep1.bam TopHat SRR1927169 rep1 bam https://zenodo.org/records/4889110/files/TopHat_SRR1927169_rep1_Coverage.bigwig TopHat SRR1927169 rep1 Coverage bigwig https://zenodo.org/records/4889110/files/TopHat_SRR1927170_rep2.bam TopHat SRR1927170 rep2 bam https://zenodo.org/records/4889110/files/TopHat_SRR1927170_rep2_Coverage.bigwig TopHat SRR1927170 rep2 Coverage bigwigClick Build
From Rules menu select
Add / Modify Column Definitions
- Click
Add Definitionbutton and selectURL
- “URL”:
A- Repeat this again and select
Nameinstead.
- “Name”:
B- Repeat this again and select
Typeinstead.
- “Type”:
C- Click
ApplyClick Upload

Using Apollo for Annotation
Refining genome annotations happens in multiple steps:
- Create a JBrowse instance from the reference genome FASTA file and evidence tracks
- Import this data into Apollo
- Refine the annotations
- Export the refined genome annotations
In this tutorial we will focus more on the practical portions than the theoretical part of genome annotation, that are covered in other tutorials. When you’ve completed this tutorial you should be comfortable manipulating genomic data in Galaxy and Apollo.
Automated annotation programs continue to improve, however a simple score may not provide evidence necessary to confirm an accurate prediction. Therefore, it is necessary to both visually inspect the results and manually fix any issues with the predictions.
Additionally, many times assemblies are less than perfect or read depth and quality may be insufficient, leading to imperfect automatic annotation.
Build the JBrowse Instance
Let’s begin by building a JBrowse instance with all the data we have for this genome.
Comment: Reduced dataTo reduce the size of the data, in this tutorial we will only work on a portion of the Escherichia coli K12 str. MG1655 genome.
Hands On
- JBrowse ( Galaxy version 1.16.11+galaxy1) with the following parameters:
- “Reference genome to display”:
Use a genome from history
- param-file “Select the reference genome”: Select the
Genomefasta file- “Genetic Code”:
11. The Bacterial, Archael and Plant Plastid Code- In “Track Group”:
- param-repeat “Insert Track Group”
- “Track Category”:
Gene Calls- In “Annotation Track”:
- param-repeat “Insert Annotation Track”
- “Track Type”:
GFF/GFF3/BED Features
- param-files “GFF/GFF3/BED Track Data”:
AugustusandNCBI AnnotWriter Genes- In “JBrowse Styling Options [Advanced]”
- “JBrowse style.className”:
transcript-CDS- param-repeat “Insert Track Group”
- “Track Category”:
Sequencing- In “Annotation Track”:
- param-repeat “Insert Annotation Track”
- “Track Type”:
BAM Pileups
- param-files “BAM Track Data”: Both BWA-MEM Mappings
- param-repeat “Insert Annotation Track”
- “Track Type”:
BigWig XY
- param-files “BAM Track Data”: Both of the BWA-MEM Coverage files (not the
(as bigwig)files)- “Use XYPlot”:
Yes- “Show Variance Band”:
Yes- param-repeat “Insert Track Group”
- “Track Category”:
RNA-Seq- In “Annotation Track”:
- param-repeat “Insert Annotation Track”
- “Track Type”:
BAM Pileups
- param-files “BAM Track Data”: Both TopHat Mappings
- param-repeat “Insert Annotation Track”
- “Track Type”:
BigWig XY
- param-files “BAM Track Data”: Both of the
TopHat ... Coveragefiles (not the(as bigwig)files)- “Use XYPlot”:
Yes- “Show Variance Band”:
Yes- param-repeat “Insert Track Group”
- “Track Category”:
Variation- In “Annotation Track”:
- param-repeat “Insert Annotation Track”
- “Track Type”:
VCF SNPs
- param-files “SNP Track Data”: Both Variants files
- param-repeat “Insert Track Group”
- “Track Category”:
Similarity- In “Annotation Track”:
- param-repeat “Insert Annotation Track”
- “Track Type”:
GFF/GFF3/BED Features
- param-file “GFF/GFF3/BED Track Data”:
O104:H4 LASTZ Alignments- param-repeat “Insert Annotation Track”
- “Track Type”:
Blast XML
- param-file “Blast XML Track Data”: The
blastpresults from swissprot (Blastp vs swissprot)- param-file “Features used in Blast Search”: The
NCBI AnnotWriter Genesfile- “Minimum Gap Size”:
3- “Is this a protein blast search?”:
YesComment: JBrowse is highly configurableJBrowse is highly configurable, we have set a very basic configuration but there are many more advanced features available to you, if you need them. You can choose precisely how data is displayed, and even what menu options are available when users click on features. If your features have some external identifiers like an NCBI Gene ID, you can even configure JBrowse that when the user clicks on the feature, it should show the gene page for that feature in a new tab. These sort of features are incredibly helpful for building very rich experiences.
