Label-free data analysis using MaxQuant
| Author(s) |
|
| Reviewers |
|
OverviewQuestions:
Objectives:
How to perform label-free analysis in MaxQuant?
Which are the most abundant proteins in serum?
How successful was the depletion of those in our experiment?
Requirements:
Analysis of human serum proteome samples with label-free quantification in MaxQuant
Time estimation: 1 hourLevel: Introductory IntroductorySupporting Materials:Published: Apr 29, 2020Last modification: May 21, 2025License: Tutorial Content is licensed under Creative Commons Attribution 4.0 International License. The GTN Framework is licensed under MITpurl PURL: https://gxy.io/GTN:T00218rating Rating: 4.8 (0 recent ratings, 5 all time)version Revision: 14
The proteome refers to the entirety of proteins in a biological system (e.g cell, tissue, organism). Proteomics is the large-scale experimental analysis of proteins and proteomes, most often performed by mass spectrometry which enables great sensitivity and throughput. Especially for complex protein mixtures, bottom-up mass spectrometry is the standard approach. In bottom-up proteomics, proteins are digested with a specific protease into peptides and the measured peptides are in silico reassembled into the corresponding proteins. Inside the mass spectrometer, not only are the peptides measured (MS1 level), but the peptides are also fragmented into smaller peptides, which are measured again (MS2 level). This is referred to as tandem-mass spectrometry (MS/MS). Identification of peptides is performed by peptide spectrum matching of the theoretical spectra generated from the input protein database (fasta file) with the measured spectra. Peptide quantification is most often performed by measuring the area under the curve of the MS1 level peptide peaks, but special techniques such as TMT (Tandem Mass Tag) allow for the quantification of peptides on the MS2 level. Nowadays, bottom-up tandem-mass spectrometry approaches allow for the identification and quantification of several thousand proteins.
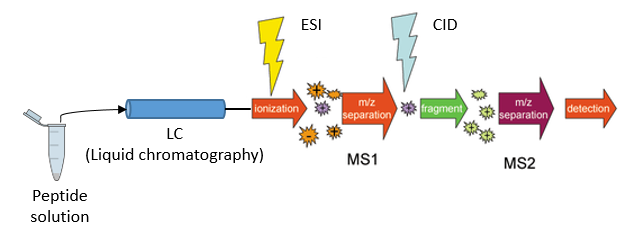 Open image in new tab
Open image in new tabA plethora of software solutions were developed for the analysis of proteomics data. MaxQuant is one of the most popular proteomics software because it is an easy-to-use and free software that offers functionalities for nearly all kinds of proteomics data analysis challenges Cox and Mann 2008. Mass spectrometry raw data is normally obtained in a vendor-specific, proprietary file format. MaxQuant can directly take those raw files as input. For peptide identification,n MaxQuant uses a search engine called “Andromeda”. MaxQuant offers highly accurate functionalities for many different proteomics quantification strategies, e.g., label-free, SILAC,and TMT.
Blood is a commonly used biofluid for diagnostic procedures. The cell-free liquid blood portion is called plasma, and after coagulation serum. Plasma and serum proteomics are frequently performed to find new biomarkers, e.g., for diagnostic purposes and personalized medicine (Geyer et al. 2017). Serum and Plasma proteomics are particularly challenging due to protein concentration differences in the order of ten magnitudes. Therefore, most sample preparation protocols include a depletion step in which the most abundant proteins are (partially) depleted from the sample,e e.g., via columns with immobilized antibodies.
This stand-alone tutorial introduces the data analysis from raw data files to protein identification and quantification of two label-free human serum samples with the MaxQuant software. One sample is a pure serum sample, while the other sample has been depleted of several abundant blood proteins. One of the questions in this tutorial is to find out which sample was depleted and which was not.
For more advanced proteomics workflows, please consult the OpenMS identification, quantification, as well as SearchGUI/PeptideShaker tutorials.
AgendaIn this tutorial, we will cover:
Get data
The serum proteomic samples and the fasta file for this training were deposited at Zenodo. It is of course, possible to use other fasta files that contain human proteome sequences, but to ensure that the results are compatible, we recommend using the provided fasta file. MaxQuant not only adds known contaminants to the fasta file, but also generates the “decoy” hits for false discovery rate estimation itself, therefore, the fasta file is not allowed to have decoy entries. To learn more about fasta files, have a look at Protein FASTA Database Handling.
