Durante il sequenziamento, le basi nucleotidiche di un campione di DNA o RNA (detto libreria) vengono determinate dal sequenziatore. Per ogni frammento della libreria viene generata una sequenza, chiamata anche lettura (read), che è semplicemente una successione di nucleotidi.
Le moderne tecnologie di sequenziamento possono generare un numero enorme di letture in un singolo esperimento. Tuttavia, nessuna tecnologia di sequenziamento è perfetta e ogni strumento produce diversi tipi e quantità di errori, come l’identificazione errata di nucleotidi.
Queste basi chiamate in modo errato derivano dalle limitazioni tecniche proprie di ciascuna piattaforma di sequenziamento.
È quindi necessario comprendere, identificare ed escludere i tipi di errore che possono influire sull’interpretazione delle analisi successive.
Il controllo di qualità delle sequenze rappresenta pertanto un primo passo essenziale dell’analisi: individuare tempestivamente gli errori consente di risparmiare tempo nelle fasi successive.
Crea una nuova storia per questa esercitazione e assegnale un nome appropriato.
Per creare una nuova storia è sufficiente fare clic sull’icona new-history nella parte superiore del pannello della storia:
Fare clic su galaxy-pencil (Modifica) accanto al nome della storia (che per impostazione predefinita è “Storia senza nome”)
Digitare il nuovo nome
fare clic su Salva
Per annullare la ridenominazione, fare clic sul pulsante galaxy-undo “Annulla”
Se non si ha l’icona galaxy-pencil (Modifica) accanto al nome della cronologia (cosa che può accadere se si utilizza una versione precedente di Galaxy), procedere come segue:
Fare clic su Cronologia senza nome (o sul nome attuale della cronologia) (Clicca per rinominare la cronologia) nella parte superiore del pannello della cronologia
Digitare il nuovo nome
Premere Invio
Importa il file female_oral2.fastq-4143.gz da Zenodo oppure dalla libreria di dati (chiedi al tuo istruttore). Si tratta di un campione di microbioma prelevato dalla bocca di un serpente Jacques et al. 2021.
Fare clic su galaxy-uploadCarica i dati nella parte superiore del pannello degli strumenti
Selezionare galaxy-wf-editIncollare/recuperare i dati
Incollare il/i link nel campo di testo
Premere Avvio
Chiude la finestra
In alternativa al caricamento dei dati da un URL o dal proprio computer, i file possono essere resi disponibili da una libreria di dati condivisi:
Entrare in Librerie (pannello sinistro)
Navigare verso alla cartella corretta indicata dal vostro istruttore. Nella maggior parte dei Galaxies i dati delle esercitazioni vengono forniti in una cartella denominata GTN - Materiale –> Nome argomento -> Nome esercitazione.
selezionare i file desiderati
Fare clic su Aggiungi alla cronologiagalaxy-dropdown vicino alla parte superiore e selezionare as Datasets dal menu a tendina
Nella finestra pop-up, scegliere
“Seleziona cronologia “: la cronologia in cui si desidera importare i dati (o crearne una nuova)
Cliccare su Import
Rinomina il dataset importato in Reads.
Abbiamo appena importato un file in Galaxy. Questo file è simile ai dati che potremmo ottenere direttamente da un impianto di sequenziamento: un file FASTQ.
Pratica: Ispezione del file FASTQ
Ispeziona il file facendo clic sull’icona galaxy-eye (occhio)
Anche se a prima vista può sembrare complesso (e in parte lo è), il formato FASTQ è facile da comprendere con una breve spiegazione.
Ogni lettura, che rappresenta un frammento della libreria, è codificata in 4 righe:
Line
Description
1
Inizia sempre con @ seguito dalle informazioni relative alla lettura
2
Contiene la sequenza nucleotidica effettiva
3
Inizia sempre con + e talvolta ripete le informazioni della riga 1
4
Contiene una stringa di caratteri che rappresentano i punteggi di qualità associati a ciascuna base della sequenza; deve avere lo stesso numero di caratteri della riga 2
Quindi, ad esempio, la prima sequenza nel nostro file è:
significa che il frammento denominato @M00970 corrisponde alla sequenza di DNA GTGCCAGCCGCCGCGGTAGTCCGACGTGGCTGTCTCTTATACACATCTCCGAGCCCACGAGACCGAAGAACATCTCGTATGCCGTCTTCTGCTTGAAAAAAAAAAAAAAAAAAAACAAAAAAAAAAAAAGAAGCAAATGACGATTCAAGAAAGAAAAAAACACAGAATACTAACAATAAGTCATAAACATCATCAACATAAAAAAGGAAATACACTTACAACACATATCAATATCTAAAATAAATGATCAGCACACAACATGACGATTACCACACATGTGTACTACAAGTCAACTA e questa sequenza è stata sequenziata con una qualità GGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGGFGGGFGGGGGGAFFGGFGGGGGGGGFGGGGGGGGGGGGGGFGGG+38+35*311*6,,31=******441+++0+0++0+*1*2++2++0*+*2*02*/***1*+++0+0++38++00++++++++++0+0+2++*+*+*+*+*****+0**+0**+***+)*.***1**//*)***)/)*)))*)))*),)0(((-((((-.(4(,,))).,(())))))).)))))))-))-(.
Ma cosa significa questo punteggio di qualità?
Il punteggio di qualità per ogni sequenza è una stringa di caratteri, uno per ogni base della sequenza nucleotidica, utilizzata per caratterizzare la probabilità di errata identificazione di ogni base. Il punteggio è codificato utilizzando la tabella dei caratteri ASCII (con alcune differenze storiche):
Per risparmiare spazio, il sequenziatore registra un carattere ASCII per rappresentare i punteggi da 0 a 42. Ad esempio, 10 corrisponde a “+”. Ad esempio, 10 corrisponde a “+” e 40 a “I”. FastQC sa come tradurlo. Questo viene spesso chiamato punteggio “Phred”.
Quindi a ogni nucleotide è associato un carattere ASCII che rappresenta il suo punteggio di qualità Phred, la probabilità di una chiamata di base errata:
Phred Quality Score
Probability of incorrect base call
Base call accuracy
10
1 in 10
90%
20
1 in 100
99%
30
1 in 1000
99.9%
40
1 in 10,000
99.99%
50
1 in 100,000
99.999%
60
1 in 1,000,000
99.9999%
Cosa rappresenta 0-42? Questi numeri, se inseriti in una formula, ci dicono la probabilità di errore per quella base. Questa è la formula, dove Q è il nostro punteggio di qualità (0-42) e P è la probabilità di errore:
Q = -10 log10(P)
Utilizzando questa formula, possiamo calcolare che un punteggio di qualità di 40 significa solo 0,00010 probabilità di errore!
Domanda
Quale carattere ASCII corrisponde al peggior punteggio Phred per Illumina 1.8+?
Qual è il punteggio di qualità Phred del 3° nucleotide della prima sequenza?
Come si calcola la precisione della base nucleotidica con il codice ASCII /?
Qual è la precisione di questo terzo nucleotide?
Il punteggio Phred peggiore è il più basso, quindi 0. Per Illumina 1.8+, corrisponde al carattere !.
Il terzo nucleotide della prima sequenza ha un carattere ASCII G, che corrisponde a un punteggio di 38.
Il calcolo può essere eseguito come segue:
Il codice ASCII per / è 47
Punteggio di qualità = 47-33=14
Formula per trovare la probabilità di errore: \(P = 10^{-Q/10}})
Probabilità di errore = \(10^{-14/10}) = 0,03981
Quindi Accuratezza = 100 - 0,03981 = 99,96%
Il nucleotide corrispondente G ha un’accuratezza di quasi il 96%
Commento
L’attuale versione di Illumina (1.8+) utilizza il formato Sanger (Phred+33).Se si lavora con set di dati più vecchi, si possono incontrare altri schemi di punteggio. FastQCtool, uno strumento che useremo più avanti in questo tutorial, può essere utilizzato per determinare quale tipo di codifica della qualità viene usata, analizzando l’intervallo dei valori Phred presenti nel file FASTQ.
Guardando il file in Galaxy, sembra che la maggior parte dei nucleotidi abbia un punteggio elevato (G corrisponde a un punteggio 38). È vero per tutte le sequenze? E per l’intera lunghezza della sequenza?
Valutazione della qualità con FASTQE 🧬😎 - solo letture brevi
Per esaminare la qualità delle sequenze lungo tutte le letture, possiamo usare FASTQE FASTQE. Sii tratta di uno strumento open-source che offre un modo semplice e divertente per valutare la qualità dei dati di sequenziamento grezzi, rappresentandoli anche come emoji.
Può essere utile per ottenere rapidamente un’idea generale della qualità dei dati prima di procedere con analisi più approfondite.
Pratica: Controllo della qualità
Esegui il FASTQE ( Galaxy version 0.3.1+galaxy0) con i seguenti parametri
param-files“FastQ data”: Reads
param-select“Score types to show”: Mean
Ispeziona il file HTML generato.
Invece di analizzare i punteggi di qualità per ogni singola lettura, FASTQE valuta la qualità complessiva di tutte le letture di un campione e calcola la media per ogni posizione nucleotidica lungo la lunghezza delle letture. Di seguito sono riportati i valori medi per questo set di dati:
È possibile consultare il punteggio associato a ciascuna emoji nella documentazione di fastqe. Le emoji sottostanti, con punteggi Phred inferiori a 20, sono quelle che speriamo di non vedere troppo spesso.
Phred Quality Score
ASCII code
Emoji
0
!
🚫
1
”
❌
2
#
👺
3
$
💔
4
%
🙅
5
&
👾
6
’
👿
7
(
💀
8
)
👻
9
*
🙈
10
+
🙉
11
,
🙊
12
-
🐵
13
.
😿
14
/
😾
15
0
🙀
16
1
💣
17
2
🔥
18
3
😡
19
4
💩
Domanda
Qual è il punteggio medio più basso in questo set di dati?
Il punteggio più basso di questo set di dati è 😿 13.
Valutazione della qualità con FastQC – letture corte e lunghe
Un metodo aggiuntivo o alternativo per verificare la qualità delle sequenze è FastQC. Questo strumento fornisce un insieme modulare di analisi che possono essere utilizzate per individuare eventuali problemi nei dati, di cui è bene essere consapevoli prima di procedere con ulteriori analisi. Possiamo usarlo, ad esempio, per verificare la presenza di adattatori noti nei dati. Lo eseguiremo sul file FASTQ.
Pratica: Controllo della qualità
Eseguite il FASTQC ( Galaxy version 0.73+galaxy0) con i seguenti parametri
param-files“Raw read data from your current history”: Reads
Ispezionare il file HTML generato.
Domanda
Quale codifica Phred è utilizzata nel file FASTQ per queste sequenze?
I punteggi Phred sono codificati secondo lo schema Sanger / Illumina 1.9 (Encoding tabella superiore del report).
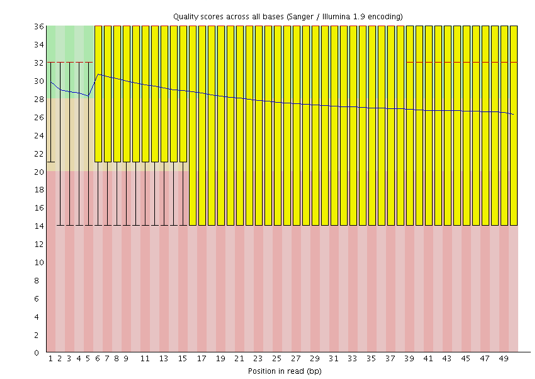
Qualità della sequenza per base
Con FastQC possiamo usare il grafico “Qualità della sequenza per base” per esaminare la qualità delle basi delle letture, in modo analogo a quanto fatto con FASTQE.
Sull’asse delle ascisse (x) sono indicate le posizioni delle basi all’interno della lettura. In questo esempio, il campione contiene letture lunghe fino a 296 bp.
L’asse x non è sempre uniforme. Quando si hanno letture lunghe, viene applicato un certo binning per mantenere il grafico compatto. Lo possiamo osservare anche nel nostro campione: inizia con basi singole da 1 a 10, poi le basi vengono raggruppate in finestre di ampiezza crescente. Il binning dei dati è una tecnica di pre-elaborazione che serve a ridurre gli effetti di piccoli errori di osservazione. Il numero di posizioni raggruppate dipende dalla lunghezza della lettura: Il numero di posizioni di base raggruppate dipende dalla lunghezza della lettura. Nel caso di letture >50bp, l’ultima parte del grafico riporterà le statistiche aggregate per finestre di 5bp. Le letture più corte avranno finestre più piccole e quelle più lunghe più grandi. Il binning può essere rimosso durante l’esecuzione di FastQC impostando il parametro “Disable grouping of bases for reads >50bp” su Yes.
Per ogni posizione viene disegnato un boxplot che mostra:
la mediana (linea rossa centrale)
l’intervallo interquartile (25–75%), rappresentato dal riquadro giallo
i valori del 10° e 90° percentile, nei baffi superiore e inferiore
la qualità media, rappresentata dalla linea blu
L’asse delle ordinate (y) mostra i punteggi di qualità Phred: più alto è il punteggio, più affidabile è la chiamata della base. Lo sfondo del grafico suddivide l’asse y in tre zone: qualità molto buoni (verde), punteggi di qualità accettabile (arancione) e letture di qualità scadente (rosso).