A static genome browser like this (just JBrowse, not in Apollo) is very useful for summarising results of a genomics workflow, where the next step is simply interpretation and not annotation. Have a look at the JBrowse tutorial for more information.
Currently we have built a standalone genome browser (data + the html page and user interface and javascript), but it’s possible to just compile the data directory if you intend to send this data to Apollo, and don’t need to view the static data in Galaxy.
This tool will take some time to run dependent on data size. All of the inputs need to be pre-processed by JBrowse into a form that it can render and visualise easily. Once this is complete, you can click on the galaxy-eye eyeball to view the JBrowse instance. This is a static view into the data, JBrowse does not let you make any annotations or save any changes. We will convert it into a dynamic view where we can make persistent annotations and share these with our colleagues.
Sending data to Apollo
Now that we have a good looking static JBrowse instance, it is time to load it into Apollo to turn it into a dynamic view where you can make modifications to the genes.
Hands On: Import to Apollo
- Create or Update Organism ( Galaxy version 4.2.5) with the following parameters:
- param-file “JBrowse HTML Output”: output of JBrowse tool
- “Organism Common Name Source”:
Direct Entry
- “Organism Common Name”:
E. coli K12- “Genus”:
Escherichia- “Species”:
coli- Annotate ( Galaxy version 4.2.5) with the following parameters:
- param-file “Apollo Organism Listing”: output of Create or Update Organism tool
- View galaxy-eye the output of the Annotate tool, when it is ready.
Viewing the output will open a view into Apollo in the main panel. Here you can interact with your genome and make annotations. This “Annotate” output is a quick link to that specific genome, and while Apollo allows you to manage and annotate multiple genomes, this dataset will always take you back to that specific genome. You can additionally access the Apollo server outside of Galaxy. While the URL will be different for each Galaxy server that supports Apollo, UseGalaxy.eu’s Apollo server is available at https://usegalaxy.eu/apollo.
Apollo
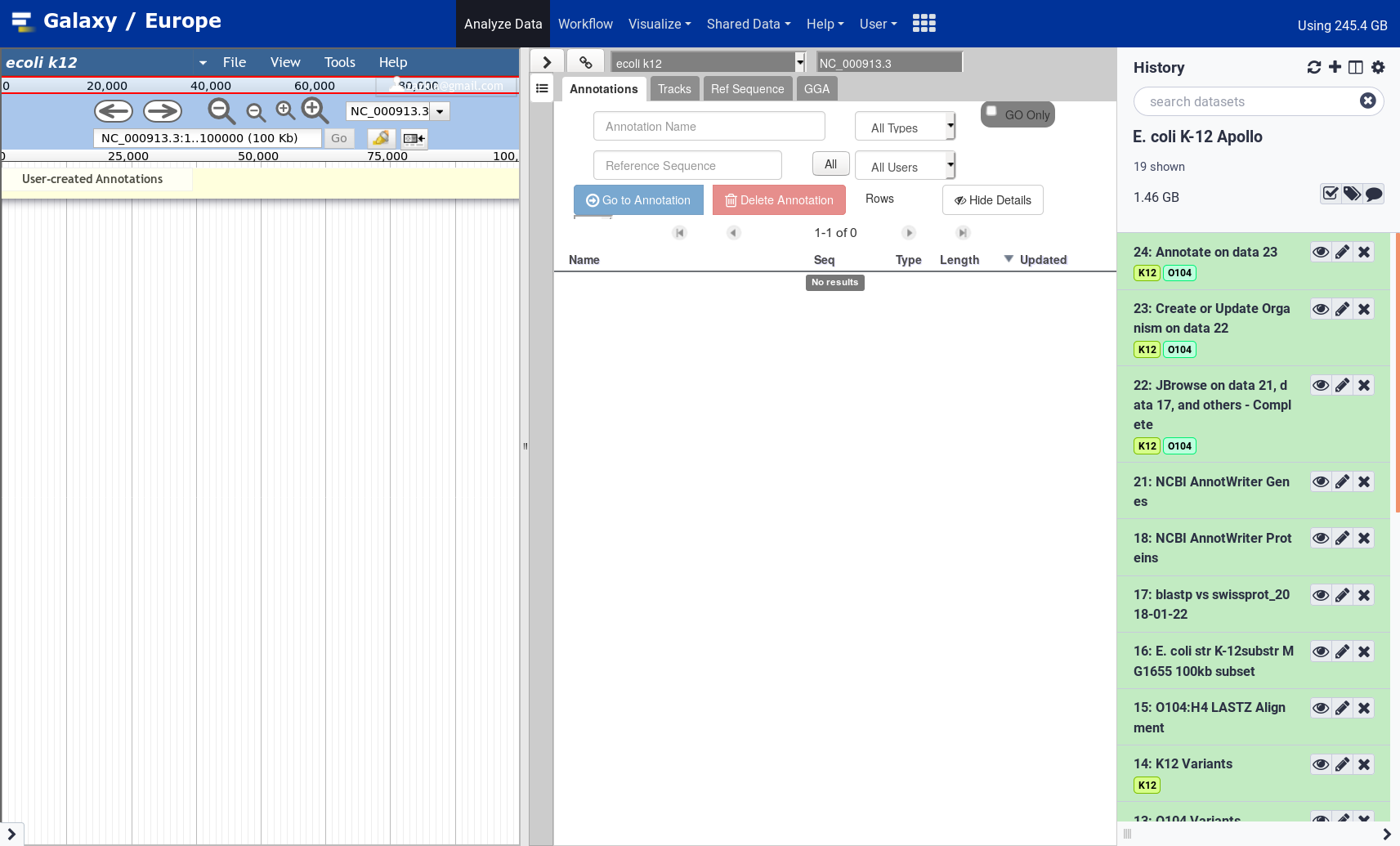 Open image in new tab
Open image in new tabFrom the Apollo user manual:
The major steps of manual annotation using Apollo can be summarized as follows:
- Locate a chromosomal region of interest.