Hands On: Data upload
Create a new history for this tutorial and give it a meaningful name
To create a new history simply click the new-history icon at the top of the history panel:
Import the fasta and raw files from Zenodo
https://zenodo.org/record/4274987/files/Protein_database.fasta https://zenodo.org/record/4274987/files/Sample1.raw https://zenodo.org/record/4274987/files/Sample2.raw
- Copy the link location
Click galaxy-upload Upload at the top of the activity panel
- Select galaxy-wf-edit Paste/Fetch Data
Paste the link(s) into the text field
Press Start
- Close the window
Once the files are green, rename the raw datasets into ‘sample1’ and ‘sample2’ and the fasta file into ‘protein database’
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, change the Name field
- Click the Save button
Set the data type to thermo.raw for ‘sample1’ and ‘sample2’
- Click on the galaxy-pencil pencil icon for the dataset to edit its attributes
- In the central panel, click galaxy-chart-select-data Datatypes tab on the top
- In the galaxy-chart-select-data Assign Datatype, select
thermo.rawfrom “New Type” dropdown
- Tip: you can start typing the datatype into the field to filter the dropdown menu
- Click the Save button


MaxQuant Analysis
The MaxQuant Galaxy implementation contains the most important MaxQuant parameters. As an alternative, MaxQuant (using mqpar.xml) tool can be used with a preconfigured mqpar.xml file. We will explain the parameters after starting the MaxQuant run which takes some time to finish.
Hands On: MaxQuant analysis
- MaxQuant ( Galaxy version 1.6.10.43+galaxy3) with the following parameters
- In “Input Options”:
- param-file “FASTA files”:
protein database- “Identifier parse rule”:
>.*\|(.*)\|- “Description parse rule”:
>(.*) OS- In “Search Options”:
- “minimum unique peptides”:
1- In “Parameter Group”:
- param-files “Infiles”:
sample1,sample2- “missed cleavages”:
1- “enzyme”:
Trypsin/P- “Quantitation Methods”:
label free quantification- “Generate PTXQC (proteomics quality control pipeline) report? (experimental setting)”:
True- In “Output Options”:
- “Select the desired outputs.”:
Protein GroupsPeptidesmqpar.xmlComment: Protein GroupsProteins that share all their peptides with other proteins cannot be unambiguously identified. Therefore, MaxQuant groups such proteins into one protein group and only one common quantification will be calculated. The different protein properties are separated by a semicolon.
More details on MaxQuant Parameters
The “parse rules” in the input section are applied to the fasta sequence headers. Regular expressions can be adjusted to keep different information from the fasta file header. Examples are given in the MaxQuant help section at the bottom of the tool. The fasta file for this training comes from Uniprot, therefore, the parse rules are adjusted accordingly. Consider the FASTA header like this :
| ```>sp | P02768 | ALBU_HUMAN Serum albumin OS=Homo sapiens GN=ALB PE=1 SV=1 |
1) Identifier parse rule >.*\|(.*)\|
> FASTA headers always start with this symbol. Matches with the initial >
.* matches sp
\| matches the first |
(.*) matches P02768
\| matches the second |
2) Description parse rule >(.*) OS
> matches with the initial >
(.*) matches everything it can. It matches sp|P02768|ALBU_HUMAN Serum albumin
OS matches OS ```
The “minimum peptide length” defines the minimum number of amino acids a peptide should have to be included for protein identification and quantification. Below 7 amino acids a peptide cannot be unique and is therefore not informative, thus typical values are in the range 7-9.
Several, even longer peptides are not unique, meaning that they are shared by several proteins e.g. when they are part of a common protein domain. During protein inference, the peptides are statistically assembled into the corresponding proteins and the decision should be mainly based on the unique peptides. Therefore, we set “min unique peptides” to 1 - only proteins that have at least one unique peptide are reported in the output table.
In most bottom-up proteomics experiments, Trypsin is used as a protease because it has many advantages, such as its accurate cleavage specificity. Trypsin cleaves peptides C-terminal of Arginine (R) and Lysine (K), except when those are followed by Proline (P). Therefore, in MaxQuant, the default “enzyme” is set to Trypsin/P. This trypsin-specific cleavage rule is used by MaxQuant to perform an in silico digestion of the protein database that was provided in the fasta file.
Protease digestion is not always complete, therefore, we set the “number of missed cleavages” to 1, meaning that the in silico digestion also includes peptides that have an additional Arginine or Lysine in their sequence.
 Open image in new tab
Open image in new tabFrom the in silico generated peptide database the masses of the peptides are calculated and matched to the measured masses in order to identify them. A peptide’s mass will change due to peptide modifications such as chemical labelling, for example, applied in different quantitation strategies or biological post-translational modifications. Therefore, it is also important to include possible peptide modifications in the in silico generated peptide mass list. “Fixed modifications” are modifications that occur on every occurrence of the specific amino acid. Those are often artificially introduced modifications such as Carbamidomethylation of cysteins (C) to prevent re-formation of the disulfide bridges. This is a common procedure in proteomics sample preparation and, therefore also the default option in MaxQuant: Carbamidomethyl (C). “Variable modifications” are modifications that do not occur on every amino acid, such as the Oxidation of Methionine might only occur on some Methionines and not all, but only a few peptide N-termini are acetylated. Variable modifications increase the in silico peptide database because each peptide’s mass is calculated once with and once without the additional modification. To keep computation times as short as possible, we did not use any variable modification in this training, despite the MaxQuant default, the Oxidation of Methionine and Acetylation of N-termini would have been completely valid to use.