È normale, con tutti i sequenziatori Illumina, che il punteggio mediano inizi più basso nelle prime 5–7 basi e poi aumenti.
La qualità tende invece a diminuire verso la fine della lettura, spesso a causa del decadimento del segnale o dello sfasamento durante la corsa di sequenziamento. I recenti sviluppi della chimica di sequenziamento hanno migliorato parzialmente questo fenomeno, ma oggi le letture sono anche molto più lunghe.
Decadimento del segnale
L’intensità del segnale fluorescente diminuisce a ogni ciclo di sequenziamento.
A causa della degradazione dei fluorofori, una parte dei filamenti nel cluster non viene più allungata.
La frazione di segnale emesso continua quindi a ridursi ciclo dopo ciclo, determinando un calo dei punteggi di qualità all’estremità 3’ della lettura.
Sfasamento
Il segnale inizia a confondersi man mano che aumentano i cicli, poiché il cluster perde sincronia.
Alcuni filamenti subiscono errori casuali di incorporazione dei nucleotidi dovuti a:
rimozione incompleta dei terminatori e dei fluorofori in 3’
Incorporazione di nucleotidi privi di terminatori efficaci in 3’’
Entrambi i fenomeni portano a una riduzione della qualità all’estremità 3’ della lettura.
Questi sono alcuni profili di qualità per base che possono indicare problemi di sequenziamento.
Sovra-raggruppamento
LIn alcuni casi, le strutture di sequenziamento possono sovraccaricare la cella di flusso, causando distanze ridotte tra i cluster e sovrapposizione dei segnali. Due cluster possono quindi essere interpretati come uno solo, con segnali fluorescenti misti che riducono la purezza del segnale.
Questo genera punteggi di qualità inferiori per l’intera lettura.
Guasti strumentali
Possono verificarsi problemi tecnici durante una corsa di sequenziamento.
Un calo improvviso della qualità o una percentuale elevata di letture a bassa qualità lungo tutta la sequenza possono indicare un problema di strumentazione. Alcuni esempi:
Rottura del collettore (Manifold burst)
Perdita di cicli (Cycle loss)
Errore della lettura 2 (Read 2 failure)
CIn questi casi è consigliabile contattare il centro di sequenziamento per discuterne. Spesso è necessario un nuovo sequenziamento, che in genere viene offerto dalla struttura stessa.
Domanda
Come cambia il punteggio medio di qualità lungo la sequenza?
Questa tendenza si osserva in tutte le sequenze?
Il punteggio medio di qualità (linea blu) diminuisce circa a metà di queste sequenze. È normale che la qualità media cali verso la fine delle letture, poiché i sequenziatori incorporano più nucleotidi errati negli ultimi cicli. Tuttavia, in questo campione si osserva un calo di qualità molto marcato dalla metà in poi.
I boxplot si allargano a partire dalla posizione ~100, indicando che molte sequenze mostrano un calo di punteggio a partire da metà lettura. Dopo 100 nucleotidi, oltre il 10% delle sequenze presenta un punteggio inferiore a 20.
Quando la qualità mediana scende sotto un punteggio Phred di circa 20, è opportuno considerare il taglio delle basi di bassa qualità dalla sequenza. Questo processo verrà illustrato nella sezione Trim e filtro.
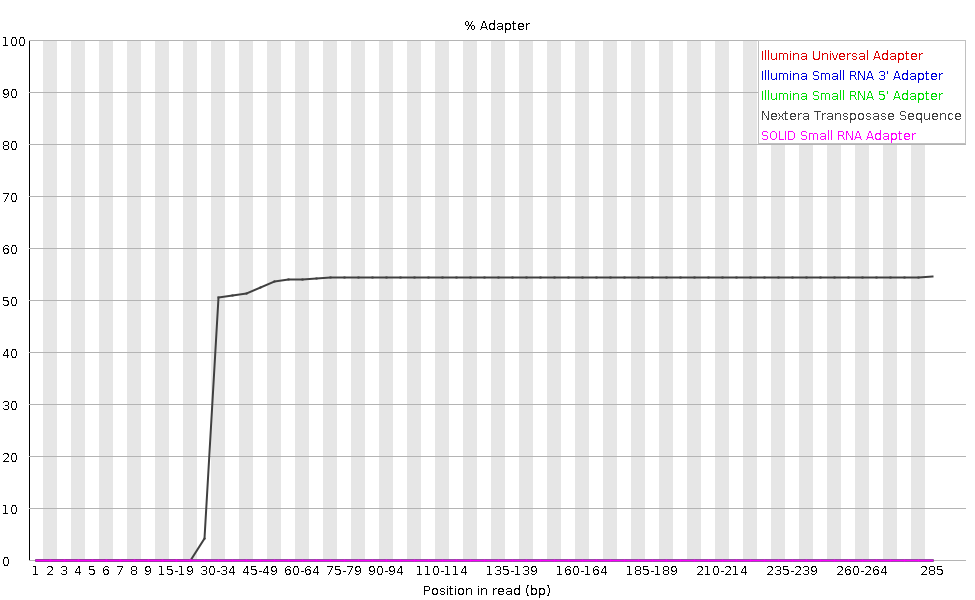
l grafico mostra la percentuale cumulativa di letture che contengono diverse sequenze adattatrici in ciascuna posizione.
Una volta che una sequenza di adattatore viene rilevata in una lettura, viene conteggiata come presente fino alla fine, quindi la percentuale aumenta con la lunghezza della lettura. FastQC rileva automaticamente diversi adattatori comuni (ad esempio Illumina, Nextera), ma è anche possibile fornire un file di contaminanti personalizzato come input allo strumento.
Idealmente, i dati di sequenziamento Illumina non dovrebbero contenere adattatori. Tuttavia, nelle letture lunghe, alcuni inserti della libreria possono essere più corti della lunghezza della lettura, facendo sì che l’adattatore venga letto all’estremità 3’.
Nel nostro campione di microbioma, FastQC rileva la presenza dell’adattatore Nextera.
Il contenuto di adattatori può comparire anche nelle librerie RNA-Seq, dove la distribuzione delle dimensioni degli inserti è varia e include spesso inserti corti.
Per rimuovere l’adattatore, è possibile utilizzare uno strumento di trimming come Cutadapt. Il processo viene illustrato nella sezione Filtro e trim
Le sezioni seguenti descrivono nel dettaglio alcuni degli altri grafici generati da FastQC. Alcuni moduli possono dare avvertimenti che sono normali per il tipo di dati con cui si sta lavorando, come discusso sotto e nelle FAQ di FASTQC. Gli altri grafici forniscono informazioni utili per comprendere più a fondo la qualità dei dati e per valutare possibili miglioramenti di laboratorio in futuro. Queste sezioni sono opzionali e vuoi saltarle, puoi
Passate direttamente alla sezione successiva per imparare a ritagliare dati paired-end.
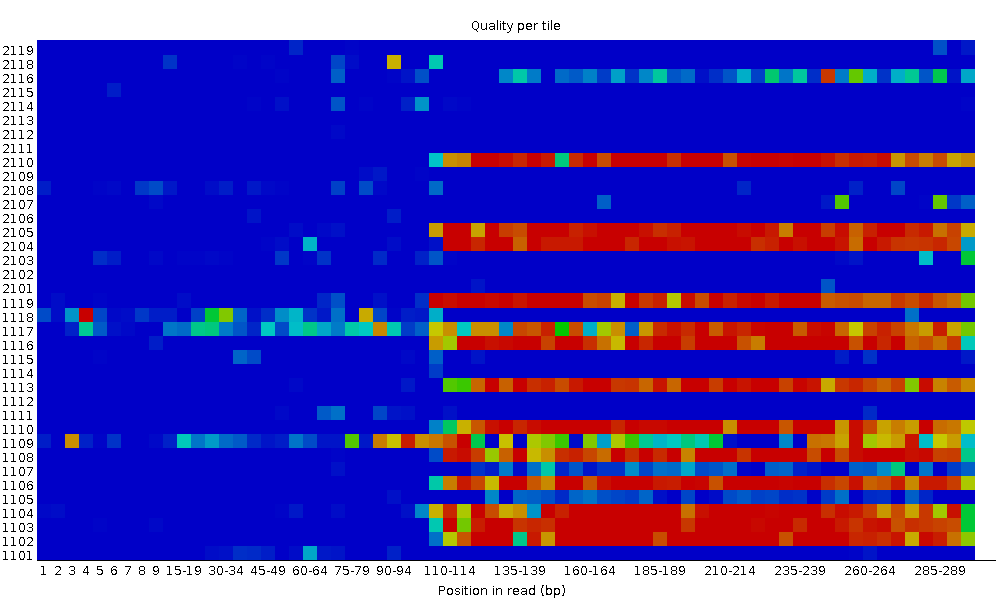
Qualità della sequenza per piastrella (tile)
Questo grafico consente di esaminare i punteggi di qualità di ciascuna piastrella della flow cell su tutte le basi per vedere se c’è stata una perdita di qualità associata a una singola area della flow cell. Mostra la deviazione dalla qualità media per ogni piastrella; i colori più caldi indicano qualità peggiore rispetto alle altre piastrelle nella stessa posizione. In questo campione, alcune piastrelle mostrano qualità costantemente bassa, soprattutto da ~100 bp in poi. Un buon grafico dovrebbe essere tutto blu.
Questo grafico appare solo per librerie Illumina che preservano gli identificatori originali nelle intestazioni delle letture (che codificano la piastrella di provenienza).
A volte le sostanze chimiche usate durante il sequenziamento si esauriscono col tempo e le ultime piastrelle ricevono reagenti meno performanti, rendendo la reazione più soggetta a errori. Il grafico può presentare linee orizzontali come in questo esempio:
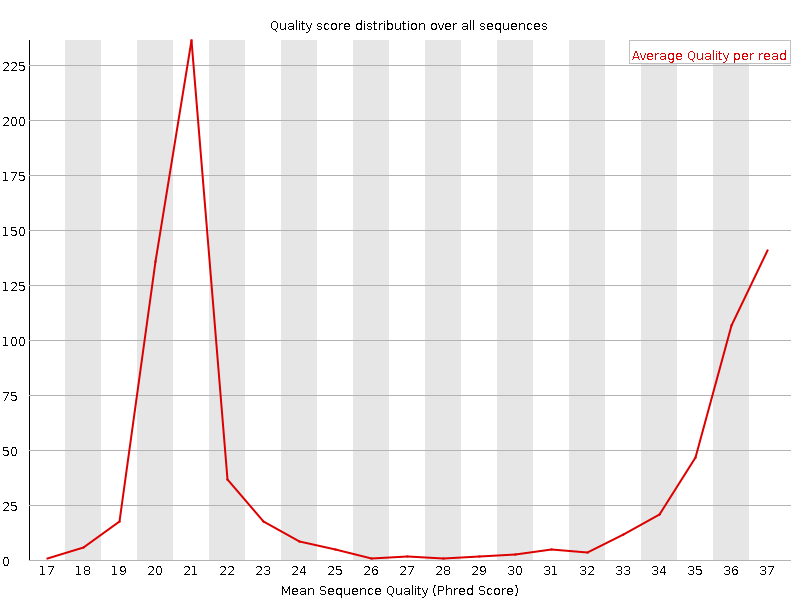
Punteggi di qualità per sequenza
Questo grafico riporta, sull’asse x, la qualità media su tutta la lunghezza delle singole letture e, sull’asse y, il numero totale di letture con quel punteggio:
La distribuzione dovrebbe avere un picco stretto nell’intervallo alto. Può inoltre evidenziare un sottoinsieme di letture con qualità universalmente bassa (ad esempio letture ai margini del campo visivo), che comunque dovrebbe rappresentare solo una piccola percentuale del totale.