- Determine whether a feature in an existing evidence track provides a reasonable gene model to start annotating.
- Drag the selected feature to the ‘User Annotation’ area, creating an initial gene model.
- Use editing functions to edit the gene model if necessary.
- Check your edited gene model for consistency with existing homologs by exporting the FASTA formatted sequence and searching a protein sequence database, such as UniProt or the NCBI Non Redundant (NR) database, and by conducting preliminary functional assignments using the Gene Ontology (GO) database.
The first four steps are generally the process of structural annotation (the process of identifying the correct gene model), and the last includes functional annotation (the process of assigning a putative function to a gene in your annotations).
Evidence tracks
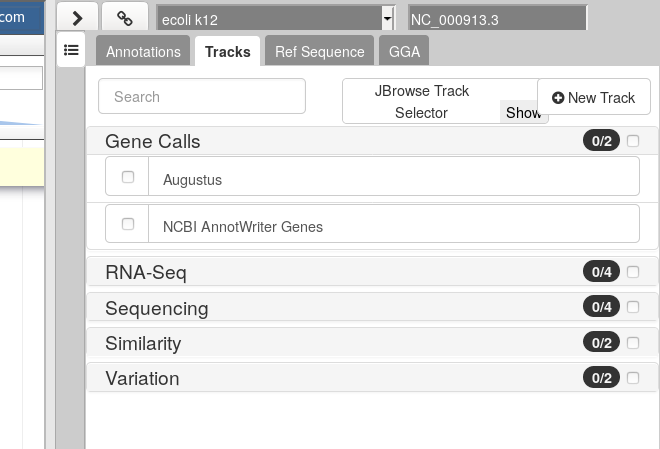
Let’s start by looking at the tracks available to us, and then turning on the gene call tracks so we can start exploring our data.
Hands On: Visualize the Gene Calls
In the right hand panel at the top click on Tracks to open the track listing
In the Gene Calls group, select the
Augustustrack.You can either activate tracks in bulk, by clicking on the checkbox to the right of the group name (“Gene Calls”), or by clicking on the group name to expand the section, and then selecting individual tracks.
Zoom to the first 10kb of the genome.
- In the left hand Annotation Window, at the top navigation bar you will find a textbox which shows the current location on the genome.
- Edit this and enter
1..10000- Press Go or use Enter on your keyboard.
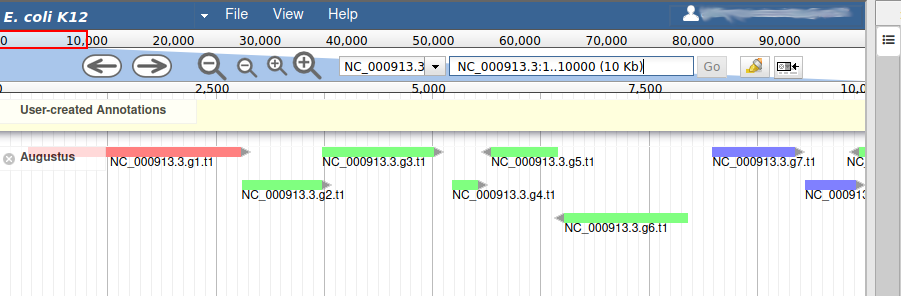
We can now see an evidence track: Augustus is the output of AUGUSTUS Stanke et al. 2008. In a de novo annotation project, we probably will only have the outputs of various gene callers, and potentially some expression evidence like RNA-Seq.
We will use the other track in the Gene Calls group later in this tutorial, leave it unchecked for now.