MaxQuant supports different “Quantitation Methods”. The three main categories are label-free quantification, label-based quantification and reporter ion MS2 quantification. In this tutorial, we have chosen label-free because we did not apply any specific labeling/quantitation strategy to the samples.
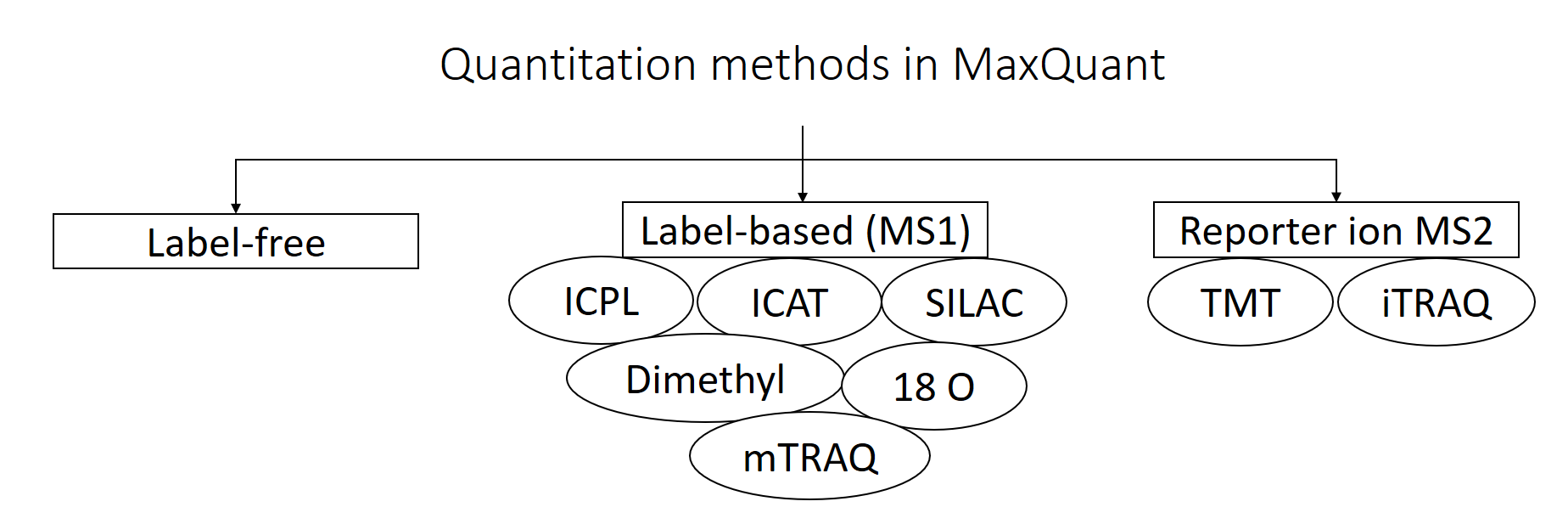 Open image in new tab
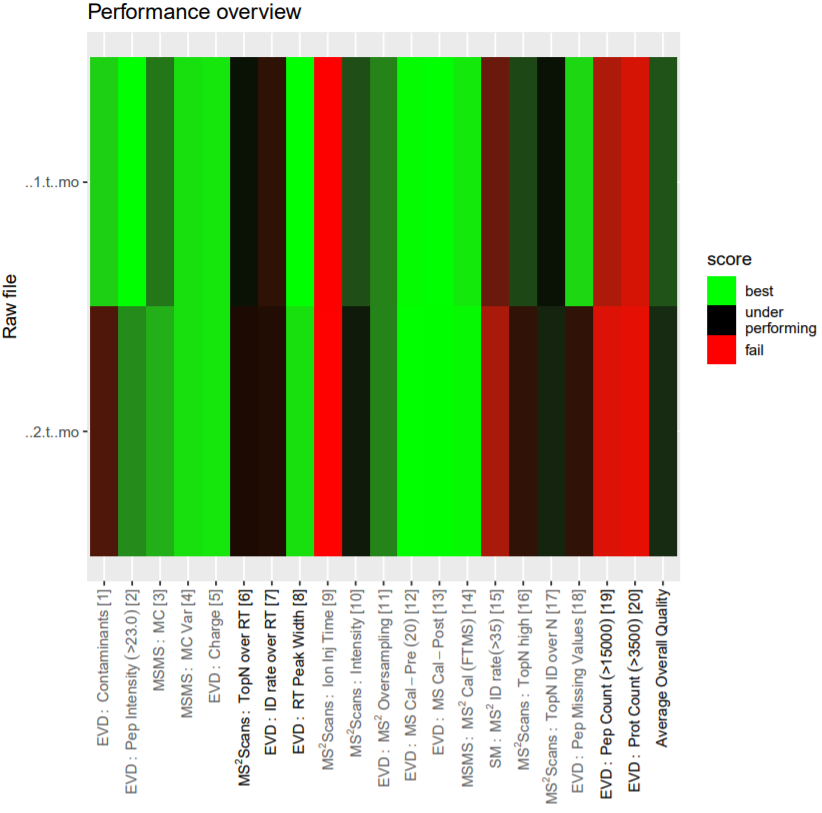
Open image in new tabThe PTXQC software was built to enable direct proteomics quality control from MaxQuant result files. This quality control can be directly used in the Galaxy MaxQuant wrapper by setting “Generate PTXQC” to yes. This will generate a pdf file with multiple quality control plots. Be aware that the cutoffs set in PTXQC might not apply to your experiment and mass spectrometer type, and therefore, “underperforming” and “fail” do not necessarily mean that the quality is poor.
 Open image in new tab
Open image in new tabMaxQuant automatically generates several output files. In the “Output Options” all or some of the output files can be selected. The protein information can be obtained by selecting Protein Groups, while the peptide information is obtained by choosing Peptides. The applied MaxQuant parameters are stored in the mqpar.xml. This file can be reused as an input file in the MaxQuant (using mqpar.xml) tool.
For pre-fractionated data an “experimental design template” has to be used. This has to be a tab-separated text file with a column for the fractions (e.g., 1-10) and a column for the experiment (sample1, sample2, sample3) and a column for post-translational modifications (PTM). Examples are given in the help section of the MaxQuant tool.