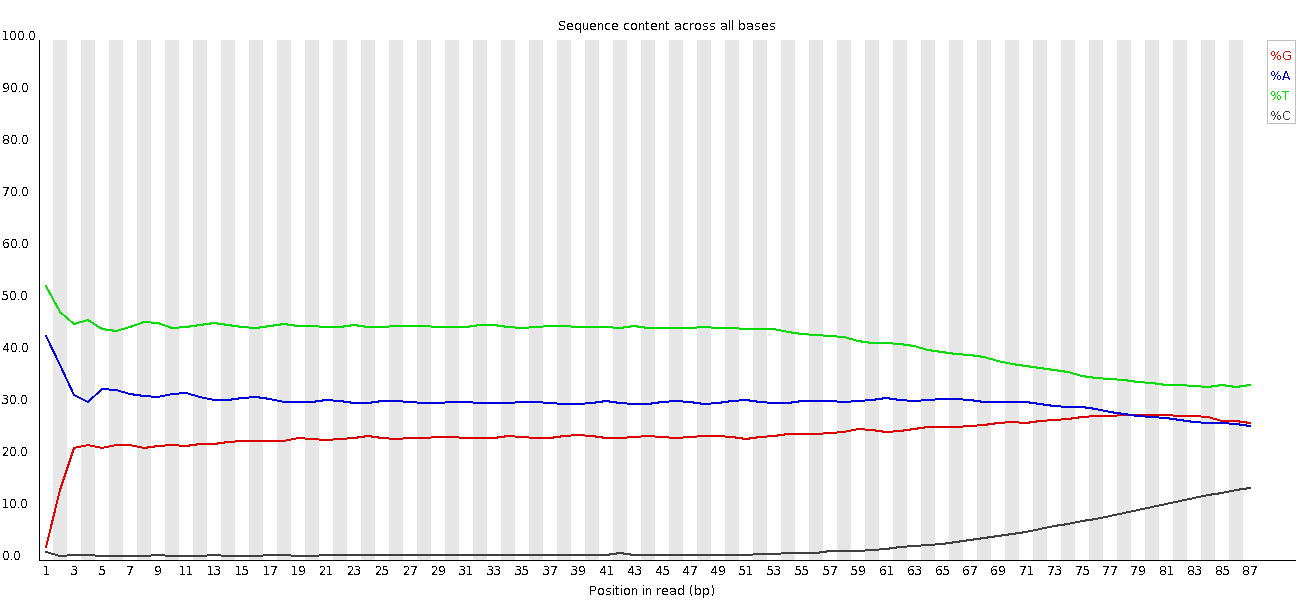
Figura 6: Contenuto di sequenza per base per una libreria di DNA
Il modulo “Per Base Sequence Content” traccia la percentuale dei quattro nucleotidi (A, C, G, T) in ciascuna posizione lungo tutte le letture del file in input. Come per la qualità per base, l’asse x può essere non uniforme (binning).
In una libreria casuale ci si aspetterebbe una differenza minima o nulla tra le quattro basi. La proporzione di ciascuna delle quattro basi dovrebbe rimanere relativamente costante per tutta la lunghezza della lettura con %A=%T e %G=%C, e le linee in questo grafico dovrebbero essere parallele tra loro. Si tratta di dati di ampliconi, in cui il DNA 16S viene amplificato con la PCR e sequenziato, quindi ci aspettiamo che questo grafico abbia qualche distorsione e non mostri una distribuzione casuale.
lcuni tipi di librerie presentano bias di composizione all’inizio della lettura. Le librerie prodotte mediante priming con esameri casuali (comprese quasi tutte le librerie RNA-Seq) e quelle frammentate mediante trasposasi conterranno un bias intrinseco nelle posizioni di inizio delle letture (le prime 10-12 basi). Questo bias non coinvolge una sequenza specifica, ma fornisce invece un arricchimento di un certo numero di K-mers diversi all’estremità 5’ delle letture. Pur trattandosi di un vero e proprio bias tecnico, non è qualcosa che può essere corretto con il trimming e nella maggior parte dei casi non sembra influire negativamente sull’analisi a valle. Tuttavia, produrrà un avviso o un errore in questo modulo.
Anche i dati ChIP-seq possono presentare distorsioni della sequenza di inizio lettura in questo grafico se frammentati con trasposasi. Con i dati convertiti in bisolfito, ad esempio i dati HiC, ci si aspetta una separazione di G da C e A da T:
Alla fine, si nota uno spostamento complessivo nella composizione della sequenza. Se lo spostamento è correlato a una perdita di qualità del sequenziamento, si può sospettare che le miscele siano fatte con un bias di sequenza più uniforme rispetto alle librerie convertite con bisolfito. Il ritaglio delle sequenze ha risolto il problema, ma se non fosse stato fatto avrebbe avuto un effetto drammatico sulle chiamate di metilazione effettuate.
Domanda
Perché c’è un’avvertenza per i grafici del contenuto di sequenza per base?
All’inizio delle sequenze, il contenuto di sequenza per base non è molto buono e le percentuali non sono uguali, come ci si aspetta per i dati degli ampliconi 16S.
Questo grafico mostra il numero di letture rispetto alla percentuale GC per lettura. È confrontato con una distribuzione teorica che presuppone uniformità GC per tutte le letture (scenario tipico WGS). Poiché il GC del genoma non è noto, il contenuto GC modale viene stimato dai dati e usato per costruire una distribuzione di riferimento.
Distribuzioni di forma insolita possono indicare contaminazione o sottoinsiemi distorti. Una distribuzione normale ma spostata indica un bias sistematico indipendente dalla posizione. Se è presente un bias sistematico, il modulo potrebbe non segnalarlo come errore (non conosce il GC “vero” del campione).
Ma ci sono anche altre situazioni in cui può verificarsi una distribuzione di forma insolita. Ad esempio, nel caso del sequenziamento dell’RNA può verificarsi una maggiore o minore distribuzione del contenuto medio di GC tra i trascritti, che fa sì che il grafico osservato sia più ampio o più stretto di una distribuzione normale ideale.
Domanda
Perché i grafici del contenuto GC per sequenza risultano “fail”?
CSono presenti più picchi. Questo può indicare contaminazione inattesa (adattatori, rRNA, sequenze sovrarappresentate) oppure essere normale per ampliconi o trascritti RNA-Seq molto abbondanti.
Distribuzione della lunghezza delle sequenze
Questo grafico mostra la distribuzione delle dimensioni dei frammenti nel file analizzato. In molti casi si otterrà un semplice grafico che mostra un picco di una sola dimensione, ma per i file FASTQ di lunghezza variabile mostrerà le quantità relative di ogni frammento di sequenza di dimensioni diverse. Il nostro grafico mostra una lunghezza variabile mentre tagliamo i dati. Il picco più grande è a 296 bp, ma c’è un secondo grande picco a ~100 bp. Quindi, anche se le nostre sequenze hanno una lunghezza massima di 296 bp, molte sequenze di buona qualità sono più corte. Ciò corrisponde al calo della qualità delle sequenze a ~100 bp e alle strisce rosse che iniziano in questa posizione nel grafico della qualità delle sequenze per tile.
Figura 8: Distribuzione della lunghezza di sequenza
Alcuni sequenziatori ad alta produttività generano frammenti di sequenza di lunghezza uniforme, ma altri possono contenere letture di lunghezza molto variabile. Anche all’interno di librerie di lunghezza uniforme, alcune pipeline tagliano le sequenze per rimuovere le chiamate di base di scarsa qualità dalla fine o dalle prime \(n$ basi se corrispondono alle prime\)n$ basi dell’adattatore fino al 90% (per impostazione predefinita), con talvolta \(n = 1\).
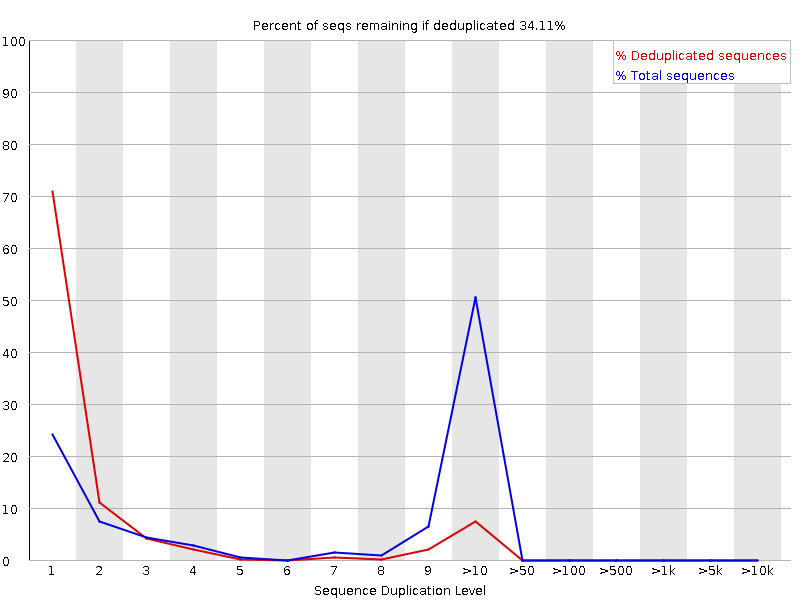
Livelli di duplicazione delle sequenze
Il grafico mostra in blu la percentuale di letture di una determinata sequenza nel file che sono presenti un determinato numero di volte nel file:
In una libreria eterogenea, la maggior parte delle sequenze si presenta una sola volta nell’insieme finale. Un basso livello di duplicazione può indicare un livello molto alto di copertura della sequenza target, ma un alto livello di duplicazione è più probabile che indichi un qualche tipo di bias di arricchimento.
Si possono trovare due fonti di letture duplicate:
Duplicazione PCR in cui i frammenti della libreria sono stati sovrarappresentati a causa di un arricchimento PCR distorto
È un problema perché i duplicati della PCR rappresentano male la vera proporzione di sequenze in ingresso.
Sequenze veramente sovrarappresentate, come trascritti molto abbondanti in una libreria RNA-Seq o in dati di ampliconi (come questo campione). È un caso atteso e non preoccupante perché rappresenta fedelmente l’input.
FastQC conta il grado di duplicazione per ogni sequenza in una libreria e crea un grafico che mostra il numero relativo di sequenze con diversi gradi di duplicazione. Il grafico presenta due linee:
Linea blu: distribuzione dei livelli di duplicazione per l’intero set di sequenze
Linea rossa: distribuzione delle sequenze de-duplicate con le proporzioni del set deduplicato che provengono da diversi livelli di duplicazione nei dati originali.
Per i dati shotgun dell’intero genoma si prevede che quasi il 100% delle letture sia unico (appare solo una volta nei dati di sequenza). La maggior parte delle sequenze dovrebbe cadere all’estrema sinistra del grafico, sia nella linea rossa che in quella blu. Ciò indica una libreria altamente diversificata che non è stata sovra-sequenziata. Se la profondità di sequenziamento è estremamente elevata (ad esempio > 100 volte la dimensione del genoma) possono comparire alcune inevitabili duplicazioni di sequenze: in teoria esiste solo un numero finito di letture di sequenza completamente uniche che possono essere ottenute da un dato campione di DNA in ingresso.
Arricchimenti più specifici di sottoinsiemi o la presenza di contaminanti a bassa complessità tenderanno a produrre picchi verso la destra del grafico. Questi picchi di duplicazione elevati appaiono spesso nella traccia blu, poiché costituiscono un’alta percentuale della libreria originale, ma di solito scompaiono nella traccia rossa, poiché costituiscono una percentuale insignificante dell’insieme deduplicato. Se i picchi persistono nella traccia rossa, ciò suggerisce la presenza di un gran numero di sequenze diverse altamente duplicate, che potrebbero indicare un set contaminante o una duplicazione tecnica molto grave.
Di solito nel sequenziamento dell’RNA ci sono trascritti molto abbondanti e altri poco abbondanti. Si prevede che per i trascritti ad alta abbondanza si osservino letture duplicate:
Sequenze sovrarappresentate
Una normale libreria high-throughput conterrà un insieme eterogeneo di sequenze, senza che nessuna singola sequenza costituisca una frazione minima dell’insieme. Se si scopre che una singola sequenza è molto sovrarappresentata nell’insieme, significa che è altamente significativa dal punto di vista biologico oppure che la libreria è contaminata o non è così diversificata come ci si aspetta.
FastQC elenca tutte le sequenze che costituiscono più dello 0,1% del totale. Per ogni sequenza sovrarappresentata, FastQC cercherà corrispondenze in un database di contaminanti comuni e riporterà il miglior risultato trovato. Gli hit devono avere una lunghezza minima di 20 bp e non avere più di 1 mismatch. Trovare un riscontro non significa necessariamente che sia la fonte della contaminazione, ma può indicare la direzione giusta. Vale anche la pena di sottolineare che molte sequenze di adattatori sono molto simili tra loro, quindi è possibile che venga segnalato un risultato non tecnicamente corretto, ma con una sequenza molto simile alla corrispondenza effettiva.
I dati di sequenziamento dell’RNA possono avere alcuni trascritti così abbondanti da essere registrati come sequenze sovrarappresentate. Con i dati di sequenziamento del DNA, nessuna singola sequenza dovrebbe essere presente con una frequenza sufficientemente alta da essere elencata, ma a volte possiamo vedere una piccola percentuale di letture di adattamento.
Domanda
Come possiamo scoprire quali sono le sequenze sovrarappresentate?