Adding new genes
With the selected track, if you look along the genome, you will see many genes that were predicted by Augustus. Each of them as an unique name assigned by Augustus (e.g. NC_000913.3.g7.t1, which means the 7th gene on the NC_000913.3 chromosome). If you right click on gene, an select View details, you can get access to the coding sequence (CDS).
Each gene color corresponds to an open reading frame on the genome. This allows to quickly see if two genes that are very close are on the same open reading frame, which could mean that they can be merged into a single gene, if other evidences support this.
What we want now is first to check that the structure of the genes predicted by Augustus are in good shape. To do this, we will display an additional evidence tracks.
Hands On: Display blastp vs swissport track
In the right hand panel at the top click on Tracks to open the track listing
In the Similarity group, select the
Blastp vs swissprottrack.
This new track represents the result of aligning sequences from the Swissprot databank along the genome, using Blastp. It should look like that:
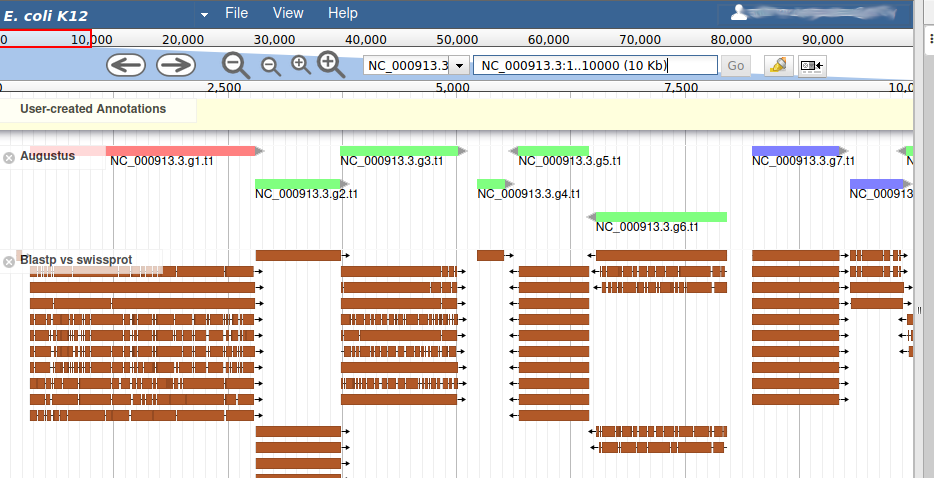
Each red box is the alignment of a protein from Swissprot on the genome. You can get more information on the aligned sequence by passing your mouse over the alignement, or clicking on it.
Most of the genes predicted by Augustus look very similar to aligned Swissprot sequences, with the coordinates. Note that our example is an ideal situation that you will probably not see on other genomes: as E. coli is a very studied and well annotated genome, which means Swissprot contains many high quality sequences that can be aligned perfectly by Blastp.
If you look at the region 55000..63000 you will notice however that 2 sequences were aligned on the genome, but Augustus didn’t predict any corresponding genes.
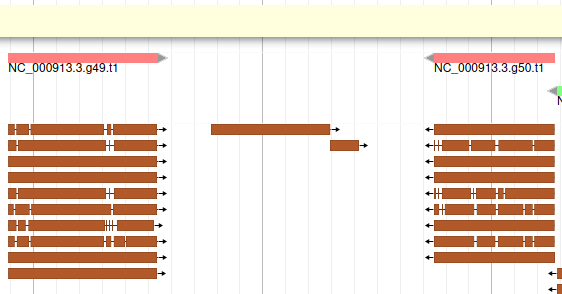
The blastp alignment looks solid, and the sequences seem to correspond to real proteins references in the litterature. We want to add them to our final annotation, to do it, right click on each gene, and select Create new annotation > gene. They should appear shortly in the User-created Annotation track (yellow background, at the top).
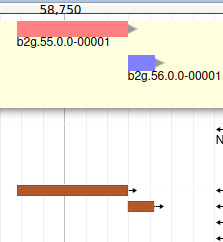
You can also see that they appear now in the list of genes in the right panel, at the gene and the mRNA level (as a gene can have multiple isoforms, in particular for eukaryotes).
The User-created Annotation track is where you can make modifications to genes, like changing their coordinates, or their name and functional annotation. If you right click on a gene in this track, you will see all the possibilities offered by apollo.
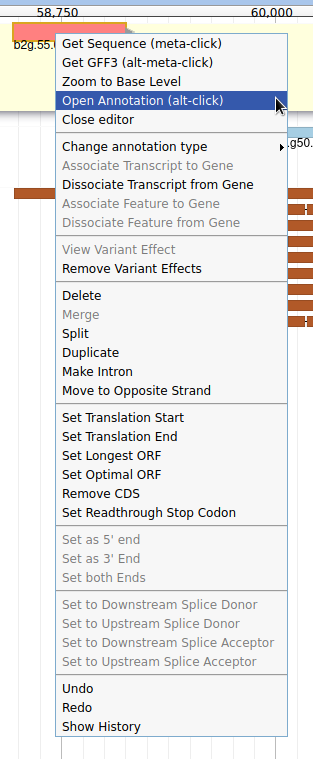
Currently, the two genes we added have meaningless names. Let’s improve that: right click on the leftmost gene, and click on Open Annotation (alt-click).