“Match between runs” allows to transfer of identifications (peptide sequences) from one run to another. If the MS1 (full-length peptide) signal is present in both runs, but was only selected for fragmentation in one of them, MaxQuant can transfer the resulting peptide sequence to the run where the MS1 peptide was not fragmented. The Information if a peptide was identified via fragmentation (MS/MS) or match between runs (matching) can be found in the evidence output.
MaxQuant allows processing different raw files with different parameters. In this tutorial, we have loaded both files into the same “parameter group” in order to process them with the same parameters. To apply different parameters, new parameter groups can be added by clicking on the param-repeat “insert parameter group” button. In each “parameter group” one or several raw files can be specified, and for them only the parameters specified within this parameter group section are applied.
In case the MaxQuant run is not yet finished, the results can be downloaded from Zenodo to be able to continue the tutorial
Import the files from Zenodo
https://zenodo.org/record/4274987/files/PTXQC_report.pdf https://zenodo.org/record/4274987/files/MaxQuant_Protein_Groups.tabular https://zenodo.org/record/4274987/files/MaxQuant_Peptides.tabular https://zenodo.org/record/4274987/files/MaxQuant_mqpar.xml
Question
- How many proteins were found in total?
- How many peptides were found in total?
- How many proteins identified and quantified? (Tip: There is a tool called “filter data on any column”, select the LFQ (Label free quantification) column for both files and remove rows containing “0”)
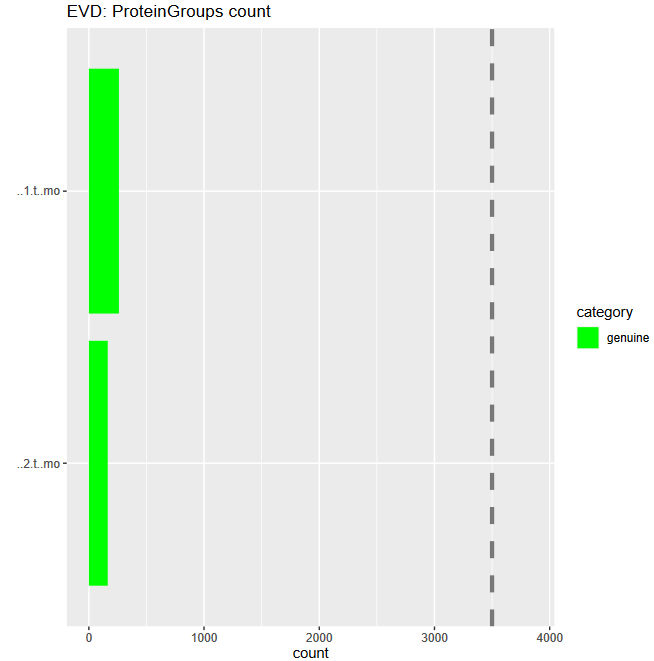
- 271 proteins (groups) were found in total.