Possiamo eseguire BLAST sulle sequenze sovrarappresentate per vedere quali sono. In questo caso, se prendiamo la sequenza top overrepresented
e usiamo blastn contro il database predefinito dei nucleotidi (nr/nt) non otteniamo alcun risultato. Ma se usiamo VecScreen vediamo che si tratta dell’adattatore Nextera. Open image in new tab
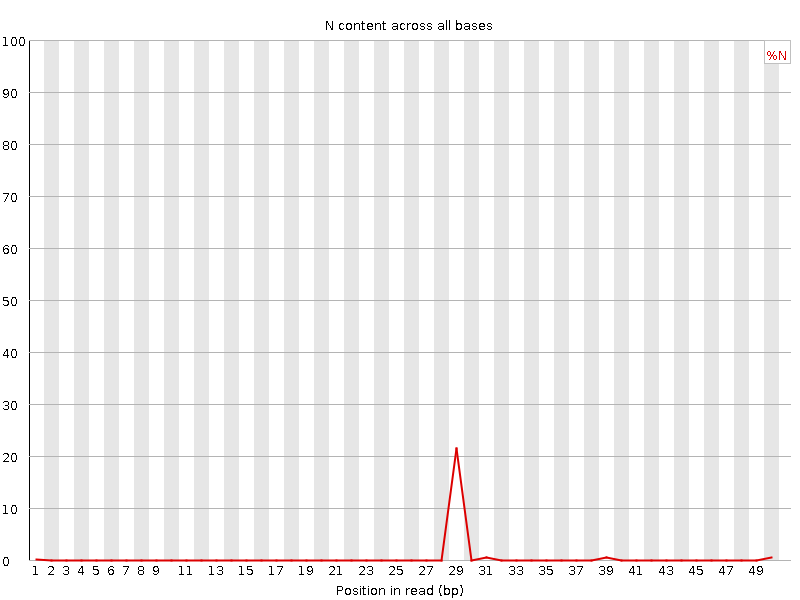
Se un sequenziatore non è in grado di effettuare una chiamata di base con sufficiente sicurezza, scriverà un “N” invece di una chiamata di base convenzionale. Questo grafico mostra la percentuale di chiamate di base in ogni posizione o bin per cui è stato chiamato un N.
Non è insolito vedere una percentuale molto alta di N che compaiono in una sequenza, soprattutto verso la fine della sequenza. Ma questa curva non dovrebbe mai salire sensibilmente sopra lo zero. Se ciò accade, significa che si è verificato un problema durante il sequenziamento. Nell’esempio seguente, un errore ha fatto sì che lo strumento non sia stato in grado di chiamare una base per circa il 20% delle letture in posizione 29:
Contenuto Kmer
Questo grafico non viene emesso per impostazione predefinita. Come indicato nel modulo dello strumento, se si desidera questo modulo è necessario abilitarlo utilizzando un sottomodulo personalizzato e un file di limiti. Con questo modulo, FastQC esegue un’analisi generica di tutte le sequenze nucleotidiche brevi di lunghezza k (kmer, con k = 7 per impostazione predefinita) a partire da ogni posizione lungo la lettura nella libreria per trovare quelle che non hanno una copertura uniforme per tutta la lunghezza delle letture. Ogni kmer deve essere rappresentato in modo uniforme lungo tutta la lunghezza della lettura.
FastQC riporterà l’elenco dei kmer che compaiono in posizioni specifiche con una frequenza maggiore del previsto. Ciò può essere dovuto a diverse fonti di bias nella libreria, tra cui la presenza di sequenze adattatore di lettura che si accumulano alla fine delle sequenze. La presenza di sequenze sovrarappresentate nella libreria (come i dimeri dell’adattatore) fa sì che il grafico dei kmer sia dominato dai kmer di queste sequenze. Eventuali kmer parziali dovuti ad altri bias interessanti possono essere quindi diluiti e non facilmente visibili.
L’esempio seguente proviene da una libreria DNA-Seq di alta qualità. I kmer distorti all’inizio della lettura sono probabilmente dovuti a un’efficienza di taglio del DNA leggermente dipendente dalla sequenza o al risultato di un priming casuale:
Questo modulo può essere molto difficile da interpretare. Il grafico del contenuto di adattatori e la tabella delle sequenze sovrarappresentate sono più facili da interpretare e possono fornire informazioni sufficienti senza bisogno di questo grafico. Le librerie RNA-seq possono avere kmer altamente rappresentati che derivano da sequenze altamente espresse. Per saperne di più su questo grafico, consultare la FastQC Kmer Content documentation.
Abbiamo cercato di spiegare qui i diversi rapporti di FastQC e alcuni casi d’uso. Ulteriori informazioni su questo argomento e su alcuni problemi comuni di sequenziamento di nuova generazione sono disponibili su QCFAIL.com
Small/micro RNA
Nelle librerie di small RNA, in genere abbiamo un insieme relativamente piccolo di sequenze uniche e brevi. Le librerie di small RNA non vengono frammentate in modo casuale prima di aggiungere gli adattatori di sequenziamento alle estremità: di conseguenza, tutte le letture appartenenti a classi specifiche di microRNA risultano identiche. Il risultato sarà:
Contenuto di sequenza per base estremamente distorto
Distribuzione estremamente stretta del contenuto di GC
Livelli molto elevati di duplicazione della sequenza
Abbondanza di sequenze sovrarappresentate
Lettura negli adattatori
Amplicon
Le librerie di ampliconi sono preparate mediante amplificazione PCR di un bersaglio specifico. Ad esempio, la regione ipervariabile V4 del gene 16S rRNA batterico. Ci si aspetta che tutte le letture di questo tipo di libreria siano quasi identiche. Il risultato sarà:
Contenuto di sequenza per base estremamente distorto
Distribuzione estremamente stretta del contenuto di GC
Livelli molto elevati di duplicazione della sequenza
Abbondanza di sequenze sovrarappresentate
Sequenziamento con bisolfito o metilazione
Con il sequenziamento con bisolfito o metilazione, la maggior parte delle basi di citosina (C) viene convertita in timina (T). Il risultato sarà:
Contenuto di sequenza per base distorto
Contenuto di GC per sequenza distorto
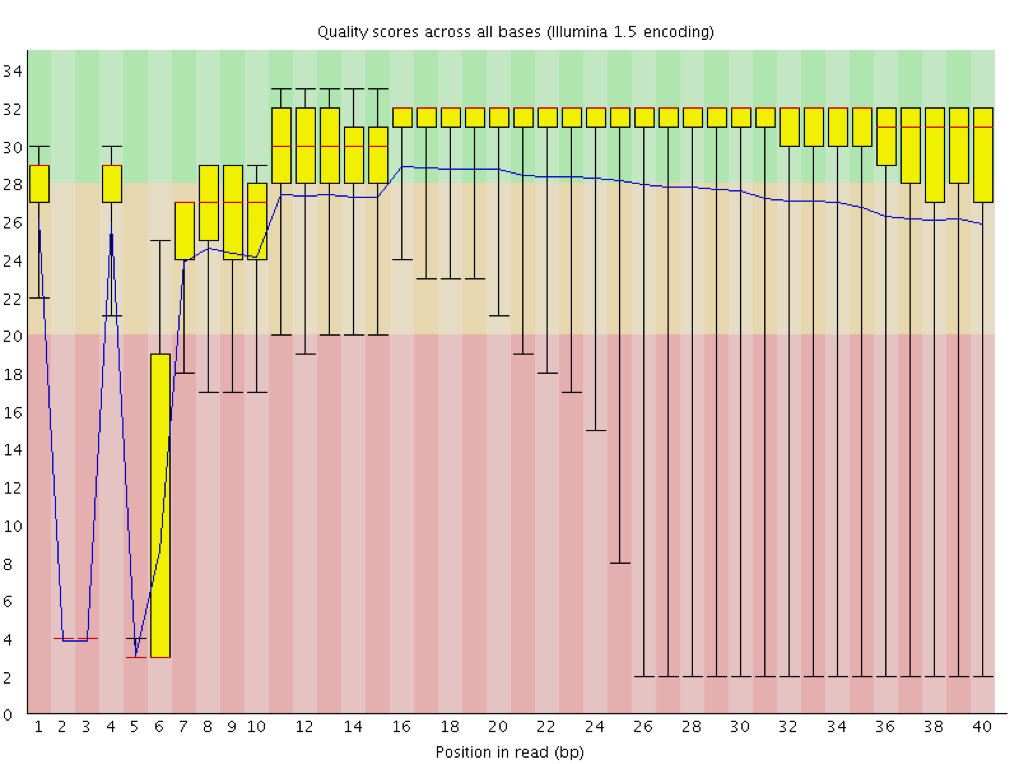
Contaminazione del dimero adattatore
Qualsiasi tipo di libreria può contenere una piccolissima percentuale di frammenti dimer adattatore (cioè senza inserto). È più probabile che si trovino nelle librerie di ampliconi costruite interamente con la PCR (per la formazione di primer-dimeri PCR) che nelle librerie DNA-Seq o RNA-Seq costruite con la legatura dell’adattatore. Se una frazione sufficiente della libreria è costituita da dimeri di adattatori, ciò si noterà nel rapporto FastQC:
Calo della qualità della sequenza per base dopo la base 60
Possibile distribuzione bimodale dei punteggi di qualità per sequenza
Modello distinto osservato nel contenuto di sequenza per basi fino alla base 60
Picco nel contenuto di GC per sequenza
Adattatore di corrispondenza delle sequenze sovrarappresentato
Contenuto di adattatori > 0% a partire dalla base 1
Commento: Sequenze di cattiva qualità
Se la qualità delle letture non è buona, dovremmo sempre verificare prima cosa c’è che non va e pensarci: potrebbe derivare dal tipo di sequenziamento o da ciò che abbiamo sequenziato (un’alta quantità di sequenze sovrarappresentate nei dati di trascrittomica, una percentuale distorta di basi nei dati HiC).
Potete anche chiedere informazioni al centro di sequenziamento, soprattutto se la qualità è davvero scadente: i trattamenti di qualità non possono risolvere tutto. Se vengono tagliate troppe basi di cattiva qualità, le letture corrispondenti vengono filtrate e si perdono.
Trim e filtro - letture corte
La qualità diminuisce al centro di queste sequenze. Ciò potrebbe causare distorsioni nelle analisi a valle con questi nucleotidi potenzialmente chiamati in modo errato. Le sequenze devono essere trattate per ridurre le distorsioni nelle analisi a valle. Il ritaglio può contribuire ad aumentare il numero di letture che l’allineatore o l’assemblatore sono in grado di utilizzare con successo, riducendo il numero di letture non mappate o non assemblate. In generale, i trattamenti di qualità includono:
Sequenze di ritaglio/taglio/mascheramento
da regioni a basso punteggio di qualità
inizio/fine sequenza
rimozione degli adattatori
Filtraggio delle sequenze
con punteggio di qualità medio basso
troppo corto
con troppe basi ambigue (N)
Per svolgere questo compito utilizzeremo CutadaptMarcel 2011, uno strumento che migliora la qualità della sequenza automatizzando il trimming degli adattatori e il controllo di qualità. Si tratta di:
Rifilatura delle basi di bassa qualità dalle estremità. Il trimming della qualità viene eseguito prima di qualsiasi trimming dell’adattatore. Impostiamo la soglia di qualità a 20, una soglia comunemente usata, per saperne di più nelle Phred Score FAQ di GATK.
Ritagliare l’adattatore con Cutadapt. Per questo è necessario fornire la sequenza dell’adattatore. In questo esempio, Nextera è l’adattatore rilevato. Possiamo trovare la sequenza dell’adattatore Nextera sul sito web IlluminaCTGTCTCTTATACACATCT. Taglieremo questa sequenza dall’estremità 3’ delle letture.
Filtrare le sequenze con lunghezza < 20 dopo il trimming
Pratica: Miglioramento della qualità della sequenza
Cutadapt ( Galaxy version 4.9+galaxy1) con i seguenti parametri
“Letture single-end o paired-end? “: ..Single-end..
param-file“File FASTQ/A “: Reads (set di dati di input)
Se il file FASTQ non può essere selezionato, si può controllare se il formato è FASTQ con valori di qualità scalati Sanger (fastqsanger.gz). È possibile modificare il tipo di dati facendo clic sul simbolo della matita.
In “Read 1 Adapters”:
“1: 3’ (End) Adapters”:
“Source”: Enter custom sequence
“Custom 3’ adapter sequence”: CTGTCTCTTATACACATCT
In “Other Read Trimming Options”
“Quality cutoff(s) (R1)”: 20
In “Read Filtering Options”
“Minimum length (R1)”: 20
param-select“Additional outputs to generate”: Report
Ispezionare il file txt generato (Report)
Domanda
Quale percentuale di letture contiene un adattatore?
Quale percentuale di letture è stata tagliata a causa della cattiva qualità?
Quale percentuale di letture è stata rimossa perché troppo corta?
il 56,8% delle letture contiene l’adattatore (Reads with adapters:)
il 35,1% delle letture è stato tagliato a causa della cattiva qualità (Quality-trimmed:)
lo 0 % delle letture è stato rimosso perché troppo corto
Uno dei maggiori vantaggi di Cutadapt rispetto ad altri strumenti di trimming (ad esempio TrimGalore!) è che dispone di una buona documentazione che spiega in dettaglio il funzionamento dello strumento.
L’algoritmo di taglio della qualità Cutadapt consiste in tre semplici passaggi:
Sottrarre il valore di soglia scelto dal valore di qualità di ogni posizione
Calcolo di una somma parziale di queste differenze dalla fine della sequenza a ogni posizione (finché la somma parziale è negativa)
Taglio al valore minimo della somma parziale
Nell’esempio seguente, supponiamo che l’estremità 3’ debba essere sottoposta a quality-trimming con una soglia di 10 e abbiamo i seguenti valori di qualità
42 40 26 27 8 7 11 4 2 3
sottrarre la soglia
32 30 16 17 -2 -3 1 -6 -8 -7
sommare i numeri, partendo dall’estremità 3’ (somme parziali) e fermarsi prima se la somma è maggiore di zero
(70) (38) 8 -8 -25 -23 -20, -21 -15 -7
I numeri tra parentesi non sono calcolati (perché 8 è maggiore di zero), ma vengono mostrati per completezza.