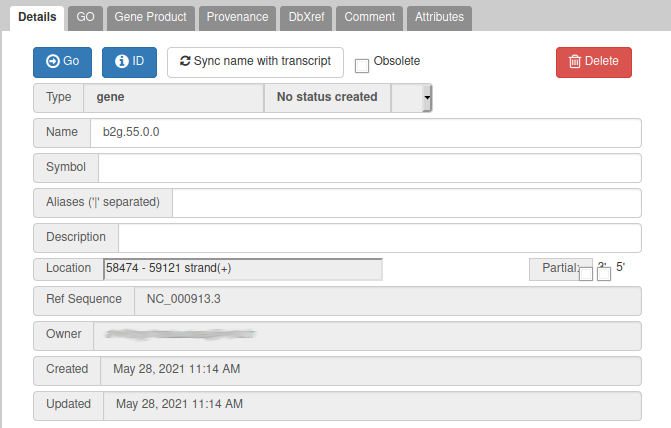
From the blast results, we know that this gene is similar to a Swissprot protein, named Putative uncharacterized protein YabP. Let’s write this in the Name field (type it manually and select it from the drop down list), and YabP in the Symbol field.
Giving a proper name to a gene is not always easy. Should it include “Putative” or not? What if multiple names can apply? Should it be lowercase or uppercase? The important thing is to always use the same naming rules when working on a full annotation, and to agree on these rules with other collaborators. Usually, big annotation consortiums have naming guidelines that you are supposed to follow.
We have just edited the gene name, but Apollo allows to edit information at the mRNA level. Click on the Sync name with transcript button to copy the gene name to the mRNA name. It should now display in the User-created Annotation track. To check what you can edit at the mRNA level, just click on the corresponding mRNA in the list above:
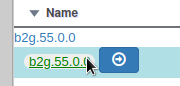
You should see Putative uncharacterized protein YabP in the Name field.
You can do the same for the other gene you created, which is similar to Uncharacterized protein YabQ according to Blastp vs Swissprot.
Comment: Saving your workYou do not need to do anything specific to Save your work in Apollo. Just like Google Docs, each modification is immediately saved, and any other user working on the same genome will instantly see the changes you make.
Editing a gene structure
Apollo allows to edit the whole structure of a gene. If you zoom to the 5’ end of YabP, you will notice, that a few nucleotides after the start codon, there is another one. Let’s change the start of YabP to this alternate start codon (even if the blast result suggests that we shouldn’t do it, it’s an exercise!). To do it, all you need to do is click on the 5’ limit of the gene and drag it to the desired position. You will notice that the structure of the gene will be shortly changed.
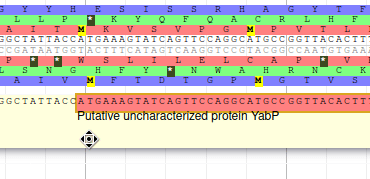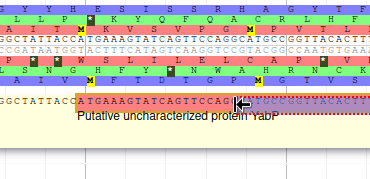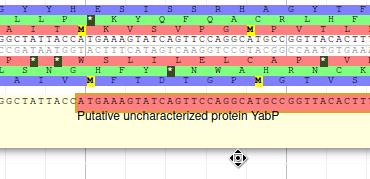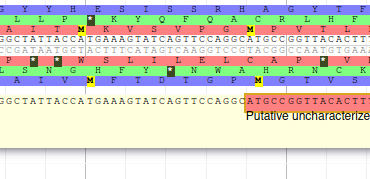
This kind of modifications is very common when using Apollo, and you can perform it at the gene level, or (for eukaryotes) at the exon/intron level. To guide you doing these changes, you should look at all the tracks available for the genome you study. RNA-Seq track are very helpful to determine the limits of coding sequences on the genome, you can find 2 RNA-Seq libraries in the track list, they were aligned on the genome using TopHat. Other tracks can be helpful, like alignements of transcripts or proteins from closely related species (or even big databanks like Swissprot or NR).
Viewing and reverting changes
Everything you do in Apollo is tracked in a database. If you right click on the YabP gene, and select Show History, you have access to the full list of all the actions that were performed on it.