- 2410 peptides were found in total.
- Sample1: 237, Sample2: 123 (filter data on any column tool on the
protein groupsfile “with following condition”c32!=0orc33!=0and *“Number of header lines to skip”1)
Quality control results
To get a first overview of the MaxQuant results, the PTXQC report is helpful. Click on the galaxy-eye eye of the PTXQC pdf file to open it in Galaxy. Screening through the different plots might already give you a hint which of the samples was pure and which was depleted of abundant proteins. Both samples failed in some categories (see Figure 4 above), especially due to low peptide and protein numbers, which is expected in serum samples and therefore not a quality problem.
Question
- In which sample were more contaminantes quantified?
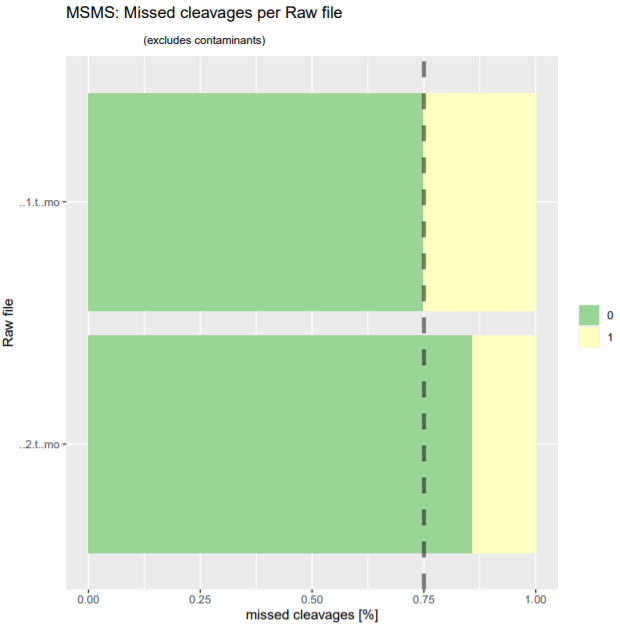
- How good was the tryptic digestion (percentage of zero missed cleavages)?
- Which sample yielded more protein identifications?
- Do you already have a guess on which sample was depleted?
- Sample 2 has more contaminants, especially serum albumin is high abundant.
- The digestion was not ideal, but good enough to work with. The proportion of zero missed cleavages was 75% for sample1 and around 85% for sample2.
- Sample 1 yielded more protein identifications
- Sample 1, more information can be found in the next section.

Serum composition
To explore the proteomic composition of the two serum samples, some postprocessing steps on the Protein Groups file are necessary. The Protein Groups file contains all relevant information on the protein level. The best way to explore this vast table is by clicking on the scratch book galaxy-scratchbook on the top menu. Clicking on the galaxy-eye eye icon opens the Protein Groups file. Galaxy does not work with the names of the columns but instead with their number. Find the column numbers for: Fasta headers (includes protein ID + name + species), LFQ intensities for each sample and reverse proteins. First we remove “decoy” proteins, which are named “reverse” in MaxQuant. Next, we remove contaminants. For non-human samples, we could just remove all proteins that are marked with a “+” in the “potential contaminant” column. We have seen before that many human proteins were marked as contaminant and as we study a human sample we don’t want to remove them. Therefore, we only remove non-human contaminant proteins. Then, we shrink the file to keep only columns that are interesting in the next steps: the fasta header and the columns with LFQ intensities for both files. To find the most abundant proteins per sample, the LFQ intensities can be sorted. On this sorted dataset, we will explore the composition of the serum proteins within both samples using an interactive pie charts diagram.
Hands On: Exploring serum composition
- Filter with the following parameters:
- param-file “Filter”:
proteinGroups(output of MaxQuant tool)- “With following condition”:
c38!="+"- “Number of header lines to skip”:
1- Select with the following parameters:
- param-file “Select lines from”:
filter_file(output of Filter tool)- “the pattern”:
(HUMAN)|(Majority)- Cut with the following parameters:
- “Cut columns”:
c8,c32,c33- param-file “From”:
select_file(output of Select tool)- Sort ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
cut_file(output of Cut tool)- “Number of header lines”:
1- In “Column selections”:
- “on column”:
c2- “in”:
Descending order- “Flavor”:
General numeric sort ( scientific notation -g)- Sort ( Galaxy version 1.1.1) with the following parameters:
- param-file “Sort Query”:
cut_file(output of Cut tool)- “Number of header lines”:
1- In “Column selections”:
- “on column”:
c3- “in”:
Descending order- “Flavor”:
General numeric sort ( scientific notation -g)- Click galaxy-barchart “Visualize this data” on the last Sort tool result.