Scegliere la posizione del minimo (-25) come posizione di taglio
Pertanto, la lettura viene tagliata alle prime quattro basi, che presentano valori di qualità
42 40 26 27
Si noti quindi che le posizioni con un valore di qualità maggiore della soglia scelta vengono rimosse anche se sono incorporate in regioni di qualità inferiore (la somma parziale è decrescente se i valori di qualità sono minori della soglia). Il vantaggio di questa procedura è che è robusta contro un piccolo numero di posizioni con una qualità superiore alla soglia.
Le alternative a questa procedura sono:
Taglio dopo la prima posizione con qualità inferiore alla soglia
Approccio a finestra scorrevole
L’approccio a finestra scorrevole controlla che la qualità media di ogni finestra di sequenza di lunghezza specificata sia maggiore della soglia. Si noti che, a differenza dell’approccio di cutadapt, questo approccio ha un parametro in più e la robustezza dipende dalla lunghezza della finestra (in combinazione con la soglia di qualità). Entrambi gli approcci sono implementati in Trimmomatic.
Possiamo esaminare i nostri dati tagliati con FASTQE e/o FastQC.
Pratica: Controllo della qualità dopo il trimming
FASTQE ( Galaxy version 0.3.1+galaxy0): Eseguire nuovamente FASTQE con i seguenti parametri
param-files“FastQ data”: Cutadapt Read 1 Output
param-select“Score types to show”: Mean
Ispezionare il nuovo rapporto FASTQE
Domanda
Confrontate l’output FASTQE con quello precedente prima del trimming. La qualità della sequenza è migliorata?
Se si desidera visualizzare due o più insiemi di dati contemporaneamente, è possibile utilizzare la funzione Window Manager di Galaxy:
Cliccare sull’icona Gestore finestregalaxy-scratchbook nella barra dei menu superiore.
ora dovrebbe comparire un piccolo segno di spunta sull’icona
Visualizzagalaxy-eye un set di dati facendo clic sull’icona occhio galaxy-eye per visualizzare l’output
Si dovrebbe vedere l’output in una finestra sovrapposta a Galaxy
È possibile ridimensionare questa finestra trascinando l’angolo in basso a destra
Cliccare all’esterno del file per uscire dal gestore delle finestre
Visualizzagalaxy-eye un secondo set di dati dalla tua cronologia
Si dovrebbe ora vedere una seconda finestra con il nuovo set di dati
In questo modo è più facile confrontare i due output
Ripetere l’operazione per il numero di file che si desidera confrontare
È possibile disattivare il Gestore finestregalaxy-scratchbook facendo di nuovo clic sull’icona
Sì, le emoji del punteggio di qualità hanno un aspetto migliore (più felice) ora.
Con FastQC possiamo vedere che abbiamo migliorato la qualità delle basi nel dataset e rimosso l’adattatore.
Abbiamo alcune strisce rosse perché abbiamo tagliato quelle regioni dalle letture.
Ora abbiamo un picco di alta qualità invece di uno di alta e uno di bassa qualità che avevamo in precedenza.
Non abbiamo una rappresentazione uguale delle basi come prima, poiché si tratta di dati ampliconici.
Ora abbiamo un unico picco GC principale dovuto alla rimozione dell’adattatore.
Questo è lo stesso di prima in quanto non abbiamo N in queste letture.
Ora abbiamo più picchi e una gamma di lunghezze, invece del singolo picco che avevamo prima del trimming quando tutte le sequenze erano della stessa lunghezza.
Domanda
A cosa corrisponde la sequenza top sovrarappresentata GTGTCAGCCGCCGCGGTAGTCCGACGTGG?
Se prendiamo la sequenza top overrepresented
>overrep_seq1_after
GTGTCAGCCGCCGCGGTAGTCCGACGTGG
e usando blastn contro il database predefinito dei nucleotidi (nr/nt) vediamo che i risultati migliori riguardano i geni 16S rRNA. Ciò ha senso in quanto si tratta di dati di ampliconi 16S, in cui il gene 16S viene amplificato mediante PCR.
Elaborazione di set di dati multipli
Elaborazione dei dati paired-end
Con il sequenziamento paired-end, i frammenti vengono sequenziati da entrambi i lati. Questo approccio dà luogo a due letture per frammento, con la prima lettura in orientamento in avanti e la seconda in orientamento inverso-complementare. Con questa tecnica, abbiamo il vantaggio di ottenere più informazioni su ciascun frammento di DNA rispetto alle letture sequenziate solo con il sequenziamento single-end:
La distanza tra le due letture è nota e quindi è un’informazione aggiuntiva che può migliorare la mappatura delle letture.
Il sequenziamento Paired-end genera 2 file FASTQ:
Un file con le sequenze corrispondenti all’orientamento forward di tutti i frammenti
Un file con le sequenze corrispondenti all’orientamento reverse di tutti i frammenti
Di solito riconosciamo questi due file che appartengono a un campione dal nome che ha lo stesso identificatore per le letture ma un’estensione diversa, ad esempio sampleA_R1.fastq per le letture in avanti e sampleA_R2.fastq per le letture inverse. Può anche essere _f o _1 per le letture in avanti e _r o _2 per le letture inverse.
I dati analizzati nella fase precedente erano single-end, quindi importeremo un set di dati RNA-seq paired-end da utilizzare. Eseguiremo FastQC e aggregeremo i due rapporti con MultiQC Ewels et al. 2016.
Pratica: Valutazione della qualità delle letture paired-end
Importare le letture paired-end GSM461178_untreat_paired_subset_1.fastq e GSM461178_untreat_paired_subset_2.fastq da Zenodo o dalla libreria di dati (chiedere al proprio istruttore)
FASTQC ( Galaxy version 0.73+galaxy0) con entrambi i set di dati:
param-files“Dati di lettura grezzi dalla vostra storia attuale “: entrambi i set di dati caricati.
Fare clic su param-filesInsiemi di dati multipli
Selezionare diversi file tenendo premuto il tasto Ctrl (o COMMAND) e facendo clic sui file di interesse
MultiQC ( Galaxy version 1.9+galaxy1) con i seguenti parametri per aggregare i rapporti FastQC delle letture sia forward che reverse
In “Risultati “
“Quale strumento è stato usato per generare i log? “: FastQC
In “Output FastQC “
“Tipo di output FastQC? “: Raw data
param-files“Output FastQC “: file Raw data (output di entrambi i FastQCtool)
Esaminare la pagina web prodotta da MultiQC.
Domanda
Cosa ne pensate della qualità delle sequenze?
Cosa dobbiamo fare?
La qualità delle sequenze sembra peggiore per le letture reverse che per quelle forward:
Punteggi di qualità per sequenza: distribuzione più a sinistra, cioè qualità media delle sequenze più bassa
Qualità della sequenza per base: curva meno regolare e diminuzione più marcata alla fine con un valore medio inferiore al 28
Contenuto della sequenza per base: bias più forte all’inizio e nessuna distinzione chiara tra gruppi C-G e A-T
Gli altri indicatori (adattatori, livelli di duplicazione, ecc.) sono simili.
Dovremmo tagliare la fine delle sequenze e filtrarle con Cutadapttool
Con le letture paired-end i punteggi medi di qualità per le letture forward saranno quasi sempre più alti di quelli per le letture reverse.
Dopo il trimming, le letture inverse saranno più corte a causa della loro qualità e saranno quindi eliminate durante la fase di filtraggio. Se una delle letture inverse viene rimossa, deve essere rimossa anche la corrispondente lettura in avanti. Altrimenti si otterrà un numero diverso di letture in entrambi i file e in ordine diverso, e l’ordine è importante per le fasi successive. Pertanto è importante trattare le letture forward e reverse insieme per il trimming e il filtraggio.
Pratica: Migliorare la qualità dei dati paired-end
Cutadapt ( Galaxy version 4.9+galaxy1) con i seguenti parametri
“Letture single-end o paired-end? “: ..Paired-end..
param-file“File FASTQ/A #1”: GSM461178_untreat_paired_subset_1.fastq (set di dati in ingresso)
param-file“File FASTQ/A #2”: GSM461178_untreat_paired_subset_2.fastq (set di dati in ingresso)
L’ordine è importante!
In Read 1 Adapters or Read 2 Adapters
Non sono stati trovati adattatori in questi set di dati. Quando si elaborano i propri dati e si sa quali sequenze di adattatori sono state utilizzate durante la preparazione della libreria, è necessario fornire le loro sequenze qui.
In “Other Read Trimming Options”
“Quality cutoff(s) (R1)”: 20
In “Read Filtering Options”
“Minimum length (R1)”: 20
param-select“Additional outputs to generate”: Report
Ispezionare il file txt generato (Report)
Domanda
Quante coppie di basi sono state rimosse dalle letture a causa della cattiva qualità?
Quante coppie di sequenze sono state rimosse perché troppo corte?
44.164 bp (Quality-trimmed:) per le letture in avanti e 138.638 bp per le letture inverse.
1.376 sequenze sono state rimosse perché almeno una lettura era più corta del limite di lunghezza (322 quando sono state analizzate solo le letture in avanti).
Oltre al rapporto, Cutadapt genera 2 file:
Lettura 1 con le letture forward tagliate e filtrate
Lettura 2 con le letture reverse rifilate e filtrate
Questi set di dati possono essere utilizzati per l’analisi a valle, ad esempio la mappatura.
Domanda
Che tipo di allineamento si usa per trovare gli adattatori nelle letture?
Qual è il criterio per scegliere il miglior allineamento di adattatori?
Allineamento semi-globale, cioè solo la parte sovrapposta della lettura e della sequenza adattatore viene utilizzata per il punteggio.
Viene calcolato un allineamento con la massima sovrapposizione che presenta il minor numero di mismatch e indel.
Valutazione della qualità con Nanoplot - Solo letture lunghe
In caso di letture lunghe, possiamo controllare la qualità della sequenza con Nanoplot (De Coster et al. 2018). Fornisce statistiche di base con grafici gradevoli per una rapida panoramica del controllo di qualità.
Pratica: Controllo della qualità di letture lunghe
Creare una nuova cronologia per questa parte e darle un nome appropriato
Importazione delle letture PacBio HiFi m64011_190830_220126.Q20.subsample.fastq.gz da Zenodo
param-select“Specify the bivariate format of the plots.”: dot, kde
param-select“Show the N50 mark in the read length histogram.”: Yes
Ispezione del file HTML generato
Domanda
Qual è il Qscore medio?
Il Qscore si aggira intorno a Q32. Nel caso di PacBio CLR e Nanopore, è intorno a Q12 e vicino a Q31 per Illumina (NovaSeq 6000). Open image in new tab
<figcaption>Figura 16: Comparison of Qscore between Illumina, PacBio and Nanopore</figcaption>
Definizione: Qscores è la probabilità media di errore per base, espressa sulla scala log (Phred)
Qual è la mediana, la media e l’N50?
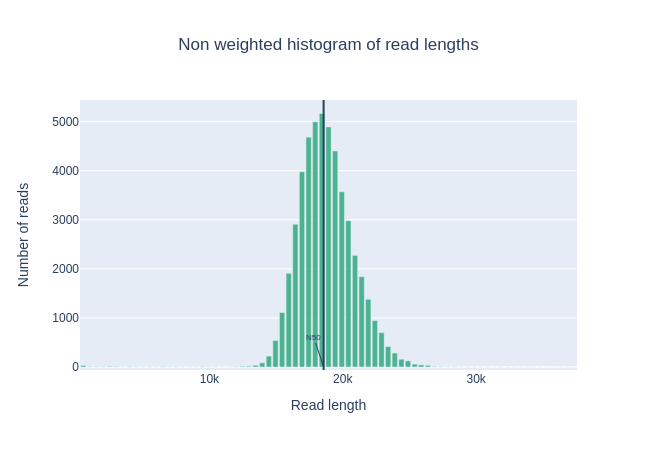
La mediana, la lunghezza media delle letture e anche la N50 sono vicine a 18.000 bp. Per le letture PacBio HiFi, la maggior parte delle letture è generalmente vicina a questo valore poiché la preparazione della libreria include una fase di selezione delle dimensioni. Per altre tecnologie come PacBio CLR e Nanopore, il valore è maggiore e dipende principalmente dalla qualità dell’estrazione del DNA.
Istogramma delle lunghezze delle letture
Questo grafico mostra la distribuzione delle dimensioni dei frammenti nel file analizzato. A differenza della maggior parte delle corse Illumina, le letture lunghe hanno una lunghezza variabile e questo mostra le quantità relative di ogni frammento di sequenza di dimensioni diverse. In questo esempio, la distribuzione della lunghezza delle letture è centrata vicino a 18kbp, ma i risultati possono essere molto diversi a seconda dell’esperimento.