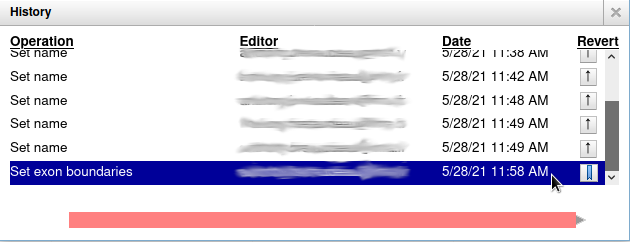
When you click on one of the steps, you can see below the list a preview of how the gene looked at the time. And you can revert to a specific version of the gene by clicking on the arrow button on the right.
Adding more functional annotation
Sometimes you’ll want to modify a gene that was predicted by Augustus, just to add functional annotation to it. Navigate to position 3000..5700, you will see an Augustus gene named NC_000913.3.g3.t1. At the same position, there are a few Blastp hits with high scores that correspond to Threonine synthase, meaning that the gene found by Augustus is probably an homolog. Let’s add this Augustus gene to the User-created Annotation track: just drag and drop it there. Now, modify the Name (Threonine synthase) and Symbol (TS), just as we did earlier, for the gene and mRNA.
If you look at the details of the blast hits, you will notice an identifier looking like that: gi|11387170|sp|P57289.1|. In this identifier, P57289 is the id of an UniProt record. Navigate to this UniProt page and you’ll find a lot more details about the protein which was found to be very similar to the gene we are currently annotating. In particular, you can see that 3 Gene Ontology (GO) terms are associated with it, in the GO - Molecular function and GO - Biological process sections. Let’s add these terms to our gene with Apollo.
Comment: Gene Ontology (GO) ConsortiumThe Gene Ontology Consortium provides with its Ontology a framework for the model of biology. The GO defines concepts/classes used to describe gene function, and relationships between these concepts. It classifies functions along three aspects:
- molecular function
- molecular activities of gene products
- cellular component
- where gene products are active
- biological process
- pathways and larger processes made up of the activities of multiple gene products.
more information can be found in the GO website.
With the gene selected, click on the GO panel, then click on the New button. We will then follow the GO annotation guidelines, filling the form like this.
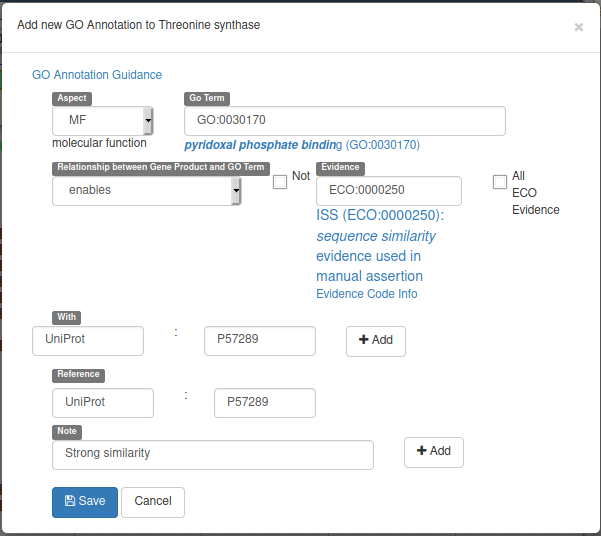
This form means that our gene will be tagged with the Go Term GO:0030170 (select it in the drop down list while typing pyridoxal phosphate binding) from the Molecular Function GO branch (MF in Aspect). This gene enables this pyridoxal phosphate binding activity, and we declare it based on the evidence code ECO:0000250 which means sequence similarity evidence used in manual assertion (exactly what we are doing). This similarity is With the UniProt:P57289 record, and we add a Reference to this record (we could add a pubmed id to reference a published result for example). Finally we add a Note saying that there’s a strong similarity.
Before saving, don’t forget to click on the two Add buttons to save the With and Note fields.
You can now do the same for the two other GO terms found on the UniProt page: threonine synthase activity and threonine biosynthetic process. Adding these terms this way allows to save the information in a computing-friendly way, which means other bioinformatics tools will be able to use make this information automatically.
Other tabs are available in the annotation panel, allowing to add Comments, external database references (DbXref) or *Attributes to genes, to record more infortmation about them.
Comparing with the official annotation
In this tutorial we are lucky as we are studying a very well known reference organism. It means we have a very good quality reference annotation provided by NCBI. You can display it in Apollo by enabling the corresponding track:
Hands On: Display NCBI annotation track
In the right hand panel at the top click on Tracks to open the track listing
In the Gene Calls group, select the
NCBI AnnotWriter Genestrack.
Now navigate along the genome, and notice the differences between the Augustus annotation, the changes you made in the User-created Annotation track, and the reference annotation. This illustrates what happens in real life: you start with an automatic annotation which is not perfect, and using Apollo you improve it and add functional annotation, which allows in the end to release a better annotation to the community.