- Select
Pie chart (NVD3)- “Provide a title”:
Serum compositions- Click
Select datagalaxy-chart-select-data- “Provide a label”:
sample1- “Labels”:
Column: 1- “Values”:
Column: 2- Click
Insert data series- “Provide a label”:
sample2- “Labels”:
Column: 1- “Values”:
Column: 3- Save galaxy-save (file is saved under “User” –> “Visualizations”)
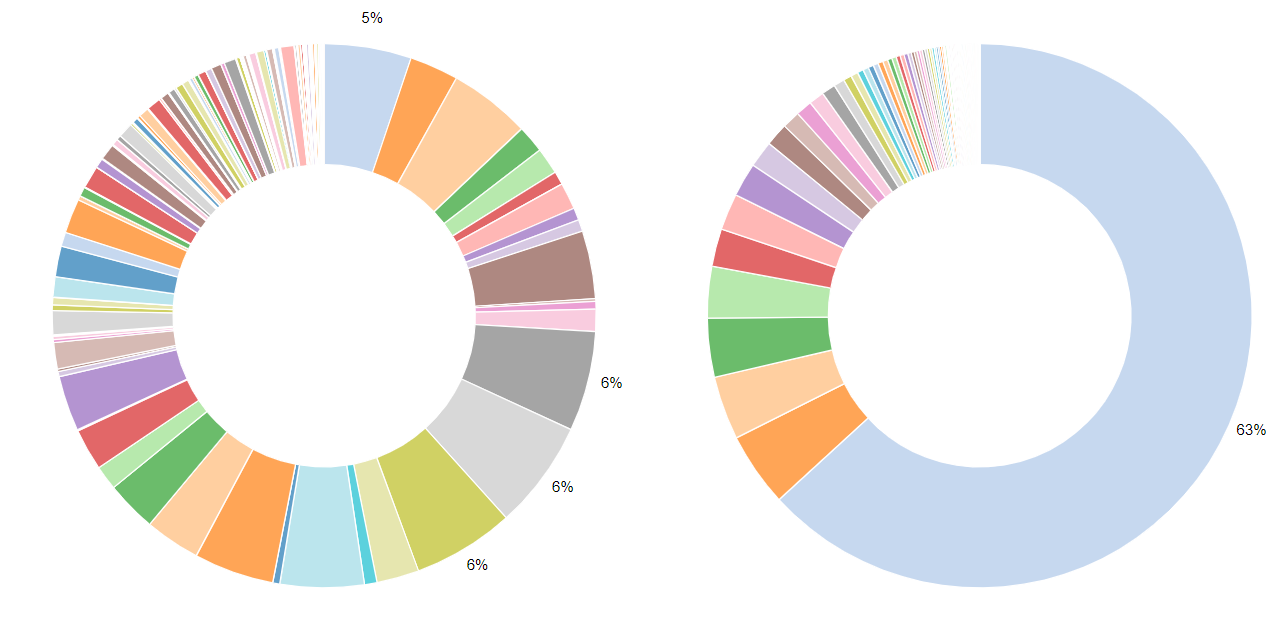 Open image in new tab
Open image in new tabQuestion
- How many decoy proteins were removed?
- What are the top 5 most abundant proteins in both files? Do they reflect typical serum proteins?
- Which sample was depleted for the top serum proteins?
- How much did the serum albumin abundance percentage decrease? Was the depletion overall succesful?
- 2 (272 lines (Protein Groups) minus 270 lines (Filter))
- Sample1: Complement C4-A, Ceruloplasmin, Hemopexin, Serum albumin, Complement factor B. Sample2: Serum albumin, Immunoglobulin heavy constant gamma 1, Serotransferrin, Immunoglobulin kappa constant, Haptoglobin. All of those proteins are typical (high abundant) serum proteins (plasma proteins found by MS).
- Sample1 was depleted, sample2 was pure serum.
- In the depleted sample1, there is a depletion in some of the most abundant proteins, especially Albumin, which proportion of the total sample intensities decreased by 58 percentage. Compared to the pure serum the depleted sample showed a duplication of identified and quantified proteins rendering it quite successful. However, there is still room for improvement as some of the most abundant proteins which should have been depleted did not change their abundance compared to the overall protein abundance.
Quantitative Assessment
After analyzing the composition of each sample separately, the intensities between both samples are compared. For this, the intensity values are log2-transform and the normal distribution is visualized as boxplots, this requires cutting only the relevant columns before visualization. Next the log2 fold change is calculated and its distribution visualized as histogram. The log2 fold change helps to find proteins with abundances changes between the samples.