Grafico della lunghezza delle letture rispetto alla qualità media delle letture utilizzando i punti
Questo grafico mostra la distribuzione delle dimensioni dei frammenti in base al Qscore del file analizzato. In generale, non esiste un legame tra la lunghezza delle letture e la loro qualità, ma questa rappresentazione consente di visualizzare entrambe le informazioni in un unico grafico e di individuare eventuali aberrazioni. Nelle corse con molte letture brevi, le letture più corte sono talvolta di qualità inferiore rispetto alle altre.
Esegui il controllo di qualità con FastQCtool su m64011_190830_220126.Q20.subsample.fastq.gz e confronta i risultati!
Valutazione della qualità con PycoQC - solo Nanopore
PycoQC (Leger and Leonardi 2019) è uno strumento di visualizzazione dei dati e di controllo della qualità per i dati nanopore. A differenza di FastQC/Nanoplot, necessita di uno specifico file sequencing_summary.txt generato dai basecaller per nanopori di Oxford, come Guppy o il vecchio basecaller albacore.
Uno dei punti di forza di PycoQC è che è interattivo e altamente personalizzabile, ad esempio, i grafici possono essere ritagliati, è possibile ingrandire e rimpicciolire, sotto-selezionare aree ed esportare figure.
Pratica: Controllo della qualità delle letture Nanopore
Creare una nuova cronologia per questa parte e darle un nome appropriato
Importazione delle letture nanopore nanopore_basecalled-guppy.fastq.gz e sequencing_summary.txt da Zenodo
~270k letture in totale (vedere la tabella di riepilogo Basecall, “Tutte le letture”) Per la maggior parte dei profili di basecalling, Guppy assegnerà le letture come “Pass” se il Qscore della lettura è almeno pari a 7.
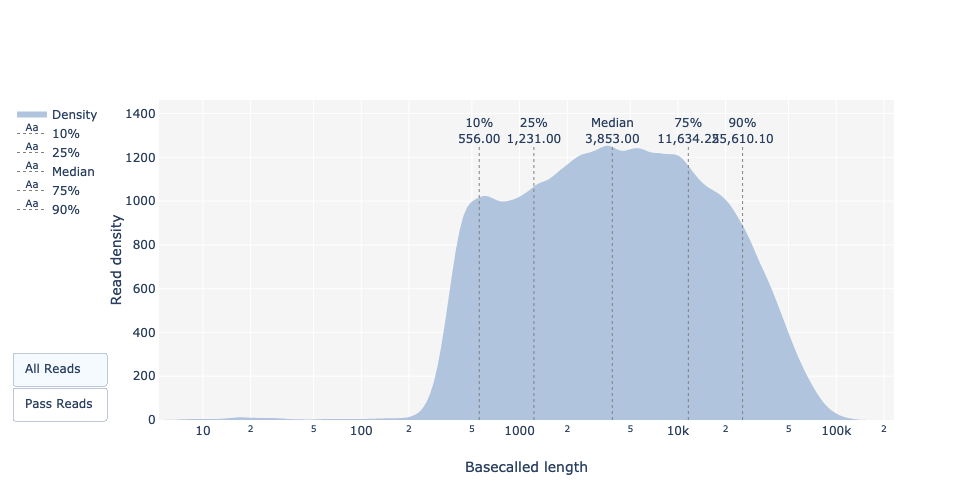
Qual è la lunghezza mediana, minima e massima delle letture, qual è l’N50?
La lunghezza mediana della lettura e l’N50 si possono trovare per tutte e per tutte le letture superate, cioè quelle che hanno superato le impostazioni di qualità di Guppy (Qscore >= 7), nella tabella riassuntiva della basecall.
Per le lunghezze minime (195bp) e massime (256kbp) delle letture, si può trovare con il grafico delle lunghezze delle letture.
Lunghezza delle letture di base
Come per FastQC e Nanoplot, questo grafico mostra la distribuzione delle dimensioni dei frammenti nel file analizzato. Come per PacBio CLR/HiFi, le letture lunghe hanno una lunghezza variabile e questo mostra le quantità relative di ogni frammento di sequenza di dimensioni diverse. In questo esempio, la distribuzione della lunghezza delle letture è piuttosto dispersa, con una lunghezza minima per le letture passate di circa 200 bp e una lunghezza massima di circa 150.000 bp.
Questo grafico mostra la distribuzione dei punteggi di qualità (Q) per ogni lettura. Questo punteggio mira a fornire un punteggio di qualità globale per ogni lettura. La definizione esatta di Qscores è: la probabilità media di errore per base, espressa sulla scala log (Phred). Nel caso dei dati Nanopore, la distribuzione è generalmente centrata intorno a 10 o 12. Per le vecchie corse, la distribuzione può essere più ampia. Per le vecchie corse, la distribuzione può essere più bassa, poiché i modelli di chiamata delle basi sono meno precisi dei modelli recenti.
Lunghezza delle letture chiamate in base vs qualità delle letture PHRED
Domanda
Come appaiono la qualità media e la distribuzione della qualità della corsa?
La maggior parte delle letture ha un Qscore compreso tra 8 e 11, che è standard per i dati Nanopore.
Attenzione: per gli stessi dati, il basecaller utilizzato (Albacor, Guppy, Bonito), il modello (fast, hac, sup) e la versione dello strumento possono dare risultati diversi.
Come per NanoPlot, questa rappresentazione fornisce una visualizzazione 2D del Qscore delle letture in base alla lunghezza.
Figura 22: Lunghezza delle letture richiamate vs qualità delle letture PHRED
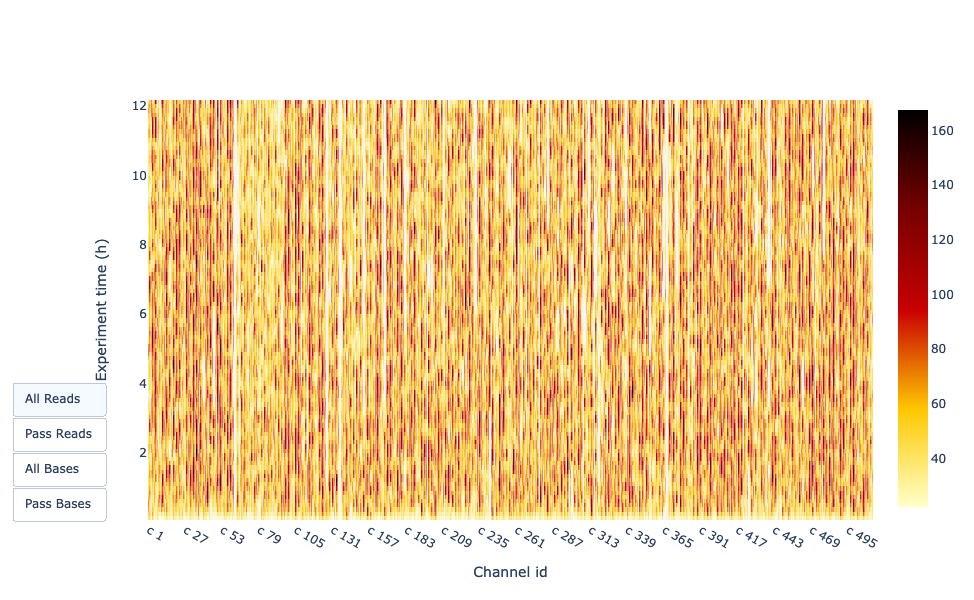
Output nel tempo dell’esperimento
Questa rappresentazione fornisce informazioni sulle letture sequenziate nel tempo per una singola corsa:
Ogni immagine indica un nuovo carico della cella a flusso (3 + il primo carico).
Il contributo in letture totali per ogni “rifornimento”.
La produzione di letture diminuisce nel tempo:
La maggior parte del materiale (DNA/RNA) viene sequenziato
Saturazione dei pori
Degradazione del materiale/dei pori
…
In questo esempio, il contributo di ogni rifornimento è molto basso e si può considerare una cattiva corsa. L’area del grafico “Cummulativo” (blu chiaro) indica che il 50% di tutte le letture e quasi il 50% di tutte le basi sono state prodotte nelle prime 5 ore dell’esperimento di 25 ore. Sebbene sia normale che la resa diminuisca nel tempo, una diminuzione di questo tipo non è un buon segno.
In questo esempio, la produzione di dati nel tempo è diminuita solo leggermente nel corso delle 12 ore, con un continuo aumento dei dati cumulativi. L’assenza di una curva decrescente alla fine della corsa indica che c’è ancora materiale biologico sulla cella a flusso. La corsa è terminata prima che tutto fosse sequenziato. Si tratta di una corsa eccellente, che può essere considerata addirittura eccezionale.
Lunghezza delle letture nel tempo dell’esperimento
Domanda
La lunghezza della lettura è cambiata nel tempo? Quale potrebbe essere il motivo?
Nell’esempio attuale la lunghezza della lettura aumenta nel corso della corsa di sequenziamento.
Una spiegazione è che la densità dell’adattatore è maggiore per molti frammenti corti e quindi la possibilità che un frammento più corto si attacchi a un poro è maggiore. Inoltre, le molecole più corte possono muoversi più velocemente sul chip.
Con il passare del tempo, tuttavia, i frammenti più corti diventano più rari e quindi più frammenti lunghi si attaccano ai pori e vengono sequenziati.
La lunghezza della lettura nel tempo dell’esperimento dovrebbe essere stabile. Può aumentare leggermente nel corso del tempo, poiché i frammenti corti tendono a essere sovra-sequenziati all’inizio e sono meno presenti nel corso del tempo.
Fornisce una panoramica dei pori disponibili, dell’utilizzo dei pori durante l’esperimento, dei pori inattivi e mostra se il carico della cella a flusso è buono (quasi tutti i pori sono utilizzati). In questo caso, la stragrande maggioranza dei canali/pori sono inattivi (bianchi) durante la corsa di sequenziamento, quindi la corsa può essere considerata negativa.
Si spera in un grafico che sia scuro vicino all’asse X e che con valori Y più alti (aumento del tempo) non diventi troppo chiaro/bianco. A seconda che si scelga “Reads” o “Bases” a sinistra, il colore indica il numero di basi o di letture per intervallo di tempo
In questo esempio, quasi tutti i pori sono attivi lungo tutta la corsa (profilo giallo/rosso), il che indica una corsa eccellente.
Commento: Prova!
Esegui il controllo di qualità con FastQCtool e/o Nanoplottool su nanopore_basecalled-guppy.fastq.gz e confronta i risultati!
Conclusione
In questa esercitazione abbiamo controllato la qualità dei file FASTQ per assicurarci che i loro dati siano buoni prima di dedurre ulteriori informazioni. Questa fase è il primo passo abituale per analisi come RNA-Seq, ChIP-Seq o qualsiasi altra analisi OMIC basata su dati NGS. Le fasi del controllo di qualità sono simili per qualsiasi tipo di dati di sequenziamento:
Valutazione della qualità con strumenti come:
Letture brevi: FASTQE ( Galaxy version 0.3.1+galaxy0)
Corto+Lungo: FASTQC ( Galaxy version 0.73+galaxy0)
Letture lunghe: Nanoplot ( Galaxy version 1.41.0+galaxy0)
Solo nanopore: PycoQC ( Galaxy version 2.5.2+galaxy0)
Taglio e filtraggio per letture corte con uno strumento come Cutadapttool
Hai completato il tutorial
Please also consider filling out the Feedback Form as well!
Punti chiave
Eseguire il controllo di qualità su ogni dataset prima di qualsiasi altra analisi bioinformatica
Valutare le metriche di qualità e migliorare la qualità se necessario
Verificare l’impatto del controllo di qualità
Sono disponibili diversi strumenti che forniscono metriche di qualità aggiuntive
Per paired‑end analizzare insieme le letture forward e reverse
Domande frequenti
Hai domande su questo tutorial? Dai un'occhiata alle FAQ disponibili e ai canali di supporto
Further information, including links to documentation and original publications, regarding the tools, analysis techniques and the interpretation of results described in this tutorial can be found here.
Ewels, P., M. Magnusson, S. Lundin, and M. K\~ A\textcurrencyller, 2016 MultiQC: summarize analysis results for multiple tools and samples in a single report. Bioinformatics 32: 3047–3048. 10.1093/bioinformatics/btw354
De Coster, W., S. D’Hert, D. T. Schultz, M. Cruts, and C. Van Broeckhoven, 2018 NanoPack: visualizing and processing long-read sequencing data. Bioinformatics 34: 2666–2669. 10.1093/bioinformatics/bty149
Leger, A., and T. Leonardi, 2019 pycoQC, interactive quality control for Oxford Nanopore Sequencing . Journal of Open Source Software 4: 1236. 10.21105/joss.01236
Jacques, R. M. S., W. M. Maza, S. D. Robertson, A. Lonsdale, C. S. Murray et al., 2021 A Fun Introductory Command Line Lesson: Next Generation Sequencing Quality Analysis with Emoji! CourseSource 8: 10.24918/cs.2021.17
Feedback
Hai usato questo materiale come istruttore? Sentiti libero di lasciarci un feedback. Com'è andata.