Sequence alterations
Until now we have supposed that the quality of the genome sequence is perfect. But you might work on othr genomes where the sequence contains errors (substitutions, insertions, deletions) due to assembly problems for example. In this case, automatic annotation programs will have difficulties producing good looking gene models: there can be frame shifts within genes, or broken start/stop codons which are not detected. In this case, Apollo allows to edit the genome sequence itself.
Navigate to position 42500..44500, and show the K12 Variants track from the Variation track group. This track shows variants that were detected in this genome sequence after resequencing it. Drag the NC_000913.3.g36.t1 gene to the User-created Annotation track. Now we will register in Apollo the SNP that was detected on position 43988 (C->T): zoom to this position until you see the 6 open reading frame and the sequence. Then right click on the C nucleotide and select Create Genomic Substitution.
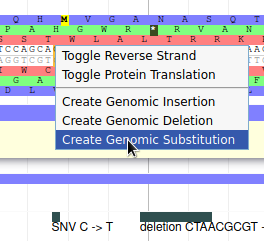
Fill the form like this, and the SNP will be saved:
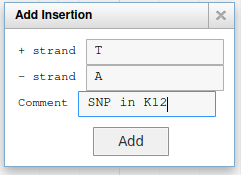
You can add other types of alterations like insertions or deletions.
Once you have added some alterations, Apollo will automatically display the effect it has on the overlapping genes.
Exporting and collaborating
Exporting annotation
You can continue improving annotation whenever you want, the Apollo server will keep your changes in a safe place for future use. However at some point you will want to export your work to perform other analyses base on it. This can be done from Galaxy:
Hands On: Export data to Galaxy
- Retrieve Data from Apollo into Galaxy ( Galaxy version 4.2.5) with the following parameters:
- “Organism Common Name Source”:
Direct Entry
- “Organism Common Name”:
E. coli K12
This tool will create new datasets in your history:
- the whole content of the User-created Annotation track, in GFF3 format
- the cDNA sequence of all the genes from this same track
- the CDS sequence of all the genes from this same track
- the peptide sequences of all the genes from this same track
- sequence alterations
You can then do any other analysis using normal Galaxy tools.
If you prefer, the same data can be downloaded directly from the Apollo right panel, in the Ref Sequence tab.
Note that if you have inserted some sequence alterations, the fasta sequences will take them into account.
Collaborating with other annotators
As explained at the beginning of this tutorial, Apollo is a collaborative annotation tool, which means you can work with other people from anywhere in the world. By default the organisms you create in Apollo are only accessible by yourself. But you can easily open the access to other people by creating a group of users on Apollo, and then allowing this group to access one or several of your organisms. This works for users having an account on the same Galaxy (most probably usegalaxy.eu).
Click on the Sharing tab in the Apollo right panel.

You should see a screen like this:
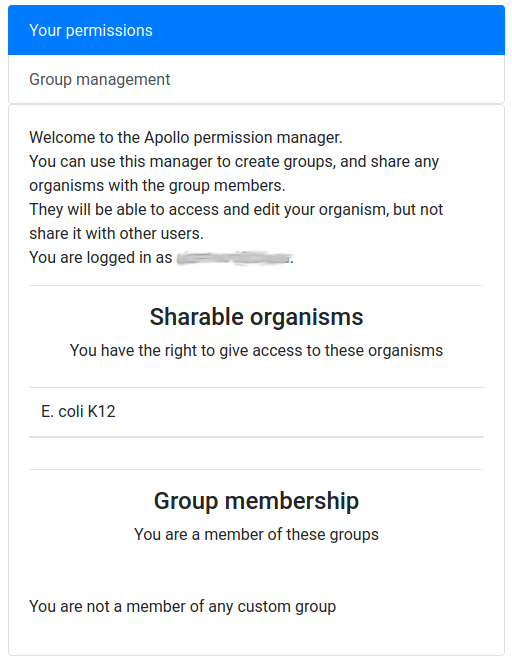
It means that you are currently not in any group, and that, as its creator, you have the right to share access to one organism: E. coli K12.