Hands On: Quantitative Assessment
- Compute ( Galaxy version 1.3.0) with the following parameters:
- “Add expression”:
log(c2,2)- param-file “as a new column to”:
cut_file(output of Cut tool)- “Skip a header line”:
yes
- “The new column name”:
log2 intensity sample1- Compute ( Galaxy version 1.3.0) with the following parameters:
- “Add expression”:
log(c3,2)- param-file “as a new column to”:
compute_file(output of Compute tool)- “Skip a header line”:
yes
- “The new column name”:
log2 intensity sample2- Cut with the following parameters:
- “Cut columns”:
c4,c5- param-file “From”:
compute_file(output of the last Compute tool)- Click galaxy-barchart “Visualize this data” on the cut tool result.
- Select
box plot(jqPlot)- “Use multi-panels”:
No- Click
Select datagalaxy-chart-select-data- “Provide a label”:
log2 sample1- “Observations”:
Column: 1- Click
Insert data series- “Provide a label”:
log sample2- “Observations”:
Column: 2- Confirm and save galaxy-save (file is saved under “User” –> “Visualizations”)
- Compute ( Galaxy version 1.3.0) with the following parameters:
- “Add expression”:
c4-c5- param-file “as a new column to”:
compute_file(output of the last Compute tool)- “Skip a header line”:
yes
- “The new column name”:
log2 Fold Change (sample1/sample2)- Histogram ( Galaxy version 1.0.4) with the following parameters:
- param-file “Dataset”:
compute_file(output of the previous Compute tool)- “Numerical column for x axis”:
c6- “Label for x axis”:
log2 Fold Change
Question
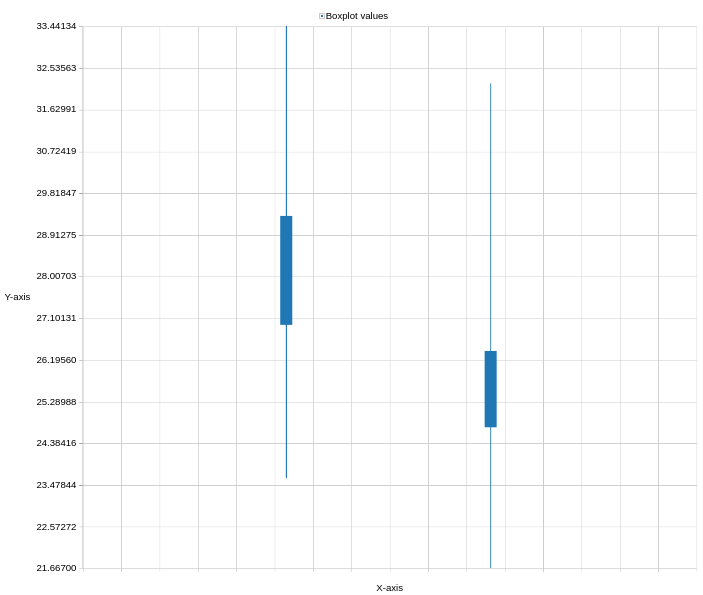
- Describe the distribution of the log2 intensities in the box plots.
- How much is the log2 fold change of serum albumin and what does it mean?
- What does the distribution of the log2 fold changes mean?
- The log2 transformation leads to a close to normal intensity distribution for both samples. Intensities in the depleted sample are shifted towards higher values compared to the non-depleted samples. The big difference comes from artificially depleting (changing) protein intensities.
- The log2 fold change (depleted vs. not depleted samples) is about -2.91. This means that the abundance in the not depleted sample is about 2^2.91 = 7.52 times higher than in the depleted sample, showing again that a large proportion of serum albumin was successfully removed by the antibody columns.
- Most of the log2 fold changes are larger than zero. This means that many proteins have higher intensities in the depleted sample compared to the non-depleted sample. These are the proteins that benefited from the depletion of serum albumin and other highly abundant serum proteins. There is also a maximum around zero, meaning that a substantial amount of proteins had a similar abundance in both samples. The negative log2 fold changes derive from the proteins that were depleted, e.g., serum albumin.

{kind=link}
For this training, we have chosen two small example files to keep analysis time minimal. Real proteomic projects comprise more samples, leading to longer MaxQuant run times from many hours to several days (depending on input file size, number of input files, and parameters). Real projects also require different follow-up analyses. Here are some things to consider for your proteomic project:
- The columns in the MaxQuant output file change with the number of input files. Before using the cut tool, open the output file and check which columns contain the LFQ intensities - then adjust the cut tool to cut all those columns from the file.
- A necessary first step is to log2-transform the LFQ intensities.