Hai usato questo materiale come studente? Clicca sul modulo qui sotto per lasciare un feedback.
Hiltemann, Saskia, Rasche, Helena et al., 2023 Galaxy Training: A Powerful Framework for Teaching! PLOS Computational Biology 10.1371/journal.pcbi.1010752
Batut et al., 2018 Community-Driven Data Analysis Training for Biology Cell Systems 10.1016/j.cels.2018.05.012
@misc{sequence-analysis-quality-control,
author = "Bérénice Batut and Maria Doyle and Alexandre Cormier and Anthony Bretaudeau and Laura Leroi and Erwan Corre and Stéphanie Robin and Cameron Hyde",
title = "Controllo qualità (Galaxy Training Materials)",
year = "",
month = "",
day = "",
url = "\url{https://training.galaxyproject.org/training-material/topics/sequence-analysis/tutorials/quality-control/tutorial_IT.html}",
note = "[Online; accessed TODAY]"
}
@article{Hiltemann_2023,
doi = {10.1371/journal.pcbi.1010752},
url = {https://doi.org/10.1371%2Fjournal.pcbi.1010752},
year = 2023,
month = {jan},
publisher = {Public Library of Science ({PLoS})},
volume = {19},
number = {1},
pages = {e1010752},
author = {Saskia Hiltemann and Helena Rasche and Simon Gladman and Hans-Rudolf Hotz and Delphine Larivi{\`{e}}re and Daniel Blankenberg and Pratik D. Jagtap and Thomas Wollmann and Anthony Bretaudeau and Nadia Gou{\'{e}} and Timothy J. Griffin and Coline Royaux and Yvan Le Bras and Subina Mehta and Anna Syme and Frederik Coppens and Bert Droesbeke and Nicola Soranzo and Wendi Bacon and Fotis Psomopoulos and Crist{\'{o}}bal Gallardo-Alba and John Davis and Melanie Christine Föll and Matthias Fahrner and Maria A. Doyle and Beatriz Serrano-Solano and Anne Claire Fouilloux and Peter van Heusden and Wolfgang Maier and Dave Clements and Florian Heyl and Björn Grüning and B{\'{e}}r{\'{e}}nice Batut and},
editor = {Francis Ouellette},
title = {Galaxy Training: A powerful framework for teaching!},
journal = {PLoS Comput Biol}
}
Riferimenti
Queste persone o organizzazioni hanno fornito supporto finanziario per lo sviluppo di questa risorsa
Domande:


 Open image in new tab
Open image in new tab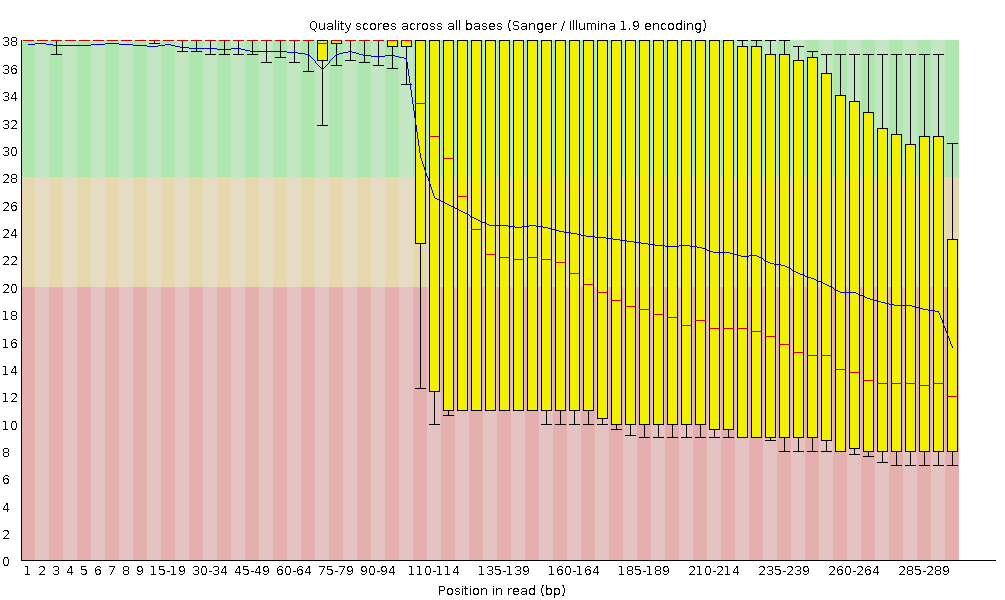 Open image in new tab
Open image in new tab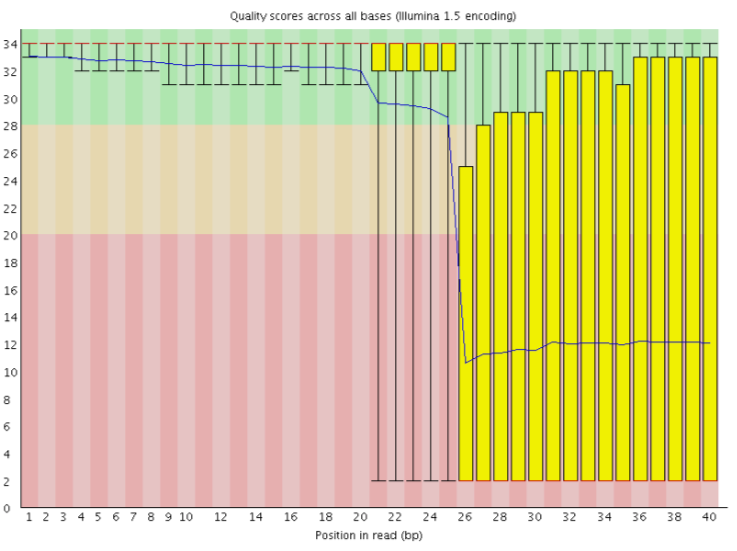
 Open image in new tab
Open image in new tab
 Open image in new tab
Open image in new tab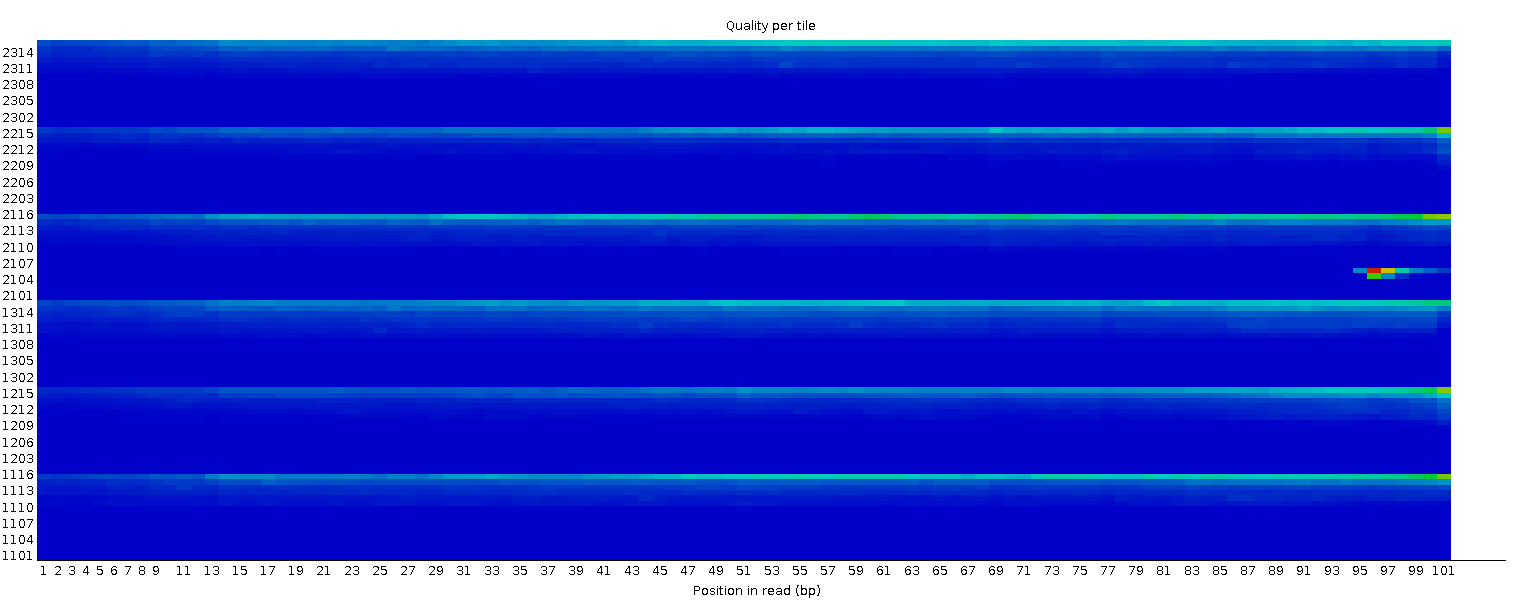
 Open image in new tab
Open image in new tab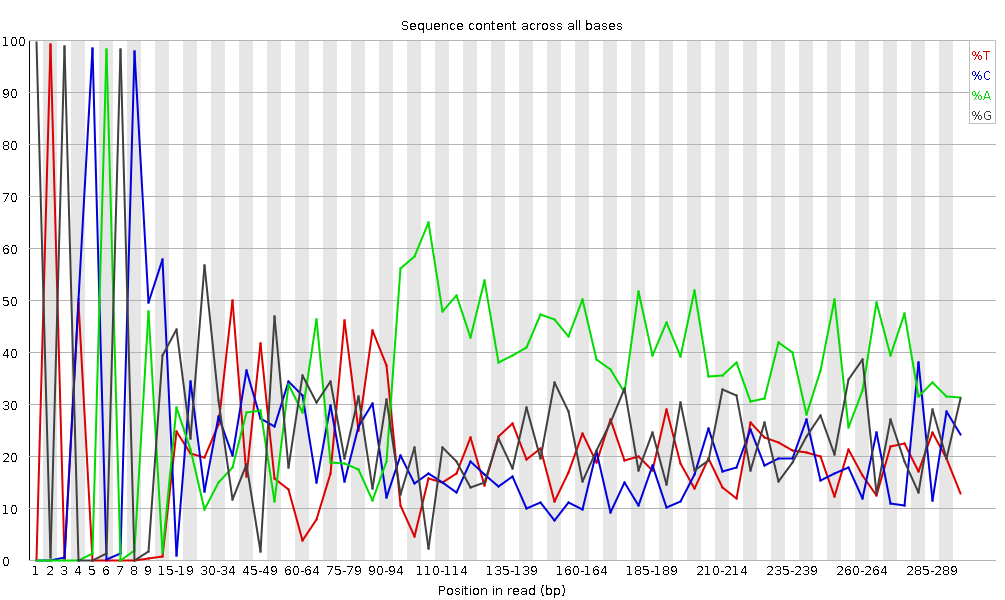 Open image in new tab
Open image in new tab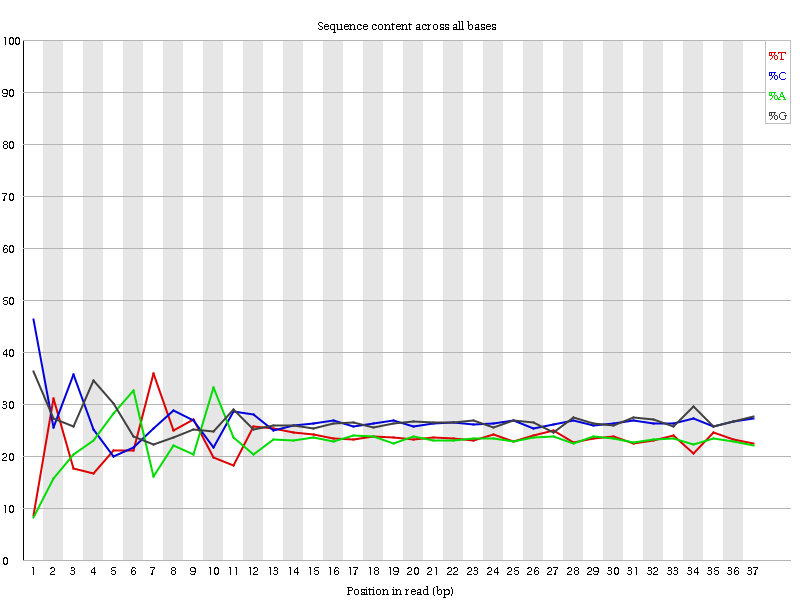
 Open image in new tab
Open image in new tab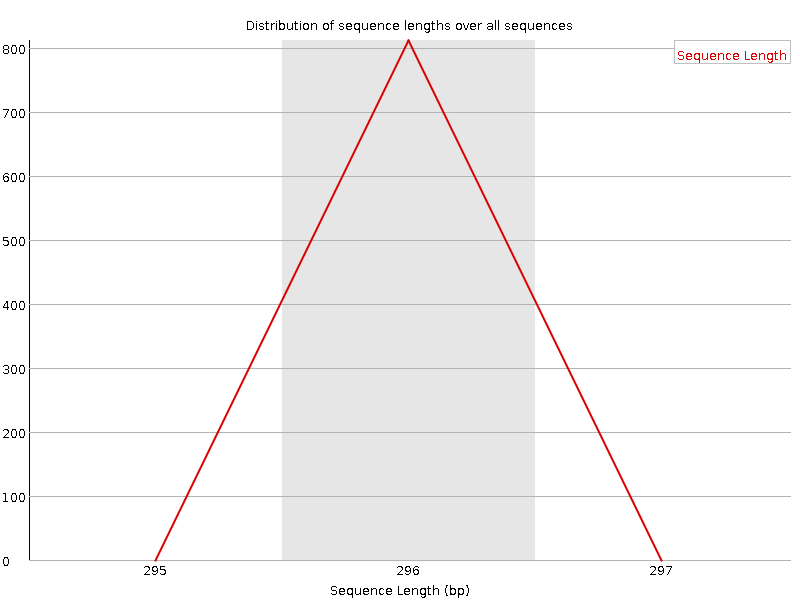 Open image in new tab
Open image in new tab Open image in new tab
Open image in new tab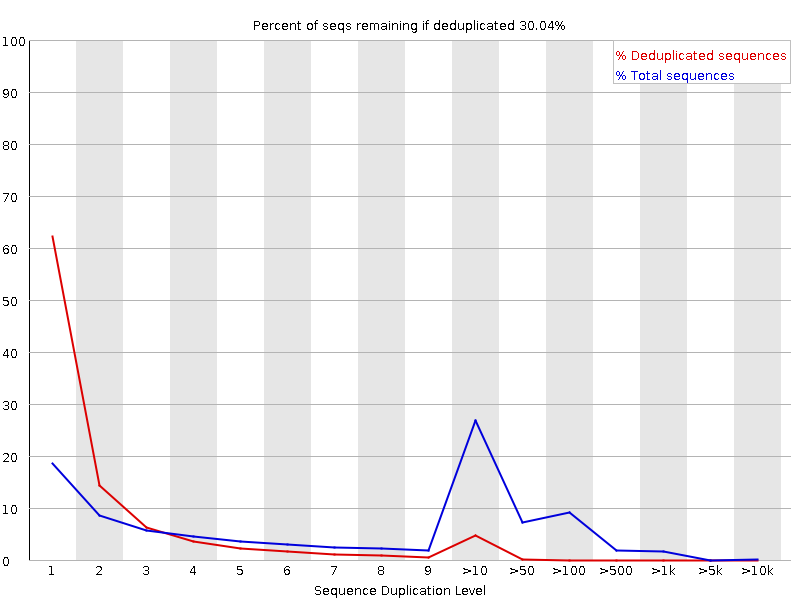
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab
Open image in new tab

Abbiamo alcune strisce rosse perché abbiamo tagliato quelle regioni dalle letture.