Hands On: Create a user group
Click on the Group management tab
Click on the New button
Give a name to your new group, and then click on the Create group button
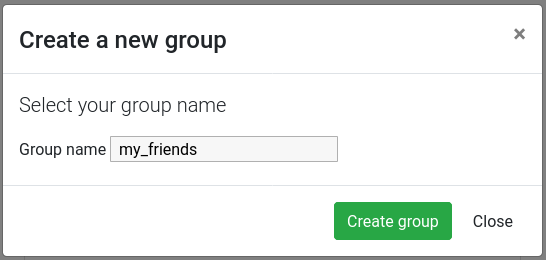
Now you should see a screen like this:
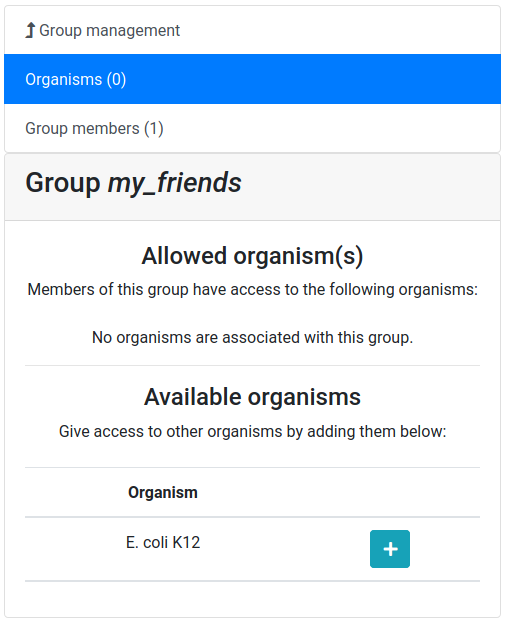
Let’s add a colleague to our newly created group.
Hands On: Adding a user in the group
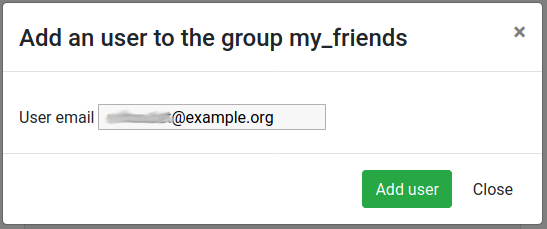
Click on the Group members tab
Click on the Add user button
Enter the email address of a user you want to work with (the one used to register on the same Galaxy server)
Click on the Add user button
And now allow the user group to access our E. coli K12 organism.
Hands On: Giving access to an organism
Click on the Organisms tab (if not already selected)
Click on the + button next to the
E. coli K12organismConfirm that you want to give access
Now the other user should be able to access your organism, and make any modifications to the annotation (creating genes, structural changes, functional annotation, …). In each gene history, Apollo keeps track of which user performed which operation, so you will always be able to know who did what on the annotation, and blame or credit them. Of course, using the same Sharing tab, you can stop at any time sharing an organism to a whole group or a specific users in a few clicks.
Conclusion
Congratulations, you finished this tutorial! By using Apollo and JBrowse, you learned how to manually refine predicted annotations and export them to Galaxy for future analyses. You also learn how to give access to your project at any other researcher, making it a real collaborative solution.
A similar tutorial for eukaryote genomes exists, using different types of evidence tracks, feel free to have a look at it to learn more.
When refinement is sufficient an updated or new version of the annotation may be exported as GFF3 as well as published as a new JBrowse directory for inspection.
What’s next?
After generating your refined annotation, you’ll want to merge it back into the official gene sets. A future tutorial will show you how to do it within Galaxy.
If a de novo set, you can export it as GFF3 and load it into a tool like Tripal to provide visualization.
You've Finished the Tutorial
Key points
Apollo is the Google Docs of the genome annotation world, real-time collaborative genome annotation.
Apollo allows a group to view and manually refine predicted genome annotations
Use Apollo to edit annotations within your group.
Export manual annotations as GFF3.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsReferences
- Stanke, M., M. Diekhans, R. Baertsch, and D. Haussler, 2008 Using native and syntenically mapped cDNA alignments to improve de novo gene finding. Bioinformatics 24: 637–644. 10.1093/bioinformatics/btn013
- Dunn, N. A., D. R. Unni, C. Diesh, M. Munoz-Torres, N. L. Harris et al., 2019 Apollo: Democratizing genome annotation (A. E. Darling, Ed.). PLOS Computational Biology 15: e1006790. 10.1371/journal.pcbi.1006790
Glossary
- OGS
- Official Gene Set
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Anthony Bretaudeau, Helena Rasche, Nathan Dunn, Mateo Boudet, Refining Genome Annotations with Apollo (prokaryotes) (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/genome-annotation/tutorials/apollo/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{genome-annotation-apollo, author = "Anthony Bretaudeau and Helena Rasche and Nathan Dunn and Mateo Boudet", title = "Refining Genome Annotations with Apollo (prokaryotes) (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/genome-annotation/tutorials/apollo/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
Funding
These individuals or organisations provided funding support for the development of this resource

You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/genome-annotation/tutorials/apollo/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: apollo_create_account owner: gga revisions: e80d29fd2a33 tool_panel_section_label: Apollo tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: apollo_create_or_update owner: gga revisions: 4abaab60f9e1 tool_panel_section_label: Apollo tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: apollo_iframe owner: gga revisions: f4e3f9480307 tool_panel_section_label: Apollo tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: apollo_list_organism owner: gga revisions: 2c749ed310da tool_panel_section_label: Apollo tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: jbrowse owner: iuc revisions: a6e57ff585c0 tool_panel_section_label: Graph/Display Data tool_shed_url: https://toolshed.g2.bx.psu.edu/