- Even though LFQ intensities are already normalized, before statistical analysis, it is recommended to median normalize the LFQ intensities for each sample. Control the intensity distribution with histograms or boxplots. Even before normalization, the boxplots should already be more similar in their intensity range if a normal biological replicate was analyzed (and not a different sample preparation protocol as in the training dataset). After normalization, box plot medians should be very similar.
- Often, proteomic projects aim to find differentially regulated proteins across conditions. Classical statistical methods like t-test and ANOVA are not ideal options but ok when multiple testing correction (e.g. Benjamini-Hochberg) is performed afterwards. The better options are algorithms tailored for the analysis of omics intensity data such as LIMMA (Ritchie et al. 2015), SAM (Tusher et al. 2001) and MSstats (Choi et al. 2014) MSstats ( Galaxy version 3.20.1.0). Do not apply statistical methods designed for count data (e.g. RNA-seq) such as Limma-voom or DESq2 - those are not applicable for proteomics intensity data.
You've Finished the Tutorial
Key points
MaxQuant offers a single tool solution for protein identification and quantification.
Label-free quantitation reveals the most abundant proteins in serum samples.
Frequently Asked Questions
Have questions about this tutorial? Have a look at the available FAQ pages and support channelsUseful literature
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
References
- Tusher, V. G., R. Tibshirani, and G. Chu, 2001 Significance analysis of microarrays applied to the ionizing radiation response. Proceedings of the National Academy of Sciences 98: 5116–5121. 10.1073/pnas.091062498
- Cox, J., and M. Mann, 2008 MaxQuant enables high peptide identification rates, individualized p.p.b.-range mass accuracies and proteome-wide protein quantification. Nature Biotechnology 26: 1367–1372. 10.1038/nbt.1511
- Choi, M., C.-Y. Chang, T. Clough, D. Broudy, T. Killeen et al., 2014 MSstats: an R package for statistical analysis of quantitative mass spectrometry-based proteomic experiments. Bioinformatics 30: 2524–2526. 10.1093/bioinformatics/btu305 https://academic.oup.com/bioinformatics/bioinformatics/article/2748156/MSstats: ISBN: 1367-4811 (Electronic) 1367-4803 (Linking)
- Ritchie, M. E., B. Phipson, D. Wu, Y. Hu, C. W. Law et al., 2015 limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Research 43: e47–e47. 10.1093/nar/gkv007
- Geyer, P. E., L. M. Holdt, D. Teupser, and M. Mann, 2017 Revisiting biomarker discovery by plasma proteomics. Molecular Systems Biology 13: 942. 10.15252/msb.20156297
Feedback
Did you use this material as an instructor? Feel free to give us feedback on how it went.
Did you use this material as a learner or student? Click the form below to leave feedback.

Citing this Tutorial
- Melanie Föll, Matthias Fahrner, Label-free data analysis using MaxQuant (Galaxy Training Materials). https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/maxquant-label-free/tutorial.html Online; accessed TODAY
- Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
- Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
Congratulations on successfully completing this tutorial!@misc{proteomics-maxquant-label-free, author = "Melanie Föll and Matthias Fahrner", title = "Label-free data analysis using MaxQuant (Galaxy Training Materials)", year = "", month = "", day = "", url = "\url{https://training.galaxyproject.org/training-material/topics/proteomics/tutorials/maxquant-label-free/tutorial.html}", note = "[Online; accessed TODAY]" } @article{Hiltemann_2023, doi = {10.1371/journal.pcbi.1010752}, url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752}, year = 2023, month = {jan}, publisher = {Public Library of Science ({PLoS})}, volume = {19}, number = {1}, pages = {e1010752}, author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and}, editor = {Francis Ouellette}, title = {Galaxy Training: A powerful framework for teaching!}, journal = {PLoS Comput Biol} }
You can use Ephemeris's
shed-tools installcommand to install the tools used in this tutorial.shed-tools install [-g GALAXY] [-a API_KEY] -t <(curl https://training.galaxyproject.org/training-material/api/topics/proteomics/tutorials/maxquant-label-free/tutorial.json | jq .admin_install_yaml -r)Alternatively you can copy and paste the following YAML
--- install_tool_dependencies: true install_repository_dependencies: true install_resolver_dependencies: true tools: - name: text_processing owner: bgruening revisions: d698c222f354 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: column_maker owner: devteam revisions: be25c075ed54 tool_panel_section_label: Text Manipulation tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: histogram owner: devteam revisions: 6f134426c2b0 tool_panel_section_label: Graph/Display Data tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: maxquant owner: galaxyp revisions: 37d669de2828 tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/ - name: msstats owner: galaxyp revisions: 52ac6fde9a5b tool_panel_section_label: Proteomics tool_shed_url: https://toolshed.g2.bx.psu.edu/