Ora abbiamo un picco di alta qualità invece di uno di alta e uno di bassa qualità che avevamo in precedenza.
Non abbiamo una rappresentazione uguale delle basi come prima, poiché si tratta di dati ampliconici.
Ora abbiamo un unico picco GC principale dovuto alla rimozione dell’adattatore.
Questo è lo stesso di prima in quanto non abbiamo N in queste letture.
Ora abbiamo più picchi e una gamma di lunghezze, invece del singolo picco che avevamo prima del trimming quando tutte le sequenze erano della stessa lunghezza.
Open image in new tab
 Open image in new tab
Open image in new tab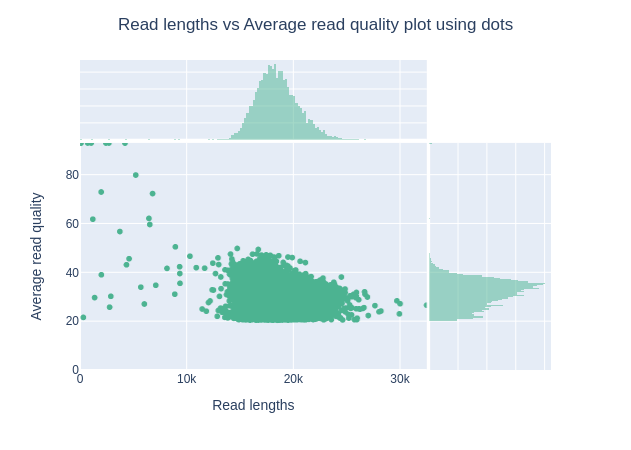 Open image in new tab
Open image in new tabOpen image in new tab
 Open image in new tab
Open image in new tab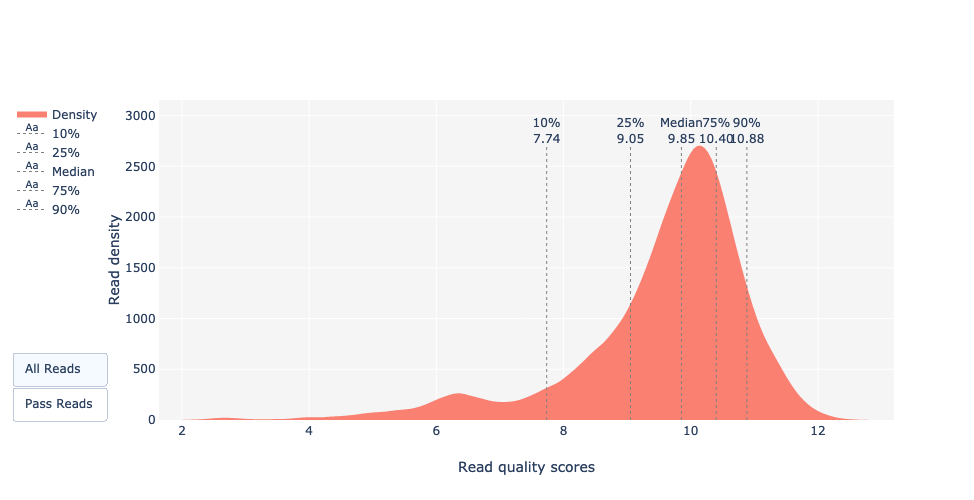 Open image in new tab
Open image in new tab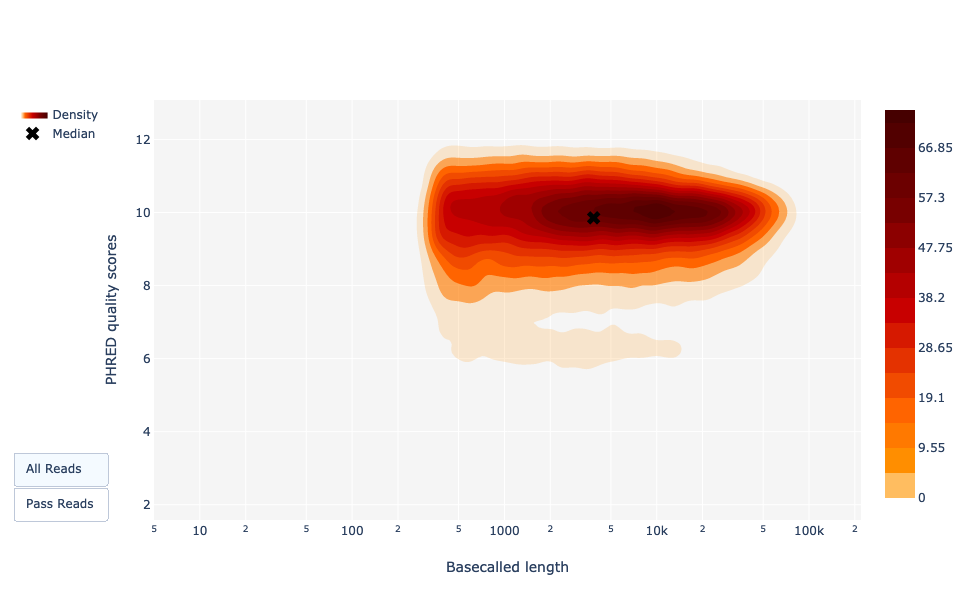 Open image in new tab
Open image in new tab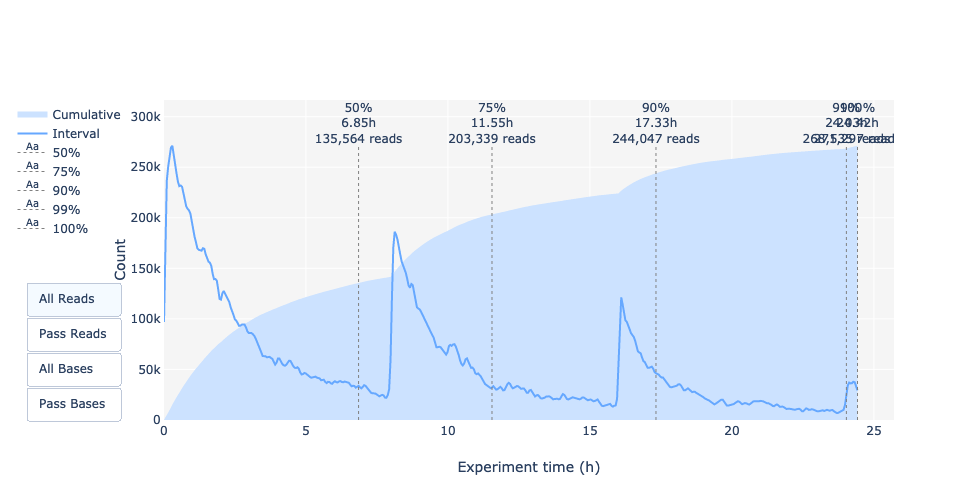 Open image in new tab
Open image in new tab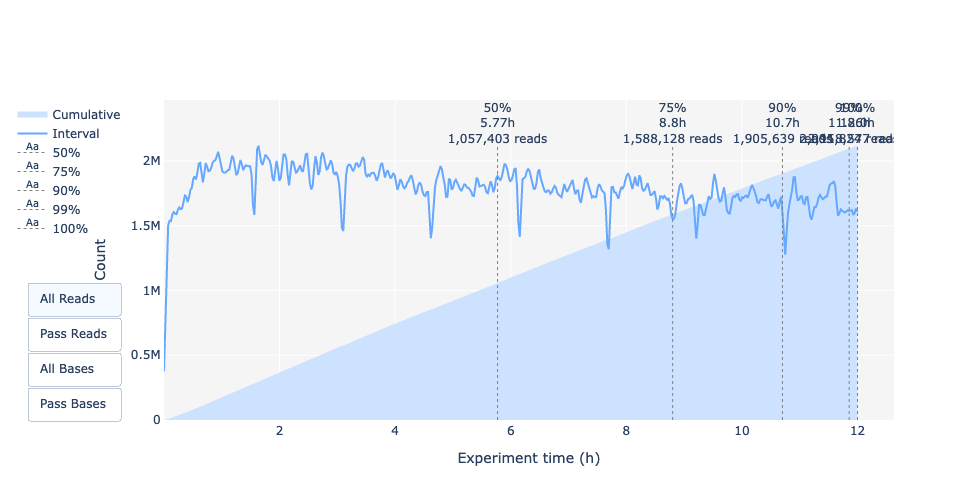
 Open image in new tab
Open image in new tab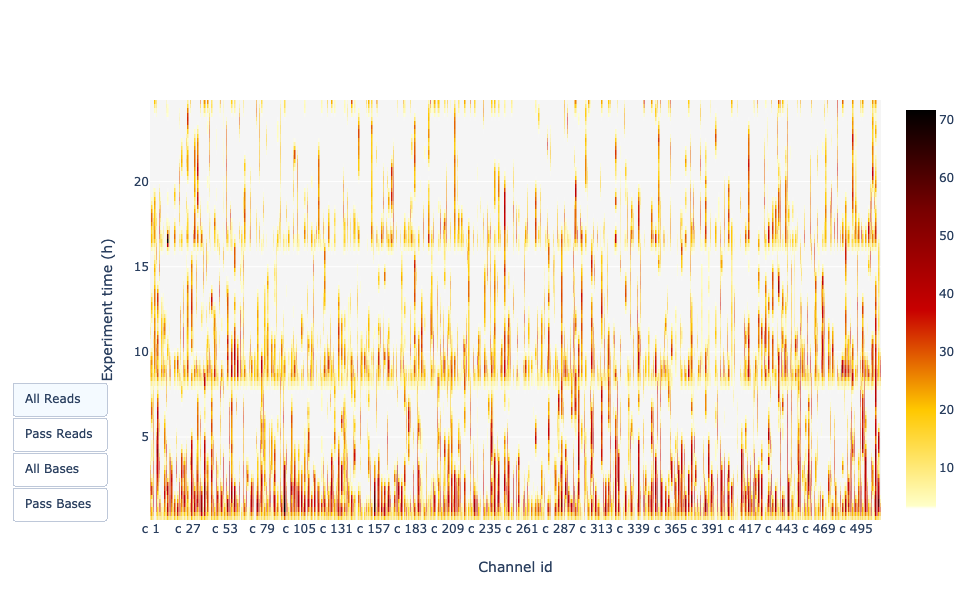 Open image in new tab
Open image in new tab